原文3年多前发表在私人站点,现迁移到
这篇文章基本是对《Web性能权威指南》第一章和第二章的读书笔记,另外加一些扩展内容,这本书确实赞,推荐
一、高带宽和低延迟
所有网络通信都有决定性影响的两个方面:延迟和带宽
- 延迟 分组从信息源发送到目的地所需的时间。
- 带宽 逻辑或物理通信路径最大的吞吐量

延迟的因素
- 传播延迟(速度延迟) 消息从发送端到接收端需要的时间(不超过光速)
- 传输延迟(带宽/窗口) 把消息中的所有比特转移到链路中需要的时间,是消息长度和链路速率的函数(10M/s和1M/s的线路,时间不一样)
- 处理延迟 处理分组首部、检查位错误及确定分组目标所需的时间(路由器分包)
- 排队延迟 到来的分组排队等待处理的时间
速度延时
假定光通过光纤的速度 约为每秒 200 000 000 米,对应的折射率约为 1.5,从纽约到悉尼的一个往返(RTT)也要花 160 ms,分组旅行的距离比这要长得多。这条线路中的 每一跳都会涉及寻路、处理、排队和传输延迟。结果,纽约到悉尼的实际 RTT, 大约在 200~300 ms 之间。
中美骨干网单向数据延时≈60ms,所以中国用户访问美国主机数据传输的延时理论值高于120ms(RTT)
带宽延时
核心数据路径的骨干或光纤连接,每秒能够处理数百太比特信息,比如中美之间的海底光纤。光纤就是一根“光导管”,传送光信号。金属线则用于传送电信号,但信号损失、电磁干扰较大,同时维护成本也较高。
通过波分复用(WDM,Wavelength-Division Multiplexing)技术,光纤可以同时传输很多不同波长(信道)的光,2010年初,研究人员已经可以在每个信道中耦合400多种波长的光线,最大容量可达171Gbit/s,而一条光纤的总带宽能够达到70Tbit/s
最后一公里延时-tracerouter
骨干线路可以有TB的带宽,但是网络边缘的容量就小得多了,而且很大程度上取决于部署技术,比如拔号连接、 DSL、电缆、各种无线技术、光纤到户。akamai每季度都会发布全球的带宽报告
通过tracerouter工具,可以查看路由拓扑,最后一公里的延迟与提供商、部署方法、网络拓扑,甚至一天中的哪个时段都有很 大关系。作为最终用户,如果你想提高自己上网的速度,那选择延迟最短的ISP是最关键的
Traceroute sends out three packets per TTL increment. Each column corresponds to the
time is took to get one packet back (round-trip-time).
traceroute to xx.com (121.41.167.43), 30 hops max, 60 byte packets
1 198.11.175.248 (198.11.175.248) 0.879 ms 0.898 ms 0.950 ms
2 10.107.64.14 (10.107.64.14) 0.945 ms 10.107.64.22 (10.107.64.22) 1.033 ms 10.107.64.18 (10.107.64.18) 75.379 ms
3 198.11.128.162 (198.11.128.162) 135.636 ms 198.11.128.154 (198.11.128.154) 0.913 ms 198.11.128.178 (198.11.128.178) 5.472 ms
4 218.30.53.93 (218.30.53.93) 4.542 ms 218.30.53.97 (218.30.53.97) 2.144 ms 218.30.53.126 (218.30.53.126) 2.334 ms
5 202.97.51.253 (202.97.51.253) 160.089 ms 160.170 ms 160.077 ms
6 202.97.35.105 (202.97.35.105) 188.541 ms 190.518 ms 188.903 ms
7 202.97.33.37 (202.97.33.37) 168.075 ms 168.109 ms 168.016 ms
8 202.97.55.14 (202.97.55.14) 192.583 ms 192.572 ms 192.591 ms
9 220.191.135.106 (220.191.135.106) 201.476 ms 201.542 ms 201.465 ms
10 115.236.101.209 (115.236.101.209) 211.315 ms 211.305 ms *
11 42.120.244.194 (42.120.244.194) 270.211 ms 42.120.244.178 (42.120.244.178) 163.768 ms 163.700 ms
12 42.120.244.238 (42.120.244.238) 191.543 ms 42.120.244.246 (42.120.244.246) 248.825 ms 248.910 ms
二、高带宽和低延时
高带宽
目前还没有理由认为带宽会停止增长的脚步,就算技术停滞不前,还是可以铺设更多的光缆
低延时
减少延迟相比带宽困难的多,从很多方面来看,我们的基础设施似乎也已经达到了这个极限。这就显得理解和调优网络协议显得特别重要
2.1 TCP三次握手

客户端可以在发送 ACK分组之后立即发送数据,而服务器必须等接收到ACK分组之后才能发送数据。这个启动通信的过程适用于所有 TCP 连接,因此对所有使用TCP的应用具有非常大的性能影响,每次传输应用数据之前,都必须经历一次完整的往返
中美之间一次RTT最低120,假设你发起一个简单的HTTP请求,需要一次握手+一次数据传输 = 240ms,浪费了50%的时间,这种场景下,这也意味着提高TCP应用性能的关键在于想办法重用连接
扩展:TFO(TCP Fast Open,TCP 快速打开)机制,致力于减少新建 TCP 连接带来的性能损失
2.2 流量控制(窗口rwnd)
rwnd是端到端的控制机制,预防发送过多的数据,TCP连接的每一方都会通告自己的接收窗口,其中包含能够保存数据的缓冲区空间大小信息。TCP 连接的整个生命周期:每个 ACK 分组都会携带相应的最新rwnd 值,以便两端动态调整数据流速,使之适应发送端和接收端的容量及处理能力
窗口的值原来只有16位,即65535,所以以前rwnd的最大值不能超过64K。现在基本都有了“TCP 窗口缩放”(TCP Window Scaling),把接收窗口大小由 65 535 字节提高到 1G 字节,在 Linux 中,可以通过如下命 令检查和启用窗口缩放选项:
$> sysctl net.ipv4.tcp_window_scaling
$> sysctl -w net.ipv4.tcp_window_scaling=1
rwnd的设置
如果我们出于传输性能的考虑,当然这个值设置的越大越好,Linux中通过配置内核参数里接收缓冲的大小,进而可以控制接收窗口的大小:
shell> sysctl -a | grep mem
net.ipv4.tcp_rmem =
还有个问题,当大量请求同时到达时,内存会不会爆掉?通常不会,因为Linux本身有一个缓冲大小自动调优的机制,窗口的实际大小会自动在最小值和最大值之间浮动,以期找到性能和资源的平衡点。
通过如下方式可以确认缓冲大小自动调优机制的状态(0:关闭、1:开启):
shell> sysctl -a | grep tcp_moderate_rcvbuf
2.3 慢启动(cwnd,拥塞窗口)
两端流量控制确实可以防止发送端向接收端过多发送数据,但却没有机制预防任何一端向潜在网络过多发送数据。换句话说,发送端和接收端在连接建立之初,谁也不知道可用带宽是多少,因此需要一个估算机制,然后根据网络中不断变化的条件 而动态改变速度:TCP能传输的最大数据 = MIN(rwnd,cwnd)
慢启动的算法如下(cwnd全称Congestion Window):
- 1)连接建好的开始先初始化cwnd = 1,表明可以传一个MSS大小的数据。
- 2)每当收到一个ACK,cwnd++; 呈线性上升
- 3)每当过了一个RTT,cwnd = cwnd*2; 呈指数让升
- 4)还有一个ssthresh(slow start threshold),是一个上限,当cwnd >= ssthresh时,就会进入“拥塞避免算法”(后面会说这个算法)
最初,cwnd 的值只有1个TCP segment。99 年 4 月,RFC 2581 将其增加到了 4 个 TCP segment。2013 年 4 月,RFC 6928 再次将其提高到 10 个 TCP segment
慢启动过程
服务器向客户端发送 4 个 TCP segment,然后就必须停下来等待确认。此后,每收到一个 ACK, 慢启动算法就会告诉服务器可以将它的 cwnd 窗口增加 1 个 TCP segment.这个阶段通常被称为指数增长阶段,因为客户端和服务器都在向两者之间网络路径的有效带宽迅速靠拢

计算达到指定窗口所需要的时间公式:
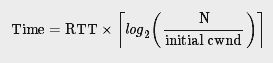
- 客户端和服务器的接收窗口为 65 535 字节(64 KB);
- 初始的拥塞窗口:4 个segment(一个segment 一般是1460B);
- 往返时间是 56 ms(伦敦到纽约)。
为了达到64KB限制,我们将需要把拥塞窗口增加到45个segment,这将花费224毫秒。

慢启动的影响
无论带宽多大,每个 TCP 连接都必须经过慢 启动阶段。换句话说,我们不可能一上来就完全利用连接的最大带宽。
慢启动导致客户端与服务器之间经过几百 ms 才能达到接近最大速度的问题,对于大型流式下载服务的影响不显著,因为慢启动的时间可以分摊到整个传输周期内消化掉。
对于很多 HTTP 连接,特别是一些短暂、突发的连接而言,常常会出现还没 有达到最大窗口请求就被终止的情况。换句话说,很多 Web 应用的性能经常受到服 务器与客户端之间往返时间的制约。因为慢启动限制了可用的吞吐量,而这对于小 文件传输非常不利。
慢启动对HTTP影响的一次计算
假设通过HTTP传输一个20K的文件,初始条件:
- 往返时间:56 ms。
- 客户端到服务器的带宽:5 Mbit/s。
- 客户端和服务器接收窗口:65 535 字节。
- 初始的拥塞窗口:4 segment(4×1460 字节 ≈ 5.7 KB)。
- 服务器生成响应的处理时间:40 ms。
- 没有分组丢失、每个分组都要确认、GET 请求只占 1 段。

- 0 ms:客户端发送 SYN 分组开始 TCP 握手。
- 28 ms:服务器响应 SYN-ACK 并指定其 rwnd 大小。
- 56 ms:客户端确认 SYN-ACK,指定其 rwnd 大小,并立即发送 HTTP GET 请求。
8 84 ms:服务器收到 HTTP 请求。 - 124 ms:服务器生成 20 KB 的响应,并发送 4 个 TCP 段(初始 cwnd 大小为 4),
然后等待 ACK。 - 152 ms:客户端收到 4 个段,并分别发送 ACK 确认。
- 180 ms:服务器针对每个 ACK 递增 cwnd,然后发送 8 个 TCP 段。
- 208 ms:客户端接收 8 个段,并分别发送 ACK 确认。
- 236 ms:服务器针对每个 ACK 递增 cwnd,然后发送剩余的 TCP 段。
- 264 ms:客户端收到剩余的 TCP 段,并分别发送 ACK 确认。
作为对比,重用连接,再发一次请求
- 0 ms:客户端发送 HTTP 请求。
- 28 ms:服务器收到 HTTP 请求。
- 68 ms:服务器生成 20 KB 响应,但 cwnd 已经大于发送文件所需的 15 段了,因
此一次性发送所有数据段。 - 96 ms:客户端收到所有 15 个段,分别发送 ACK 确认。
同一个连接、同样的请求,但没有三次握手和慢启动,只花了 96 ms,性能提升幅 度达 275% !
拥塞窗口的合适值
Google在这方面做了大量的研究,权衡了效率和稳定性之后,最终给出的建议是10MSS。如果你的Linux版本不太旧的话,那么可以通过如下方法来调整「cwnd」初始值:
shell> ip route | while read p; do
ip route change $p initcwnd 10;
done
需要提醒的是片面的提升发送端「cwnd」的大小并不一定有效,这是因为前面我们说过网络中实际传输的未经确认的数据大小取决于「rwnd」和「cwnd」中的小值,所以一旦接收方的「rwnd」比较小的话,会阻碍「cwnd」的发挥。
2.4 拥塞预防
拥塞预防算法把丢包作为网络拥塞的标志,即路径中某个连接或路由器已经拥堵了, 以至于必须采取删包措施。因此,必须调整窗口大小,以避免造成更多的包丢失, 从而保证网络畅通。
重置拥塞窗口后,拥塞预防机制按照自己的算法来增大窗口以尽量避免丢包。某个 时刻,可能又会有包丢失,于是这个过程再从头开始。如果你看到过 TCP 连接的吞 吐量跟踪曲线,发现该曲线呈锯齿状,那现在就该明白为什么了。这是拥塞控制和 预防算法在调整拥塞窗口,进而消除网络中的丢包问题。
最初,TCP 使用 AIMD(Multiplicative Decrease and Additive Increase,倍减加增) 算法,即发生丢包时,先将拥塞窗口减半,然后每次往返再缓慢地给窗口增加一 个固定的值。不过,很多时候 AIMD 算法太过保守,因此又有了很多新的算法,比如DSACK:可以让协议知道是什么原因丢包,是重传还是丢失
带宽延迟积
发送端和接收端之间在途未确认的最大数据量,取决于拥塞窗 口(cwnd)和接收窗口(rwnd)的最小值。接收窗口会随每次 ACK 一起发送,而拥塞窗口则由发送端根据拥塞控制和预防算法动态调整.
BDP(Bandwidth-delay product,带宽延迟积)
数据链路的容量与其端到端延迟的乘积。这个结果就是任意时刻处于在途未确认 状态的最大数据量。无论发送端发送的数据还是接收端接收的数据超过了未确认的最大数据量,都必须停 下来等待另一方 ACK 确认某些分组才能继续

那么,流量控制窗口(rwnd)和拥塞控制窗口(cwnd)的值多大合适?实际上,计算过程很简单。首先,假设 cwnd 和 rwnd 的最小值为 16 KB,往返时间为 100 ms:

不管发送端和接收端的实际带宽多大,这个 TCP 连接的数据传输速率不会超过 1.31 Mbit/s !想提高吞吐量,要么增大最小窗口值,要么减少往返时间。窗口至少需要 122.1 KB 才能充分利用 10 Mbit/s 带宽!如果没有“窗口 缩放(RFC 1323)”,TCP 接收窗口最大只有 64 KB
队首阻塞造成的延时
每个 TCP 分组都会带着一个唯一的序列号被发出,而 所有分组必须按顺序传送到接收端。如果中途有一个分组没能到达接收 端,那么后续分组必须保存在接收端的 TCP 缓冲区,等待丢失的分组重发并到达接 收端。这一切都发生在 TCP 层,应用程序对 TCP 重发和缓冲区中排队的分组一无所 知,必须等待分组全部到达才能访问数据。在此之前,应用程序只能在通过套接字 读数据时感觉到延迟交付。这种效应称为 TCP 的队首(HOL,Head of Line)阻塞
队首阻塞造成的延迟可以让我们的应用程序不用关心分组重排和重组,从而让代码 保持简洁。然而,代码简洁也要付出代价,那就是分组到达时间会存在无法预知的 延迟变化。这个时间变化通常被称为抖动
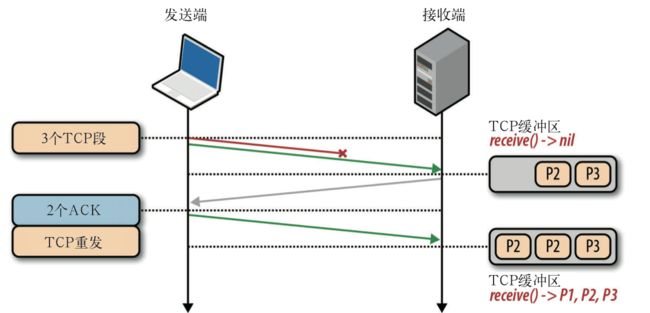
事实上,某些场景下,丢包是让 TCP 达到最佳性能的关键。有些应用程序可以容忍丢失一 定数量的包,比如语音和游戏状态通信,就不需要可靠传输或按序交付
针对TCP的优化建议
每个算法和反馈机制的具体细节可能会继续发展,但核心原理以及 它们的影响是不变的:
- TCP 三次握手增加了整整一次往返时间;
- TCP 慢启动将被应用到每个新连接;
- TCP 流量及拥塞控制会影响所有连接的吞吐量;
- TCP 的吞吐量由当前拥塞窗口大小控制。
结果,现代高速网络中 TCP 连接的数据传输速度,往往会受到接收端和发送端之 间往返时间的限制。另外,尽管带宽不断增长,但延迟依旧受限于光速,而且已经 限定在了其最大值的一个很小的常数因子之内。大多数情况下,TCP 的瓶颈都是延迟,而非带宽
服务器配置调优
增大TCP的初始拥塞窗口
加大起始拥塞窗口可以让 TCP 在第一次往返就传输较多数据,而随后的速度提 升也会很明显。对于突发性的短暂连接,这也是特别关键的一个优化。慢启动重启
在连接空闲时禁用慢启动可以改善瞬时发送数据的长 TCP 连接的性能。窗口缩放(RFC 1323) 启用窗口缩放可以增大最大接收窗口大小,可以让高延迟的连接达到更好吞 吐量。
TCP快速打开
在某些条件下,允许在第一个 SYN 分组中发送应用程序数据。TFO(TCP Fast Open,TCP 快速打开)是一种新的优化选项,需要客户端和服务器共同支持。 为此,首先要搞清楚你的应用程序是否可以利用这个特性。
以上几个设置再加上最新的内核,可以确保最佳性能:每个 TCP 连接都会具有较低 的延迟和较高的吞吐量。
应用程序行为调优
- 再快也快不过什么也不用发送,能少发就少发。
- 我们不能让数据传输得更快,但可以让它们传输的距离更短。
- 重用 TCP 连接是提升性能的关键
性能检查清单
- 把服务器内核升级到最新版本(Linux:3.2+);
- 确保 cwnd 大小为 10;
- 禁用空闲后的慢启动;
- 确保启动窗口缩放;
- 减少传输冗余数据;
- 压缩要传输的数据;
- 把服务器放到离用户近的地方以减少往返时间;
- 尽最大可能重用已经建立的 TCP 连接
参考
- 美国机房及中美网络延时状况
- 浅谈TCP优化(rwnd和cwnd的测量和计算)
- TCP 的那些事儿(上)
- What is the TCP/IP Stack