多标签分类(八):Attention-Driven Dynamic Graph Convolutional Network for Multi-Label Image Recognition
注意力驱动的动态图形卷积网络用于多标签图像识别
摘要
近年来,为了提高多标签图像的识别精度,研究中经常使用图卷积网络(GCN)来建模标签依赖关系。但是,通过计算训练数据的标签共现可能性来构造图可能会降低模型的通用性,特别是当测试图像中存在偶然的共现对象时。我们的目标是消除这种偏差并增强学习特征的鲁棒性。 为此,我们提出了一种注意力驱动动态图卷积网络(ADD-GCN),可以为每个图像动态生成特定图。ADD-GCN采用动态图卷积网络(D-GCN)对语义注意模块(SAM)生成的内容感知类别表示的关系进行建模。
介绍
自然场景通常包含多个对象。在计算机视觉领域,多标签图像识别是一项基本的计算机视觉任务,在人类属性识、医学图像识别和推荐系统等广泛应用中发挥着关键作用,与单标签分类不同,多标签图像识别需要将多个标签分配给单个图像。 因此,有必要考虑不同标签之间的关系以提高识别性能。
近年来,图卷积网络(GCN)在图顶点之间的关系建模方面取得了很大的成功。目前最先进的方法利用目标数据集的标签共现先验频率建立一个完整的图来建模每两类之间的标签相关性,取得了显著的效果。然而,为整个数据集构建这样的全局图可能会导致大多数常见数据集出现频率偏差问题。尽管创建者尽了最大的努力,但大多数杰出的视觉数据集还是遭受了同时发生的频率偏差的困扰。 让我们考虑一个共同的类别“汽车”,它总是与诸如“卡车”,“摩托车”和“公共汽车”之类的不同类型的车辆一起出现。这可能会无意中导致这些数据集的频率偏差,从而引导模型学习它们之间的更高的关系。具体来说,如图1(a)所示,每个图像共享一个静态图,该静态图是通过计算目标数据集中类别的共现频率而构建的。在每个图像中,静态图给出的“汽车”和“卡车”之间的关系值较高,而“汽车”和“厕所”之间的关系值较低。这可能会导致以下几个问题:1)在不同的情况下(例如在没有“卡车”的情况下)无法识别“汽车”,2)即使在只有“汽车”的场景中也会产生“卡车”的幻觉和 3)当“汽车”与“厕所”同时出现时,忽略“厕所”。

图1表示静态图和动态图。实线表示类别之间的关系较高,虚线表示类别之间的关系较低。(a)说明所有图像共享一个静态图。(b)显示了我们的动机,不同的图像有自己的图,可以描述图像中共发生的范畴之间的关系。 可以看到,在静态图当中,哪怕图片中只存在小汽车,也很可能将卡车也预测出来,所以基于全局的静态图很可能每一次都将关系较高的标签预测出来
考虑到这些问题,我们的目标是构建一个动态图,以捕捉每个图像的可感知内容的类别关系。具体来说,如图1(b)所示,我们构造了图像特定的动态图,其中“汽车”和“厕所”与“汽车”和“厕所”一起出现的图像具有很强的联系。 反之亦然。为此,我们提出了一种用于多标签图像识别的注意力驱动动态图卷积网络(ADD-GCN),它利用内容感知的类别表示来构造动态图表示,与以前的基于图的方法不同,ADD-GCN通过估计图像特定的动态图为每个输入图像建模语义关系。具体来说,我们首先通过语义注意模块(SAM)将卷积特征图分解为多个内容感知的类别表示形式,然后将这些表示形式输入到动态GCN (D-GCN)模块中,该模块通过静态图和动态图两种联合图进行特征传播。最终,由D-GCN生成用于多标记分类的区分性载体。 静态图主要捕获训练数据集上的粗标签依赖关系,并学习如图1(a)所示的语义关系。动态图的相关矩阵是应用于每个图像的内容感知类别表示的轻量级网络的输出特征图,并用于捕获这些内容感知类别表示的细微依赖关系,如图1(b)所示。
我们的主要贡献可以总结如下:
∙ \bullet ∙ 本文的主要贡献在于,我们介绍了一种基于内容感知类别表示构造的新颖动态图,用于多标签图像识别。 动态图能够以自适应方式捕获特定图像的类别关系,从而进一步增强了其代表性和判别能力。
∙ \bullet ∙ 我们精心设计了一个端到端注意力驱动动态图卷积网络(ADD-GCN),该网络由两个联合模块组成。 i)语义注意模块(SAM),用于定位语义区域并为每个图像生成内容感知的类别表示;以及ii)动态图卷积网络(D-GCN),用于对内容感知的类别表示的关系进行建模以进行最终分类。
3.方法
本节介绍了用于多标签图像识别的注意力驱动动态图卷积网络(ADD-GCN)。 我们首先简要介绍ADD-GCN,然后详细描述其关键模块(语义注意模块和动态GCN模块)。
3.1 ADD-GCN概述
图像中的目标总是同时出现在图像中,如何有效地捕捉它们之间的关系是多标记识别的一个重要问题。基于图的表示方法为标签相关性建模提供了一种实用的方法。我们可以用节点 V = [ v 1 , v 2 , . . . v C ] V = [v_1,v_2,...v_C] V=[v1,v2,...vC]表示标签,相关矩阵 A A A表示标签关系(边).最近的研究利用图卷积网络(GCN)来提高多标签图像识别的性能。但是,它们以静态方式构造相关矩阵A,该矩阵主要考虑训练数据集中的标签共现,并针对每个输入图像进行固定。 结果,他们无法明确利用每个特定输入图像的内容
为了解决这个问题,本文提出了具有两个精心设计的模块的ADD-GCN:我们首先引入语义注意模块(SAM),以从提取的特征图中估计每个类 c c c的内容感知类别表示 v c v_c vc,并将表示输入到另一个动态GCN模块,用于最终分类。 我们将在下一部分中详细介绍它们。
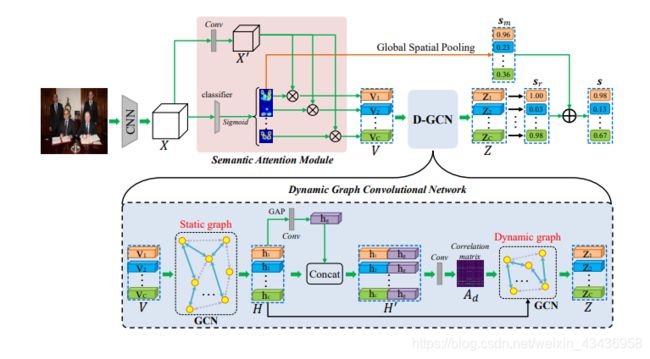
图2表示了我们方法的总体框架。给定一个图像,ADD-GCN首先使用一个CNN骨干提取卷积特征图 X X X,然后SAM将 X X X解耦为可感知内容的类别表示 V V V, D − G C N D-GCN D−GCN对 V V V之间的全局和局部关系建模,以生成最终的健壮表示 Z Z Z,该 Z Z Z包含与其他类别的丰富关系信息
3.2 语义注意模块
语义注意模块(SAM)的目的是获得一组内容感知的类别表示,每个类别表示都会从输入特征图 X ∈ R H × W × D X∈\mathbb{R}^{H×W×D} X∈RH×W×D中描述与特定标签有关的内容。如图2所示,SAM首先计算特定类别的激活映射 M = [ m 1 , m 2 , . . . , m C ] ∈ R H × W × C M=[m_1,m_2,...,m_C]∈\mathbb{R}^{H×W×C} M=[m1,m2,...,mC]∈RH×W×C,然后使用它们将转换后的特征映射 X ′ ∈ R H × W × D ′ X'∈\mathbb{R}^{H×W×D'} X′∈RH×W×D′转换为可感知内容的类别表示 V = [ v 1 , v 2 , . . . , v C ] ∈ R C × D V=[v_1,v_2,...,v_C]∈\mathbb{R}^{C×D} V=[v1,v2,...,vC]∈RC×D.具体来说,每个类的表示 v c v_c vc被表述为对 X ′ X' X′的加权和(如下所示),这样产生的 v c v_c vc可以有选择地聚合与其特定类别 c c c相关的特征:
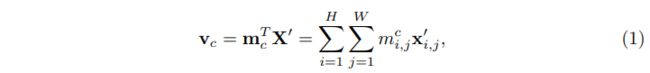
其中 m i , j c m_{i,j}^c mi,jc和 x i , j ′ ∈ R D ′ x'_{i,j}∈\mathbb{R}^{D'} xi,j′∈RD′分别表示为第 c c c个激活映射的权值,在特征图 ( i , j ) (i, j) (i,j)处的特征向量。然后问题就变成了如何计算特定类别的激活映射 M M M,难点在于我们没有明确的监督,比如对图像的边框或者分类分割
激活图生成:我们基于类激活映射(CAM)生成特定类别的激活映射M,该类激活映射是一种不需要边框和分割就能将隐含注意力暴露在图像上的技术.具体来说,我们可以在特征图 X X X上执行全局平均池化(GAP)或全局最大池化(GMP),并使用FC分类器对这些池化的特征进行分类,然后,通过将FC分类器的权重与特征图 X X X进行卷积,将这些分类器用于识别类别特定的激活图。与CAM不同的是,我们使用卷积层作为分类器,并在全局空间池前使用 S i g m o i d ( ⋅ ) Sigmoid(·) Sigmoid(⋅)对 M M M进行规整,在实验中具有更好的性能。
3.3 动态GCN
利用上节得到的内容感知类别表示 V V V,引入动态GCN (D-GCN)自适应地变换它们的相干相关性,用于多标签识别.最近图卷积网络(GCN)已被广泛证明可在多种计算机视觉任务中有效,并且已被应用于静态图识别多标签图像的模型标签依赖关系.与这些研究不同的是,我们提出了一个新的D-GCN来充分利用内容感知的类别表示之间的关系来生成判别向量来最终分类.具体来说,我们的D-GCN由两个图形表示形式组成,即静态图和动态图,如图2所示。我们首先回顾传统的GCN,然后详细介绍D-GCN
传统 GCN:给定一组特征 V ∈ R C × D V∈\mathbb{R}^{C×D} V∈RC×D作为输入节点,GCN的目标是利用相关矩阵 A ∈ R C × C A∈\mathbb{R}^{C×C} A∈RC×C和状态更新权矩阵 W ∈ R D × D u W∈\mathbb{R}^{D×D_u} W∈RD×Du来更新 V V V的值.在形式上,更新后的节点 V u ∈ R C × D u V_u∈\mathbb{R}^{C×D_u} Vu∈RC×Du可以用单层GCN表示为:

其中 A A A通常是预定义的, W W W是在训练中学习的。 δ ( ⋅ ) δ(·) δ(⋅)表示激活函数,如 R e L U ( ⋅ ) ReLU(·) ReLU(⋅)或 S i g m o i d ( ⋅ ) Sigmoid(·) Sigmoid(⋅),使整个操作非线性,相关矩阵 A A A反映了各节点特征之间的关系.在推理过程中,关联矩阵 A A A首先将相关信息扩散到所有节点,然后每个节点接收到所有必要的信息,并通过线性变换 W W W更新其状态.
D-GCN:如图2底部所示,D-GCN将可感知内容的类别表示 V V V作为输入节点特征,并按顺序将它们提供给静态GCN和动态GCN.具体来说,单层静态GCN简单定义为 H = L R e L U ( A s V W s ) H = LReLU(A_sVW_s) H=LReLU(AsVWs),其中 H = [ h 1 , h 2 , . . . , h C ] ∈ R C × D 1 H = [h_1,h_2,...,h_C]∈\mathbb{R}^{C×D_1} H=[h1,h2,...,hC]∈RC×D1,激活函数 L R e L U ( ⋅ ) LReLU(·) LReLU(⋅)为 L e a k y R e L U LeakyReLU LeakyReLU,在训练过程中,通过梯度下降法随机初始化相关矩阵 A s A_s As和状态更新权值 W W W,由于 A s A_s As对所有图像都是共享的,所以期望 A s A_s As能够捕获全局粗分类依赖关系.
然后引入动态GCN对 H H H进行变换,并根据输入特征 H H H自适应估计其相关矩阵 A d A_d Ad,注意,这与静态GCN不同,静态GCN的相关矩阵是固定的,经过训练后对所有输入样本都是共享的,而我们的 A d A_d Ad是根据输入特征动态构造的.由于每个样本具有不同的 A d A_d Ad,使得模型提高了其代表性能力,降低了静态图带来的过拟合风险.在形式上,动态GCN的输出 Z ∈ R C × D 2 Z∈\mathbb{R}^{C×D_2} Z∈RC×D2可以定义为:
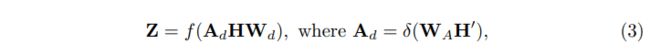
其中, f ( ⋅ ) f(·) f(⋅)是LeakyReLU激活函数,而 δ ( ⋅ ) δ(·) δ(⋅)是Sigmoid激活函数, W d ∈ R D 1 × D 2 W_d∈\mathbb{R}^{D_1×D_2} Wd∈RD1×D2为状态更新权值, W A ∈ R C × 2 D 1 W_A∈\mathbb{R}^{C×2D_1} WA∈RC×2D1是构造动态关联矩阵 A d A_d Ad的conv卷积层的权值。 H ′ ∈ R 2 D 1 × C H'∈\mathbb{R}^{2D_1×C} H′∈R2D1×C由 H H H及其全局表示 h g ∈ R D 1 h_g ∈R^{D_1} hg∈RD1串联得到, h g ∈ R D 1 h_g ∈R^{D_1} hg∈RD1由全局平均池和一层conv层串联得到,形式上, H ′ H' H′定义为:
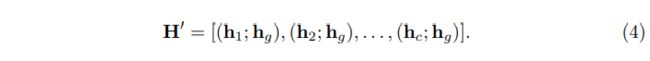
值得一提的是,动态图 A d A_d Ad是特定于每个图像的,可能会捕获与内容相关的类别依赖关系。总的来说,我们的DGCN通过特定于数据的图和特定于图像的图增强了从 V V V到 Z Z Z的可感知内容的类别表示
3.4 最终分类和损失
最终的分类:如图2所示,最终类别表示 Z = [ z 1 , z 2 , … , z C ] Z = [z_1, z_2,…, z_C] Z=[z1,z2,…,zC]用于最终分类,由于每个向量 z i z_i zi都是与其特定类对齐的,并且包含了与其他向量丰富的关系信息,我们只需将每个类别向量放入一个二值分类器中就可以预测其类别得分,特别地,我们将每个类别的分数连接起来,以生成最终的分数向量 s r = [ s r 1 , s r 2 , . . . , s r C ] s_r=[s^1_r,s^2_r,...,s^C_r] sr=[sr1,sr2,...,srC],此外,我们还可以通过SAM在3.2节中估计的类别特定的激活图 M M M上的全局空间合并来获得另一个可信度分数 s m = [ s m 1 , s m 2 , . . . , s m C ] s_m=[s^1_m,s^2_m,...,s^C_m] sm=[sm1,sm2,...,smC],因此,我们可以将这两个得分向量组合起来,预测更可靠的结果。这里,我们只是简单地将它们平均,从而得到最终分数 s = [ s 1 , s 2 , . . . , s C ] s = [s^1, s^2,...,s^C] s=[s1,s2,...,sC]。
训练损失:我们对最终分数 s s s进行监督,并采用传统的多标签失分方法对整个ADD-GCN进行如下训练
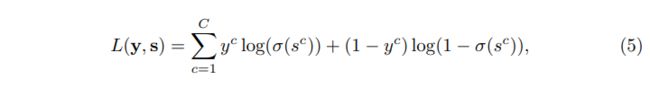
4.实验
4.1实验细节
对于整个ADD-GCN框架,我们使用ResNet-101作为骨干。我们的SAM和D-GCN采用了斜率为负0.2的非线性激活函数LeakyReLU,在训练时,我们采用了数据增强来避免过拟合:对输入图像进行随机裁剪,调整大小为448×448,随机水平翻转来进行数据增强。我们选择SGD作为优化器,其动量为0.9,重量衰减为 1 0 − 4 10^{-4} 10−4,每个GPU的批处理大小为18。SAM/D-GCN初始学习率设置为0.5,骨干CNN设置为0.05,我们总共训练了50个epoch,在30和40个epoch时,学习率分别降低了0.1倍,在测试期间,我们简单地将输入图像的大小调整为512×512以进行评估。所有实验都是基于PyTorch实现的.

4.4 消融实验
静态图形vs动态图形:研究了静态图和动态图在D-GCN中的作用。结果如表4所示.首先,我们研究了只有一个图的情况。静态图和动态图的性能都优于基线ResNet-101,动态图在MS-COCO和VOC 2007上的性能都优于基线ResNet-101,结果表明,在整个数据集上,建模局部(即图像级)分类感知依赖比粗糙标签依赖更有效。为了进一步探究静态图与动态图是否互补,我们尝试以不同的方式组合它们,如表4所示.S表示静态图,D表示动态图,P表示通过静态图和动态图并行传播信息,通过加法(add)或元素乘(mul)或连接(cat)将其融合。结果表明,在所有设置中, S → D S→D S→D的性能最好

4.5可视化
在本节中,我们分别以类别特异性激活图和动态关联矩阵 A d A_d Ad的例子来说明SAM是否能够定位语义目标,以及动态图学到了什么关系
特定类别激活映射的可视化:我们使用相应的特定类别激活映射来可视化原始图像,以说明使用SAM模块捕获图像中出现的每个类别的语义区域的能力.一些例子如图4所示,每一行都是原始图像,对应的特定类别的激活映射以及每个类别的最终得分.对于图像中出现的类别,我们观察到我们的模型能够准确地定位它们的语义区域。相比之下,激活映射对图像不包含的类别的激活率较低.例如,第二行有person、tie和chair的标签,我们的ADD-GCN可以准确地突出显示这三个类的相关语义区域。最后的结果表明,分类意识表征具有足够的可识别性,能够被准确地识别:

动态图可视化:如图5所示,我们将原始图像与其对应的动态相关矩阵 A d A_d Ad进行可视化,以说明D-GCN学到了什么关系。对于图5(a)中的输入图像,其ground truth为“car”、“dog”和“person”。图5(b)为输入图像 A d A_d Ad的可视化图,我们可以发现, A d c a r ; d o g A^{car;dog}_d Adcar;dog和 A d c a r , p e r s o n A^{car, person}_d Adcar,person在“car”一列中排名最靠前(大约前10%)。这意味着“狗”和“人”与图像中的“车”更相关。类似的结果也可以在“狗”和“人”这两行中找到。从动态图的可视化观察,我们可以相信D-GCN能够捕捉到特定输入图像的这种语义关系。
