python学习生涯 day3-5
0 global和nonlocal关键字

注意:global是把该变量声明为全局变量,而nonlocal是把该变量声明为上一级外部函数的局部变量
x = -1
def outer():
x = 0
def inner():
nonlocal x
x = 1
print('inner:', x)
inner()
print('outer:', x)
outer()
print('global:', x)!

x = -1
def outer():
x = 0
def inner():
global x
x = 1
print('inner:', x)
inner()
print('outer:', x)
outer()
print('global:', x)

1 可迭代协议和迭代器协议
可迭代协议:凡是含有__iter__方法的都是可迭代的,(在python中,可迭代的数据类型有字符串,列表,元组,字典,集合,枚举,range等,int和布尔类型不包含__iter__方法)
迭代器协议:凡是含有__iter__和__next__方法的都是迭代器
For循环的实质就是在调用__next__方法
l = [1, 2, ‘8hjg’, 0]
for i in l:
pass
‘’’
for循环的实质为:
- iterator = l.iter()#可迭代的数据类型使用__iter__方法后,就返回了一个迭代器
- iterator.next()#对于迭代器使用__next__方法后,相当于从迭代器中一个一个取值
- 当出现false后,执行结束
‘’’
迭代器的优势:
a)迭代器中的值会一个一个的被取出
b)节省内存空间,循环一次产生一个变量,而不是一次性全部产生
尤其是对于文件句柄和range()而言,特别节省内存空间
2生成器
生成器的本质还是迭代器,凡是含有yield关键字的函数都是生成器函数
0)yield不能与return混用,且必须写在函数内部
1)生成器函数在被执行后会返回一个生成器作为返回值 ,而函数内部的语句并不会被执行
2)一个简单的生成器函数的例子

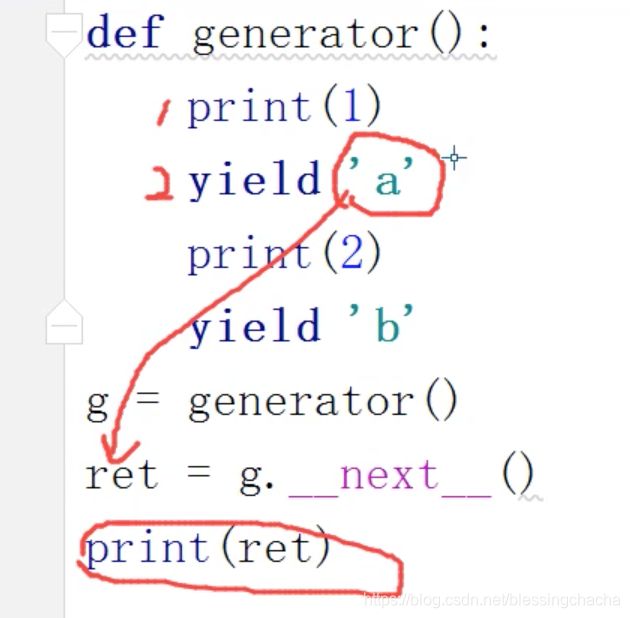
打印结果如下图:

简单介绍一下return和yield的区别吧:
当一个程序执行到return时,程序结束,return之后的语句不会再执行,换句话说,return就是程序结束的标志,而yield不会引起程序结束,当程序运行到yield时,相当于暂停了,如果下一次又调用函数,需要执行yield时,接着上次暂停的地方继续执行(不知道这么理解对不对)
我个人喜欢用一些生活中的例子来进行类比:
执行程序相当于在跑马拉松,当出现return时,相当于选手退出比赛,当出现yield时,相当于选手暂停休息了一会,当生成器函数被再次调用时,选手又接着上次暂停的地方继续开始跑,直到出现下一个yield
说到跑步的例子,我就不得不再说一下break和continue的区别了:
这也不能说是我思维混乱,只能说思维比较跳跃吧
由于break和continue一般是在循环中使用的,所以类比成在操场跑圈吧
break相当于选手直接退赛,不再参与跑圈这一运动,而continue相当于选手放弃了这圈中没有跑完的这一部分,直接从下一圈的起点开始跑
3 生成器进阶知识
0)一个实例:
def genreatoion():
print(123)
count = yield 1
print('=====', count)
yield 2
g = genreatoion()
ret = g.__next__()
print(ret)
ret = g.send('hello')
print(ret)
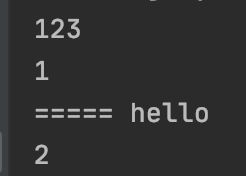
我们注意到,在上面这段代码中,我们使用了send方法,而且不同于之前的yield形式,我们对yield进行了一个赋值,
注意:# send和__next__功能相似,send在获取下一个值的时候,将上一个yield位置赋值给一个变量
使用send的两个注意点:
第一次使用生成器函数时,必须先使用__next__函数,因为send要获取上一个yield位置,经过验证,可以用send(None)来代替 # 最后一个yield不接受外部的值
1)一个移动平均值的例子:
def average():
ave = 0
sum = 0
count = 0
while True:
num = yield ave
sum += num
count += 1
ave = sum/count
g = average()
g.__next__()
ave1 = g.send(10)
ave1 = g.send(20)
print(ave1)
这个代码虽然很简单,但是在while中,num = yield ave这条语句的位置很重要,如果这条语句放在循环的最后一句,执行就会出现错误,因为num没有被定义
2)我们也可以把g.__next__这条语句放在装饰器中
def init(func):
def inner(*args, **kwargs):
ret1 = func(*args, **kwargs)
ret1.__next__()
return ret1
return inner
@init#init = init(average)
def average():
ave = 0
sum = 0
count = 0
while True:
num = yield ave
sum += num
count += 1
ave = sum/count
g = average()
ave1 = g.send(10)
ave1 = g.send(20)
print(ave1)
这段代码相当于装饰器和生成器进阶的融合,一定要好好理解
4yield from 语句
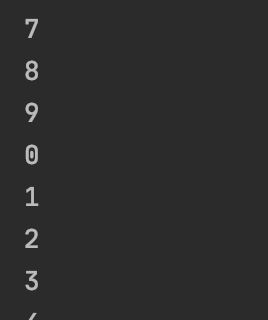
0)在python2中,如果要逐个获取字符串中每一个变量,只能使用如下方式
def geration():
a = '67890'
b = '12345'
for i in a:
yield I
for i in b:
yield i
g = geration()
for i in g:
print(i)
1) 在python3中,更新了yield from语句,它的使用如下;
def geration():
a = '67890'
b = '12345'
yield from a
yield from b
g = geration()
for i in g:
print(i)
两种方法的结果都是一样的,所以在今后的学习中,遇到了yield from语句,一定不要惊讶
5 列表推导式和生成器表达式
0)列表推导式
egg_list = ['鸡蛋%d' % i for i in range(10)]
print(egg_list)
![]()
1)生成器表达式
egg_list1 = ('鸡蛋%d' % i for i in range(10))
print(egg_list1)
for i in egg_list1:
print(i)
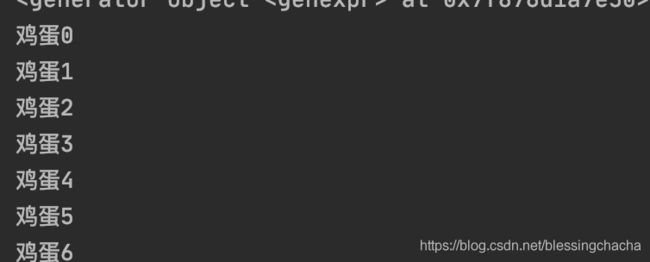
生成器表达式返回的永远是一个生成器,只有对生成器中的每一个元素进行输出,才能达到我们想要的效果
两者的区别:
0)列表推导式使用的是[] 而生成器表达式使用的是()
1) 与列表推导式相比较,生成器表达式几乎不占用内存
因为它一次取一个,而列表推导式一次全部都取出来了
2)生成器表达式返回的是一个生成器,这也是最关键的一点
6 各种列表推导式
0)30以内能被3整除的数的平方
egg_list = [i*i for i in range(30) if i % 3 == 0]
print(egg_list)
注意:一个完整的列表推导式要有if,if的作用相当去筛选,没有if相当于遍历
![]()
1)嵌套列表中,e出现2次的名字
先for大列表再for小列表
7 字典推导式
0)将字典的key和value对调
mask = {
'a': 10, 'b': 20}
antimask = {
mask[k]: k for k in mask}
print(antimask)

这里简单介绍一下什么是可哈希的,什么是不可哈希的?
不严谨但易懂的解释:
一个对象在其生命周期内,如果保持不变,就是hashable(可哈希的)。
hashable ≈ imutable 可哈希 ≈ 不可变
在Python中:
list、set和dictionary 都是可改变的,比如可以通过list.append(),set.remove(),dict[‘key’] = value对其进行修改,所以它们都是不可哈希的;
而tuple和string是不可变的,只可以做复制或者切片等操作,所以它们就是可哈希的。
总结一下,可哈希的数据类型有元组,字符串,以及字典的键
8 集合推导式
0)寻找集合中每一个元素的平方
suqrat = {
i*i for i in [1, -1, 2]}
print(suqrat)
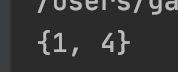
注意:集合本身具有去重功能
为什么没有元组推导式呢?其实这是一个很有趣的问题!!!
我在最后会公布答案
9 直接赋值,浅拷贝和深拷贝
直接赋值:相当于给原对象新贴了一个标签
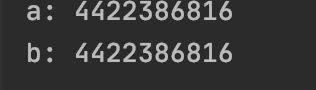
a = 1
b = a
print('a:', id(a))
print('b:', id(b))

浅拷贝:a 和 b 是独立的对象,但他们的子对象还是指向统一对象(是引用)。
使用浅拷贝和深拷贝时,需要引入copy模块,即要在开始前加上import copy
import copy
a = [1, {
1, 2, 3}]
b = copy.copy(a)
a.append(2)
print(a, b)
a[1].add(4)
print(a, b)


深拷贝:a和b是独立的对象,他们的子对象也是独立的对象
import copy
a = [1, {
1, 2, 3}]
b = copy.deepcopy(a)
a.append(2)
print(a, b)
a[1].add(4)
print(a, b)


有人把直接赋值比喻成:旧瓶装旧酒;浅拷贝比喻成:新瓶装旧酒;深拷贝比喻成:新瓶装新酒,我觉得很有意思
知道为什么没有元组推导式吗?
因为
因为元组的符号是(),这个符号已经被生成器表达式用了,哈哈哈!