《现代操作系统(中文第三版)》课后习题——第八章 多处理机系统
第八章 多处理机系统
1.可以把USENET新闻组系统和SETI@home项目看作分布式系统吗? (SETI@home使用数百万台空闲的个人计算机,用来分析无线电频谱数据以搜寻地球之外的智慧生物)。如果是,它们属于图8-1中描述的哪些类?

2.如果一个多处理器中的两个CPU在同一时刻,试图访问内存中同一个字,会发生什么事情?
答:取决于CPU是怎样连接到内存,例如,其中一个CPU会先访问到内存,它占用总线,完成其内存操作后另一个CPU发生才能访问。哪一个CPU首先访问是不可预测的,但如果系统是被设计为顺序一致性的,那这并不重要。
3.如果一个CPU在每条指令中都发出一个内存访问请求,而且计算机的运行速度是200MIPS,那么多少个CPU会使一个400MHz的总线饱和?假设对内存的访问需要一个总线周期。如果在该系统中使用缓存技术,且缓存命中率达到90%,那么多少个CPU会使总线饱和?最后,如果要使32个CPU 共享该总线而且不使其过载,需要多高的命中率?
答:200-MIPS的计算机将发布2亿内存访问请求/秒,占用2亿的总线,即总线容量的一半。所以只需要两个CPU就会使总线饱和。缓存将内存请求数减少到2000万/秒,允许20个CPU共享总线。要使32个CPU 共享该总线,每个CPU需满足不超过1250万个请求/秒。如果2亿内存引用中只有1250万条在总线上出现,则缓存没有命中的概率为12.5 / 200,即6.25%,这意味着命中率为93.75%。
4.在图8-5的omega网络中,假设在交换网络2A和交换网络3B之间的连线断了。那么哪些节点之间的联系被切断了?

5.在图8-7的模型中,信号是如何处理的?

6.使用纯read重写图2-22中的enter_region代码,用以减少由TSL指令所引起的颠簸。
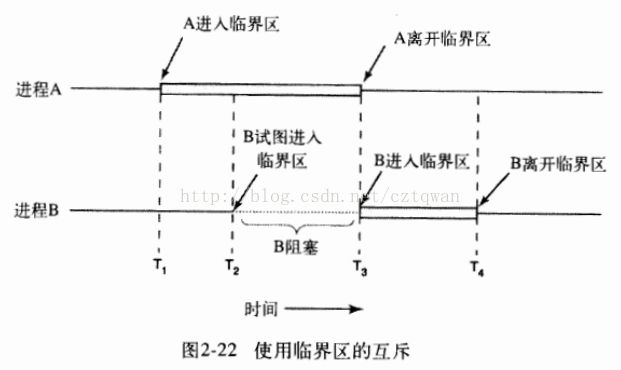

答:给出一个例子:
enter_region:
TST LOCK | Test the value of lock
JNE ENTERREGION | If it is nonzero, go try again
TSL REGISTER,LOCK | Copy lock to register and set lock to 1
CMP REGISTER,#0 | Was lock zero?
JNE ENTERREGION | If it was nonzero, lock was set, so loop
RET | Return to caller; critical region entered
7.多核CPU开始在普通的桌面机和笔记本电脑上出现,拥有数十乃至数百个核的桌面机也为期不远了。利用这些计算能力的一个可能的方式是将标准的桌面应用程序并行化,例如文字处理或者Web浏览器;另一个可能的方式是将操作系统提供的服务(例如TCP操作)和常用的库服务(例如安全http库函数)并行化。你认为哪一种方式更有前途?为什么?
答:如文中所述,人们在编写高度并行的桌面应用程序方面几乎没有经验(和工具)。虽然桌面应用程序有时是多线程的,但线程通常用于简化I/O编程,因此它们不是计算密集型线程。具有大规模并行化的一个桌面应用领域是视频游戏,游戏的许多方面都需要大量(并行)计算。更可行的方法是并行化操作系统和库服务。已经可以在当前的硬件和操作系统设计中看到了这个例子。例如,网卡现在具有用于加速分组处理并且以线路速度(例如,加密,入侵检测等))提供更高级别的网络服务的板上并行处理器(网络处理器)。另一个例子,考虑到用于从主CPU分担视频渲染处理并向应用程序(例如Open GL)提供更高级别的图形API的视频卡上的强大处理器,可以想象用单芯片多核处理器替换这些专用卡。此外,随着核心数量的增加,可以使用相同的基本方法来并行化其他操作系统和库服务。
8.为了避免竞争,在SMP操作系统代码段中的临界区真的有必要吗,或者数据结构中的互斥信号量也可完成这项工作吗?
答:可能锁定数据结构就足够了。很难想象任何一段代码可以做到这一点而不涉及一些内核数据结构。所有资源的获取和发布都使用数据结构。对数据结构加锁很有可能是足够的,虽然不能证明。
9.在多处理器同步中使用TSL指令时,如果持有锁的CPU和请求锁的CPU都需要使用这个拥有互斥信号量的高速缓冲块,那么这个拥有互斥信号量的高速缓 冲块就得在上述两个CPU之间来回穿梭。为了减少总线交通的繁忙,每隔50个总线周期,请求锁的CPU就执行一条TSL指令, 但是持有锁的CPU在两条TSL指令之间需要频繁地引用该拥有互斥信号量的高速缓冲块。如果一个高速缓冲块中有16个32位字,每一个字都需要用一个总线周期传送,而该总线的频率是400MHz。那么高速缓冲块的来回移动会占用多少总线带宽?
答:每个TSL需要16个总线周期才能移动该块,同时它具有两路。因此,每50个总线周期有32个被移动缓存块占用。因此,64%的总线带宽被缓存来回移动占用。
10.课文中曾经建议在使用TSL轮询锁之间使用二进制指数补偿算法。也建议过在轮询之间使用最大时延。如果没有最大时延,该算法会正确工作吗?
答:是的,但是间插时间可能会非常久,性能下降。但这是正确的,即使没有最大限度。
11.假设在一个多处理器的同步处理中没有TSL指令。相反,提供了另一个指令SWP,该指令可以把一个寄存器的内容交换到内存的一个字中。这个指令可以用于多处理器的同步吗?如果可以,它应该怎样使用?如果不行,为什么它不行?
答:它和TSL一样好。它被用于将1加载到要使用的寄存器中。然后,该寄存器和内存字被原子地交换。在执行指令之后,存储器字被锁定(即,值为1),其以前的值现在包含在寄存器中。如果以前被加锁,该字未被更改,并且调用者必须循环等待。如果它以前没有加锁,现在被加锁。
12.在本问题中,读者要计算把一个自旋锁放到总线上需要花费总线的多少装载时间。假设CPU执行每条指令花费5纳秒。在一条指令执行完毕之后, 不需要任何总线周期,例如,执行TSL指令。每个总线周期比指令执行时间长10纳秒其至更多。如果一个进程使用TSL循环试图进入某个临界区,它要耗费多少的总线带宽?假设通常的高速缓冲处理正在工作,所以取一条循环体中的指令并不会浪费总线周期。
答:该循环由TSL指令(5nsec),总线周期(10nsec)和回到TSL指令(5nsec)的JMP组成。因此,在20nsec中,请求1个总线周期占用10ns。该回路耗费50%的总线带宽。
13.图8-12用于描绘分时环境,为什么在b部分中只出现了进程A?

14. 亲和调度减少了高速缓冲的失效。它也减少TLB的失效吗?对于缺页呢?
答:亲和调度与将正确的线程放在正确的CPU上有关。这样做可能会减少TLB的失效,因为这些都保留在每个CPU之内。另一方面,它对缺页没有影响,因为如果页面位于一个CPU的内存中,则它位于所有CPU的内存中。
15.对于图8-16中的每个拓扑结构,互连网络的直径是多少?请计算该问题的所有跳数(主机-路由器和路由器-路由器)。

16.考虑图8-16 d)中的双凸面拓扑,但是扩展到k×k该网络的直径是多少?提示:分别考虑k是奇数和偶数的情况。
答:在网格上,最坏的情况是相反的角落的节点试图进行通信。然而,该拓扑有一个圆环,使得相反的角落只需要两跳。所以,该拓扑最坏的情况是试图与中间的一个节点通信。对于k为奇数时,需要(k-1)/2跳从角落到中间的横线,到中间竖线又需要(k-1)/2跳,总共为k-1跳。对于偶数的k,中间是四个点组成的正方形,所以最坏的情况是从角落到正方形最远的点。水平方向是k/2跳,垂直方向是k/2跳,所以直径为k。
17.互联网络的平分贷款经常用来测试网络容量。其计算方法是,通过移走最小数量的链接,将网络分成两个相等的部分。然后把被移走链接的容量加入进去。 如果有很多方法进行分割,那么最小带宽就是其平分带宽。对于有一个8×8×8立方体的互连网络,如果每个链接的带宽是1Gbps,那么其平分带宽是多少?
答:网络可以通过中间的平面切成两个,给出两个系统,每个系统具有8×8×4的几何形状。两个半部之间有64个链路,平分带宽为64Gbps。
18.如果多计算机系统中的网络接口处于用户模式,那么从源 RAM到目的RAM只需要三个副本。假设该网络接口卡接收或发送一个32位的字需要20ns,并且该网络接口卡的频率是1Gbps。如果忽略掉复制的时间,那么把一个64字节的包从源送到目的地的延时是多少?如果考虑复制的时间呢?接着考虑需要有两次额外复制的情形,即在发送方将数据复制到内核的时间,和在接收方将数据从内核中取出的时间。在这种情形下的延时是多少?
答:如果考虑网络时间,则每位数据需要1ns,即每个数据包需要512ns延迟。要一次复制64字节,每侧需要320ns,共640ns,加上512ns传输时间,总共延时1132ns。如果需要两个附加副本,需要1792ns。
19.对于三次复制和五次复制的情形,重复前一个问题,不过这次是计算带宽而不是计算延时。
答:如果仅考虑传输时间,1Gbps网络能传输125 MB/秒。如果考虑三次复制,在1152 ns中移动64个字节,则带宽为55.6 MB/秒。如果考虑五次复制,在1792 ns中移动64字节,带宽为35.7 MB/秒。
20.在共享存储器多处理器和多计算机之间send和receive的实现要有多少差别,这些差别对性能有何影响?
答:在共享存储器的多计算机上,可以将执行发送的CPU的指针传递给执行接收的CPU,并在虚拟和物理内存地址之间进行可能的转换。在没有共享内存的多计算机上,一个CPU地址空间中的地址对另一个CPU没有意义,因此必须将发送缓冲区中的实际内容作为数据包传输,然后在接收缓冲区中重新组合。对于程序员来说,这个过程看起来是一样的,但是在多计算机上所需的时间要长得多。
21.在将数据从RAM传送到网络接口时,可以使用钉住页面的方法,假设钉住和释放页面的系统调用要花费1微秒时间。使用DMA方法复制速度是1字节需要5纳秒,而使用编程I/O方法需要20纳秒。一个数据包应该有多大才值得钉住页面并使用DMA方法?
答:通过编程I/O移动k个字节的时间是20k ns。 DMA的时间为2000 + 5k ns,令20k = 2000 + 5k,得到k = 133字节的平衡点。(原文题目有点问题)
22.将一个过程从一台机器中取出并且放到另一台机器上称为RPC,但会出现一些问题。在正文中,我们指出了其中四个:指针、未知数组大小、未知参数类型以及全局变量。有一个未讨论的问题是,如果(远程)过程执行一个系统调用会怎样。这样做会引起什么问题,应该怎样处理?
答:显然,如果远程过程执行系统调用,会发生错误。如果文件不存在,尝试读取远程计算机上的文件将无法正常工作。另外,在远程机器上设置定时器不会将信号发送回主叫机。处理远程系统调用的一种方法是将其陷阱并将其发回原始站点执行。
23.在DSM系统中,当出现一个页面故障时,必须对所需要的页面进行定位。请列出两种寻找该页面的可能途径。
答:首先,在广播网络上,可以进行广播请求。第二,一个集中维护页面的数据库。第三,每个页面可以具有由其虚拟地址的高k位指示的初始基地址,初始基地址可以跟踪每个页面的位置。
24.考虑图8-24中的处理器分配。假设进程H从节点2被移到节点3上。此时的外部信息流量是多少?
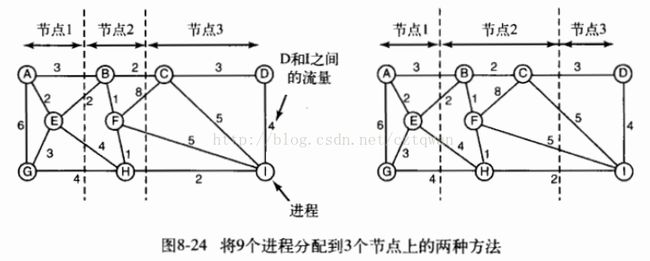
25.某些多计算机允许把运行着的进程从一个节点迁移到另一个节点。停止一个进程,冻结其内存映像,然后就把他们转移到另一个节点上是否足够?请指出要使所述的方法能够工作的两个必须解决的问题。
答:打开文件的表保存在内核中,所以如果一个进程有打开的文件,当它被解冻并尝试使用其中一个文件时,新的内核并不知道这些文件。第二个问题是信号掩码,也存储在原来的内核上。第三个问题是如果一个定时挂起,它将在错误的计算机上被关闭。一般来说,内核包含了很多关于进程的信息,必须成功迁移这些信息。
26.考虑能同时支持最多n个虚拟机的I型管理程序,PC机最多可以有4个主磁盘分区。请问n可以比4大吗?如果可以,数据可以存在哪里?
答:虚拟机与磁盘分区无关。虚拟机管理程序可以使用单个磁盘分区,并将其划分为子分区,并为每个虚拟机提供其中一个。原则上可以有数百个。它可以将磁盘静态划分为n个块,或者按要求执行此操作。
27.处理客户操作系统使用普通(非特权)指令改变页表的一个方式是将页表标记为只读,所以当它被修改的时候系统陷入。还有什么方式可以维护页表副本(shadow page table)?比较你的方法与只读页表方式在效率上的差别。
答:页表只能由客户操作系统修改,而不能由访客中的应用程序修改。当客户操作系统完成表的修改时,必须通过发出敏感指令(如RETURN FROM TRAP)切换回用户模式。该指令导致系统陷入并给予管理程序控制。然后,它可以检查客户操作系统中的页表,看看它们是否被修改。虽然这可以起作用,但是必须在访客应用程序所做的每个系统上检查所有的页表,也就是每次客户操作系统返回到用户模式时,每秒可能会有数千个这样的转换,因此它不可能像只读页表方式一样高效。
28.VMware每次对一个基本块进行二进制转换,然后执行这个基本块并开始转换下一个基本块。它能事先转换整个程序然后执行吗?如果能,每种技术的优点和缺点分别是什么?
答:它可以提前转换整个程序。不这样做的原因是许多程序都有大量的代码永远不会执行。通过按需转换基本块,未使用的代码没有被转换。按需转换的潜在缺点是,保持开始和停止转换的效率可能略低,但这种效果可能很小。
29.如果一个操作系统的源代码可以得到,对半虚似化一个操作系统有意义吗? 如果源代码不能得到呢?
答:有意义。由于源代码可以得到,所以Linux已经半虚拟化了。而由于源代码不能得到,Windows尚未进行半虚拟化。
30.各种PC在底层会有微小的差別,例如如何管理时钟、如何处理中断以及DMA方面的一些细节。那么这些差别是否意味着虚拟机在实际中不能够很好地工作?请解释你的答案。
答:不,这些差异可能意味着将虚拟机管理程序从一个平台移植到另一个平台需要一些调整,但机器仿真在所有情况下都是一样的,所以虚拟设备可以在任何机器上工作。
31.在以太网上为什么会有对电缆长度的限制?
答:以太网节点必须能够检测分组之间的冲突,因此两个距离最远的节点之间的传输时延必须小于要发送的最短分组的持续时间。否则,即使分组与电缆另一端的节点发送的分组发生碰撞,发送方也完全发送分组,并且检测不到冲突。
32. 在一台PC上运行多个虚拟机需要大量的内存,为什么?你能想出什么方式降低内存的使用量?请解释理由。
答:该机器不仅需要提供正常(客户)操作系统及其所有应用程序的内存,而且还需要提供代表客户操作系统执行敏感指令的管理程序所需的功能和数据结构的内存。类型2管理程序还具有主机操作系统的附加成本。而且,每个虚拟机都有自己的操作系统,所以会有N个操作系统拷贝存储在内存中。减少内存使用的一种方法是识别“共享代码”,并且只将该代码的一个副本保留在内存中。例如,一个网络服务器公司可能会运行多个虚拟机,每个虚拟机都运行相同版本的Linux操作系统代码和Apache Web服务器代码的相同副本。在这种情况下,代码段可以跨VM共享,即使数据区域必须是私有的。
33.在图8-30中,四台机器上的第三层和第四层标记为中间件和应用。在何种角度上它们是跨平台一致的,而在何种角度上它们是跨平台有差异的?

34.在图8-33中列出了六种不同的服务。对于下面的应用,哪一种更适用?a) Internet上的视频点播。b)下载一个网页。

(a)不可靠的连接。
(b)可靠的字节流。
35.DNS的名称有一个层次结构,如cs.uni.edu或sales.general-widget.com。维护DNS数据库的一种途径是使用一个集中式的数据库,但是实际上并没有这样做,其原因是每秒钟会有太多的请求。请提出一个实用的维护DNS数据库的建议。
答:它是分级维护的。有一个全球服务器.edu知道所有的大学和一个全球服务器.com知道所有以.com结尾的名字。因此,要查找cs.uni.edu,一台机器将首先在.edu服务器上查找uni,然后去那里询问有关cs的信息,依此类推。
36.在讨论浏览器如何处理URL时,曾经说明与端口80连接。为什么?
答:计算机可能有许多进程等待传入的连接。这些进程可能是Web服务器,邮件服务器,新闻服务器等。需要一些方法来使传入的连接指向某个特定的进程。这是通过让每个进程监听特定端口来完成的。已经规定Web服务器监听端口80,因此指向Web服务器的传入连接被发送到端口80。端口数字可以任意选择,但是必须选择一个数字。
37.虚拟机迁移可能比进程迁移容易,但是迁移仍然是困难的。在虚拟机迁移的过程中会产生哪些问题?
答:物理I/O设备仍然存在问题,因为它们不与虚拟机一起迁移,但是它们的寄存器可能保存着对系统正常运行至关重要的状态,比如对已经发布但尚未完成的设备(例如,磁盘)进行读取或写入操作。网络I/O特别困难,因为其他机器将继续向管理程序发送数据包,不知道虚拟机已移动。即使数据包可以重定向到新的虚拟机管理程序,虚拟机在迁移期间将无响应,这个时间可能很长,因为包括客户机操作系统在内的整个虚拟机必须移动到新机器上。因此,如果设备/管理程序缓冲区溢出,数据包可能会遇到很大的延迟甚至数据包会丢失。
38.在显示网页中使用的URL可以透明吗?请解释理由。
答:可以。例如,对www.intel.com的服务器的位置一无所知。
39.当浏览器获取一个网页时,它首先发起一个TCP链接以获得页面上的文本(该文本用HTML语言写成)。然后关闭链接并分析该页面。如果页面上有图形或图标,就发起不同的TCP链接以获取它们。请给出两个可以改善性能的替代建议。
答:一种方式是Web服务器将整个页面(包括所有图像)打包在一个大的zip文件中,并且首次发送整个页面,以便只需要一个连接。第二种方法是使用无连接协议,如UDP。这将消除连接开销,但需要服务器和浏览器自己进行差错控制。
40.在使用会话语义时,有一项总是成立的,即一个文件的修改对于进行该修改的进程而言是立即可见的,而对其他机器上的进程而言是绝对不可见的。不过存在一个问题,即这种修改对同一台机器上的其他进程是否应该立即可见。请提出正反双方的争辩意见。
答:读操作得到的值取决于进程是否与最后一个修改的进程在同一台机器上。这是为了使更改只对进行更改的进程可见。另一方面,具有单个缓存管理器的机器是更容易实现,且更便宜。如果必须维护每个被修改的文件的多个副本,管理进程会变得更加复杂,其返回值取决于哪个进程正在执行读操作。
41.当有多个进程需要访问数据时,基于对象的访问在哪些方面要好于共享存储器?
答:共享内存与整个页面一起使用。这可能导致虚假共享,访问发生在同一页面上的无关变量时会导致颠簸。将每个变量放在单独的页面上是浪费的。基于对象的访问消除了这些问题,并允许更细微的共享。
42.在Linda的in操作完成对一个元组的定位之后,线性地查询整个元组空间是 作常低效率的。请设计一个组织元组空间的方式,可以在所有的in操作中加快查询操作。
答:当元组插入到元组空间中时,对元组的任何字段进行散列没有帮助,因为in可能具有大多数正式的参数。总是有效的一个优化是注意到所有的out和in的所有字段都是键入的。因此,元组空间中所有元组的类型签名是已知的,并且元数据所需的元组类型也是已知的。建议为每个类型签名创建一个元组子空间。例如,所有的(int,int,int)元组都进入一个空间,所有的(string,int,float)元组都进入一个不同的空间。当执行in时,只能搜索匹配的子空间。
43.缓存区的复制很花费时间。写一个C程序找出你访问的系统中这种复制花费了多少时间。可使用clock或times函数用以确定在复制一个大数组时所花费的时间。试测试不同大小的数组,以便把复制时间和系统开销时间分开。
答:略。
44.编写可作为客户机和服务器代码片段的C函数,使用RPC来调用标准printf 函数,并编写一个主程序来测试这些函数。客户机和服务器通过一个可在网络上传输的数据结构实现通信。读者可以对客户机所能接收的格式化字符串长度以及数字、类型和变量的大小等方面设置限制。
答:略。
45.写两个程序用以模拟一台多计算机上的负载平衡。第一个程序应该按照一个初始化文件把m个进程分布到n个机器上。每个进程应该有一个通过 Gaussian分布随机挑选的运行时间,即该分布的平均值和标准偏差是模拟的参数。在每次运行的结尾,进程创建一些新的进程,按照Poisson分布选择这些新进程。当一个进程退出时,CPU必须确定是放弃进程或是寻找找新的进程。如果在机器上有总数超过k个进程的话,第一个程序应该使用发送者驱动算法放弃工作。第二个程序在必要时应该使用接收者驱动算法获得工作。 请给出所需要的合理假设,但要写出清楚的说明。
答:略。
46.写一个程序,实现8.2节中描述的发送方驱动和接收方驱动的负载平衡算法。这个算法必须把新创建的作业列表作为输入,作业的描述为(creating_processor, start_time,required_CPU_time),其中creating_processor表示创建作业的CPU序号,start_time表示创建作业的时间,required_CPU_time表示完成作业所需要的时间(以秒为单位)。当节点在执行一个作业的同时有第二个作业被创建,则认为该节点超负荷。在重负载和轻负载的情况下分別打印算法发出的探测消息的数 目。同时,也要打印任意主机发送和接收的最大和最小的探针数。为了模拟负载, 要写两个负载产生器。第一个产生器模拟重的负载,产生的负载为平均每隔AJL秒N个作业,其中AJL是作业的平均长度,N是处理器个数。作业长度可能有长有短,但是平均作业长度必须是AJL。作业必须随机地创建(放置)在所有处理器上。第二个产生器模拟轻的负载,每AJL秒随机地产生(N/3)个作业。为这两个负载产生器调节其他的参数设置,看看是如何影响探测消息的数目。
答:略。
47.实现发布/订阅系统的最简单的方式是通过一个集中的代理,这个代理接收发布的文章,然后向合适的订阅者分发这些文章。写一个多线程的应用程序来模拟 一个基于代理的发布/订阅系统。发布者和订阅者线程可以通过(共享)内存与代理进行通信。每个消息以消息长度域开头,后面紧跟着其他字符。发布者给代理发布的消息中,第一行是用“.”隔开的层次化主题,后面一行或多行是发布的文章正文。订阅者给代理发布的消息,只包含着一行用“.”隔开的层次化的兴趣行(imerest line),表示他们所感兴趣的文章。兴趣行可能包含“*.”等通配符,代理必须返回匹配汀阅者兴趣的所有(过去的)文章,消息中的多篇文章通过“BEGIN NEW ARTICLE”来分隔。订阅者必须打印他接收到的每条消息(如他的兴趣行)。订阅者必须连续接收任何匹配的新发布的文章。发布者和订阅者线程可通过终端输人“p”或“s”的方式自由创建(分别对应发布者和订阅者),后面紧跟的是层次化的主题或兴趣行。然后发布者需要输人文章,在某一行中键入“.”表示文章结束。(这个作业也可以通过基于TCP的进程间通信来实现)。
答:略。