前言
测试一般包括单元测试、性能测试、安全测试、功能测试,这篇文章主要讲解单元测试和性能测试。
单元测试
在开始讲解单元测试之前,让我们思考如下问题:
1.测试工程师是否可靠?
2.第三方代码是否可信赖?
3.在产品迭代过程中,如何持续保证代码质量?
4.测试会影响项目开发进度吗?
5.您的代码具备测试的条件吗?业务实现是否已经清晰了?
编写可测试的代码
对于上边的5个问题,如果您都可以从容的回答,那么,恭喜您,您的代码应该已经具备了一定的质量保证。其实,在正常的软件生产过程中,一般情况下遇到的问题,不是代码该不该测试,而是代码能不能测试,因此,我们需要首先保证你自己提交的代码是可以测试的,那么这样的代码符合如下几个条件:
1.单一职责
2.接口抽象
3.层次分离
单元测试介绍
单元测试主要包含:断言、测试框架、测试用例、测试覆盖率、mock、持续集成等,真的node我们还需要进行异步代码测试和私有方法测试。
断言
node提供了assert模块,来实现断言。那么,断言就是用于检查程序在运行时是否满足期望的一种工具。我们看一下断言的示例代码:
var assert = require('assert');
assert.equal(Math.max(1, 100), 100);
一旦assert.equal不满足期望,将会抛出AssertionError异常,整个程序将会停止执行。
我们来看看断言规范提供的几种测试方法:
| 方法 | 说明 |
|---|---|
| ok | 判断结果是否为真 |
| equal | 判断实际值与期望值是否相等 |
| notEqual | 判断实际值与期望值是否不相等 |
| deepEqual | 判断实际值与期望值是否深度相等,也就是对象或者数组的元素是否相等 |
| notDeepEqual | 判断实际值与期望值是否深度不相等 |
| strictEqual | 判断实际值与期望值是否严格相等,相当于=== |
| notStrictEqual | 判断实际值与期望值是否严格相等,相当于!== |
| throws | 判断代码块是否抛出异常 |
| doesNotThrow | 判断代码块是否没有抛出异常 |
| ifError | 判断实际值是否为一个假值(null、undefined、0、''、false),如果实际值为真,将会抛出异常 |
目前,市面上的断言库,大多是根据assert模块进行封装和扩展的,包括著名的should.js断言库。
测试框架
由于node是单线程的,并且,assert在抛出异常后,将会停止整个项目的运行,因此,为了提高体验度,正常的做法是使用测试框架,将抛出的异常记录在文件中,并继续执行后续的断言,最后,生成一个完备的测试报告。
测试框架并不参与测试,它主要用于管理测试用例和生成测试报告,并能在一定的程度上提升测试用例的开发速度,提高测试用例的可维护性和可读性。我这里使用的测试框架是TJ写的mocha,通过npm install mocha -g进行全局安装。
测试风格
测试风格主要分为:TDD(测试驱动开发)和BDD(行为驱动开发)
TDD
TDD关注所有功能是否被正确实现,每个功能都具备对应的测试用例,他的表述方式偏向于说明书风格。
下边展示,TDD风格的测试:
suite('Array', function () {
setup(function () {
// ...
});
suite('#indexOf()', function () {
test('should return -1 when not present', function () {
assert.equal(-1, [1, 2, 3].indexOf(4));
});
});
});
TDD对测试用例的组织主要采用suite和test完成,suite实现多层级描述,测试用例用test,它提供了setup和teardown两个钩子函数,setup和teardown分别在进入和退出suite时触发执行,我们来看一下TDD风格的组织示意图:
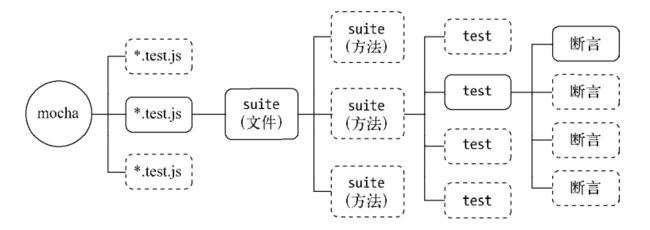
BDD
BDD关注整体行为是否符合预期,适合自顶而下的设计方式。他的表述方式更接近于自然语言习惯。
下边展示BDD风格的测试:
describe('Array', function () {
before(function () {
// ...
});
describe('#indexOf()', function () {
it('should return -1 when not present', function () {
[1, 2, 3].indexOf(4).should.equal(-1);
});
});
});
BDD测试用例的组织主要采用describe和it,describe可以描述多层级的结构,具体到测试用例时,用it来表述每个测试用例。此外,BDD风格还提供了before、after、beforeEach、afterEach这4个钩子方法,用于协助describe中测试用例的准备、安装、卸载和回收等工作。before和after分别在进入和退出describe时触发执行,beforeEach和afterEach则分别在describe中每一个测试用例(it)执行前和执行后触发执行。我们看一下BDD风格的组织示意图

测试报告
mocha的设计可以使用原生的assert来作为具体的断言实现,也可以采用扩展库,如should.js、expect、chai等,但是,无论采用哪种断言形式,运行测试用例户,测试报告才是开发者和质量管理者最关注的东西。mocha就可以产生测试报告,使用命令:mocha --reporters即可查看测试报告支持的格式:
$ mocha --reporters
dot - dot matrix
doc - html documentation
spec - hierarchical spec list
json - single json object
progress - progress bar
list - spec-style listing
tap - test-anything-protocol
landing - unicode landing strip
xunit - xunit reporter
teamcity - teamcity ci support
html-cov - HTML test coverage
json-cov - JSON test coverage
min - minimal reporter (great with --watch)
json-stream - newline delimited json events
markdown - markdown documentation (github flavour)
nyan - nyan cat!
执行mocha -R
添加package.js的devDependencies依赖
mocha只会运行在测试阶段,因此需要添加到package.js的devDependencies中
"devDependencies": {
"mocha": "*"
}
测试用例
一个完善的功能,需要有完善的、多方面的测试用例,一个测试用例中,至少包含一个断言。我们看一下代码:
describe('#indexOf()', function () {
it('should return -1 when not present', function () {
[1, 2, 3].indexOf(4).should.equal(-1);
});
it('should return index when present', function () {
[1, 2, 3].indexOf(1).should.equal(0);
[1, 2, 3].indexOf(2).should.equal(1);
[1, 2, 3].indexOf(3).should.equal(2);
});
});
注意,测试用例最少需要通过正向测试和反向测试来保证测试对功能的覆盖,也就是成功的和不成功的都要进行测试,从必要条件和充分条件两个方面入手进行测试。
异步测试
通过mocha来解决异步测试的问题,我们看代码:
it('fs.readFile should be ok', function (done) {
fs.readFile('file_path', 'utf-8', function (err, data) {
should.not.exist(err);
done();
});
});
上述是一个使用should断言库和BDD风格的测试用例,it接收了两个参数,title和callback,通过检查这个回调函数的形参长度fn.length就可以判断这个用例是否是异步调用,如果是异步调用,在执行测试用例时,会将一个函数done()注入为实参,测试代码需要主动调用这个函数通知测试框架当前测试用例执行完成,然后,测试框架才进行下一个测试用例的执行,这个跟next非常相似。
超时设置
mocha默认超时时间为2000毫秒,我们可以通过mocha -t
it('should take less than 500ms', function (done) {
this.timeout(500);
setTimeout(done, 300);
});
也可以在描述describe中调用this.timeout(ms),这会把当下层级的所有用例都设置超时时间。
describe('a suite of tests', function () {
this.timeout(500);
it('should take less than 500ms', function (done) {
setTimeout(done, 300);
});
it('should take less than 500ms as well', function (done) {
setTimeout(done, 200);
});
});
测试覆盖率
通过不停的给代码添加测试用例,将会不断的覆盖代码的分支和不同的情况,我们使用测试覆盖率来描述这一指标,测试覆盖率即是整体覆盖率也可以明确到具体行上。我们看一下这段代码:
exports.parseAsync = function (input, callback) {
setTimeout(function () {
var result;
try {
result = JSON.parse(input);
} catch (e) {
return callback(e);
}
callback(null, result);
}, 10);
};
我们为其添加测试部分
describe('parseAsync', function () {
it('parseAsync should ok', function (done) {
lib.parseAsync('{"name": "JacksonTian"}', function (err, data) {
should.not.exist(err);
data.name.should.be.equal('JacksonTian');
done();
});
});
});
若要探知这段代码的测试覆盖率,我们需要一种工具来统计每一行代码是否执行,这个工具是jscover,我们使用nom install jscover -g进行全局安装。
假设这段代码遵循commonjs规范,并放在lib下,那么可以调用,jscover lib lib-cov对代码进行编译,jscover会将lib目录下的.js文件编译到lib-cov目录下,你会得到类似这样的分析结果:
$jscoverage['index.js'][31]++;
exports.parseAsync = function(input, callback) {
_$jscoverage['index.js'][32]++;
setTimeout(function() {
_$jscoverage['index.js'][33]++;
var result;
_$jscoverage['index.js'][34]++;
try {
_$jscoverage['index.js'][35]++;
result = JSON.parse(input);
} catch (e) {
_$jscoverage['index.js'][37]++;
return callback(e);
}
_$jscoverage['index.js'][39]++;
callback(null, result);
}, 10);
};
我们看到每一行原始代码前都有_$jscoverage,他们将会在执行时统计每一行代码被执行了多少次。
同时,为了区分注入测试用例的代码和原始代码的区别,我们会在模块入口,例如index.js,中做简单的区别。
module.exports = process.env.LIB_COV ? require('./lib-cov/index') : require('./lib/index');
在运行测试代码时,会设置一个LIB_COV变量,以区分测试环境和正常环境。
准备好编译之后的代码,就可以进行运行了:
// 设置当前命令行有效的变量
export LIB_COV=1
mocha -R html-cov > coverage.html
我们来看一下测试覆盖率流程示意图
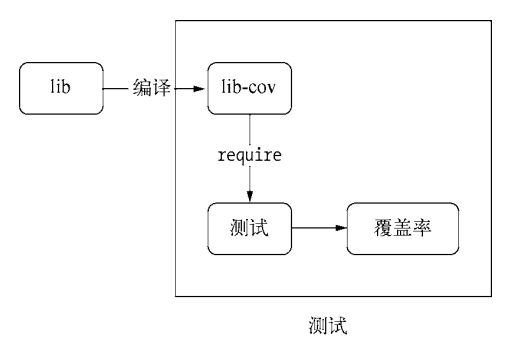
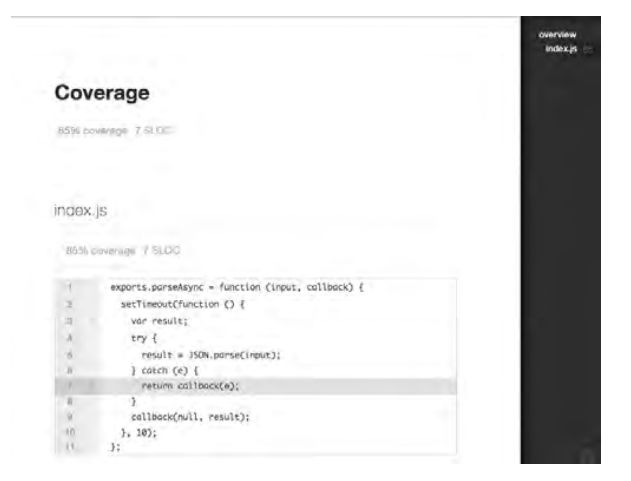
我们可以看到,有一行代码没有覆盖到,因此,来构造一个错误的输入可以覆盖错误情况,下面我们为其补足测试用例:
it('parseAsync should throw err', function (done) {
lib.parseAsync('{"name": "JacksonTian"}}', function (err, data) {
should.exist(err);
done();
});
});
下面我们来说一下jscover的补足,它需要依赖java环境,还会将代码编译到一个额外的新目录,稍显麻烦。因此,如果觉得jscover比较麻烦,还可以尝试使用blanket模块。我们使用这个命令来检测覆盖率。
mocha --require blanket -R html-cov > coverage.html
同时,还需要在配置文件中配置scripts节点,增加pattern属性来描述需要检测测试覆盖率的模块。
"scripts": {
"blanket": {
"pattern": "eventproxy/lib"
}
},
此处,blanket的编译跟第二章的文件模块编译相同,node将编译逻辑封装在require.extension['.js']中,blanket正是在这个环节实现编译的,然后将覆盖率的追踪代码插入到原始代码中,然后再由原始模块处理逻辑进行处理。
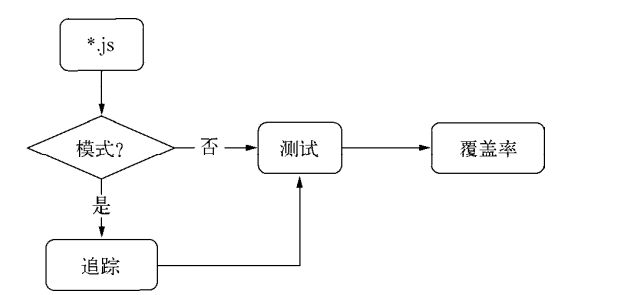
使用blanket就不需要增加如下代码了:
module.exports = process.env.LIB_COV ? require('./lib-cov/index') : require('./lib/index');
mock
因为,各种异常都用可能发生,不一定是我们在测试中可以想到的,比如数据库连接失败,就有可能是网络异常造成的,甚至也可能是由于管理员更改了密码造成的,由于模拟异常并不是很容易,因此,科学家们给了异常一个特殊的名词:mock,我们通过伪造被调用放来测试上层代码的健壮性等。
exports.getContent = function (filename) {
try {
return fs.readFileSync(filename, 'utf-8');
} catch (e) {
return '';
}
};
为了解决这个问题,我们通过伪造fs.readFileSync()方法抛出错误来触发异常,同时为了保证该测试用例不影响其余用例,我们需要在执行完后还原它,为此,前面提到的before和after就要用上了:
describe("getContent", function () {
var _readFileSync;
before(function () {
_readFileSync = fs.readFileSync;
fs.readFileSync = function (filename, encoding) {
throw new Error("mock readFileSync error"));
};
});
// it();
after(function () {
fs.readFileSync = _readFileSync;
})
});
我们在执行测试用例前将引用替换掉,执行结束后还原它,如果每个测试用例执行前后都要进行设置和还原,就使用beforeEach和afterEach。这样看来,mock的过程比较繁琐,因此,推荐使用muk模块解决这个问题。
var fs = require('fs');
var muk = require('muk');
before(function () {
muk(fs, 'readFileSync', function (path, encoding) {
throw new Error("mock readFileSync error");
});
});
// it();
after(function () {
muk.restore();
});
//当有多个用例时
var fs = require('fs');
var muk = require('muk');
beforeEach(function () {
muk(fs, 'readFileSync', function (path, encoding) {
throw new Error("mock readFileSync error");
});
});
// it();
// it();
afterEach(function () {
muk.restore();
});
模拟时无需临时缓存正确引用,用例执行结束后调用muk.restore()恢复即可。
通过模拟底层方法出现异常的情况,现在只要检测调用方的输出值是否符合期望即可,无需关注是否是真正的异常,模拟异常可以很大程度的帮助开发者提升代码的健壮性,完善调用方代码的容错能力。
//另外一个需要注意的地方是避免将异步模拟为同步
fs.readFile = function (filename, encoding, callback) {
callback(new Error("mock readFile error"));
};
//我们应该这样写,让异步还是异步
fs.readFile = function (filename, encoding, callback) {
process.nextTick(function () {
callback(new Error("mock readFile error"));
});
};
私有方法的测试
在模块中的没有用exports引用的都是私有方法,这部分的测试也很重要。我们可以使用rewire来进行私有模块的测试,也就是使用rewire引用模块
//
var limit = function (num) {
return num < 0 ? 0 : num;
};
//测试用例
it('limit should return success', function () {
var lib = rewire('../lib/index.js');
var litmit = lib.__get__('limit');
litmit(10).should.be.equal(10);
});
rewire的模块引入和require一样,都会为原始文件增加参数:
(function(exports, require, module, __filename, __dirname) {֖ })
此外,他还会注入其他的代码:
(function (exports, require, module, __filename, __dirname) {
var method = function () { };
exports.__set__ = function (name, value) {
eval(name " = " value.toString());
};
exports.__get__ = function (name) {
return eval(name);
};
});
每一个被rewire引入的模块,都会有set()和get()方法,这个就是巧妙的利用了闭包的原理,在eval()执行时,实现了对模块内部局部变量的访问,从而可以将局部变量导出给测试用例进行调用执行。
测试工程化与测试自动化
我们通过持续集成减少手工成本。
工程化
在linux下,推荐使用makefile来构建项目
TESTS = test /*.js
REPORTER = spec
TIMEOUT = 10000
MOCHA_OPTS =
test:
@NODE_ENV=test./ node_modules / mocha / bin / mocha \
--reporter $(REPORTER) \
--timeout $(TIMEOUT) \
$(MOCHA_OPTS) \
$(TESTS)
test - cov:
@$(MAKE) test MOCHA_OPTS = '--require blanket' REPORTER = html - cov > coverage.html
test - all: test test - cov
.PHONY: test
开发者只需要通过make test和make test-cov就可以执行复杂的单元测试和覆盖率。(makefile的缩进是tab符合,不能用空格,记得在包描述文件中,配置blanket)
持续集成
此节需要补充。
性能测试
性能测试包括负载测试、压力测试、基准测试、web应用网络层面的性能测试、业务指标换算。作者在书中没有介绍负载测试和压力测试,需要以后补充完整。
基准测试
基准测试要统计的就是在多少时间内执行了多少次某个方法,一般会以次数作为参照物,然后比较时间,以此判别性能的差距。
假如,我们要测试es5提供的Array.prototype.map和循环提取值两种方式,他们都是迭代一个数组,根据回调函数执行的返回值得到一个新的数组:
var nativeMap = function (arr, callback) {
return arr.map(callback);
};
var customMap = function (arr, callback) {
var ret = [];
for (var i = 0; i < arr.length; i++) {
ret.push(callback(arr[i], i, arr));
}
return ret;
};
最简单的办法就是构造相同的输入数据,然后执行相同的次数,最后比较时间:
var run = function (name, times, fn, arr, callback) {
var start = (new Date()).getTime();
for (var i = 0; i < times; i++) {
fn(arr, callback);
}
var end = (new Date()).getTime();
console.log('Running s d times cost d ms', name, times, end % % % - start);
};
//然后分别调用1000000次
var callback = function (item) {
return item;
};
run('nativeMap', 1000000, nativeMap, [0, 1, 2, 3, 5, 6], callback);
run('customMap', 1000000, customMap, [0, 1, 2, 3, 5, 6], callback);
//得到结果
Running nativeMap 1000000 times cost 873 ms
Running customMap 1000000 times cost 122 ms
为了规范和更好的输出,推荐使用benchmark这个模块来组织基准测试:
var Benchmark = require('benchmark');
var suite = new Benchmark.Suite();
var arr = [0, 1, 2, 3, 5, 6];
suite.add('nativeMap', function () {
return arr.map(callback);
}).add('customMap', function () {
var ret = [];
for (var i = 0; i < arr.length; i++) {
ret.push(callback(arr[i]));
}
return ret;
}).on('cycle', function (event) {
console.log(String(event.target));
}).on('complete', function () {
console.log('Fastest is ' + this.filter('fastest').pluck('name'));
}).run();
它通过suite来组织每组测试,在测试套件中调用add()来添加被测试的代码。
nativeMap x 1,227,341 ops/sec ±1.99 (83 runs sampled) %
customMap x 7,919,649 ops/sec ±0.57% (96 runs sampled)
Fastest is customMap
压力测试
对网络接口做压力测试需要考察的几个指标有吞吐率、响应时间、并发数,这些指标反映了服务器的并发处理能力。
可以使用ab、siege、http_load等来进行压力测试,下面使用ab工具来构建压力测试:
$ ab -c 10 -t 3 http://localhost:8001/
This is ApacheBench, Version 2.3 <$Revision: 655654 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking localhost (be patient)
Completed 5000 requests
Completed 10000 requests
Finished 11573 requests
Server Software:
Server Hostname: localhost
Server Port: 8001
Document Path: /
Document Length: 10240 bytes
Concurrency Level: 10
Time taken for tests: 3.000 seconds
Complete requests: 11573
Failed requests: 0
Write errors: 0
Total transferred: 119375495 bytes
HTML transferred: 118507520 bytes
Requests per second: 3857.60 [#/sec] (mean)
Time per request: 2.592 [ms] (mean)
Time per request: 0.259 [ms] (mean, across all concurrent requests)
Transfer rate: 38858.59 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.3 0 31
Processing: 1 2 1.9 2 35
Waiting: 0 2 1.9 2 35
Total: 1 3 2.0 2 35
Percentage of the requests served within a certain time (ms)
50 2 %
66 3 %
75 3 %
80 3 %
90 3 %
95 3 %
98 5 %
99 6 %
100 35 (longes % t request)
这段代码表示,10个并发用户持续3秒向服务器端发出请求。我们再来看看上述代码中各个参数的含义:
| 参数 | 含义 |
|---|---|
| Document Path | 表示文档路径,此处为/ |
| Document Length | 表示文档的长度,就是报文的大小,这里有10kb |
| Concurrency Level | 并发级别,就是我们在命令中传入的c,此处为10,即10个并发 |
| Time taken for tests | 表示完成所有测试所花费的时间,它与命令行中传入的t选项有细微出入 |
| Complete requests | 表示在这次测试中一共完成多少次请求 |
| Failed requests | 表示其中产生失败的请求数,这次测试中没有失败的请求 |
| Write errors | 表示在写入过程中出现的错误次数(连接断开导致的) |
| Total transferred | 表示所有的报文大小 |
| HTML transferred | 表示所有的报文大小 |
| Requests per second | 这个是我们重点关注的值,它表示服务器每秒能处理多少请求,是重点反映服务器并发能力的指标。这个值又称RPS或QPS |
| 第一个Time per request | 用户平均等待时间 |
| 第二个Time per request | 服务器平均请求处理事件,前者除以并发数得到后者 |
| Transfer rate | 表示传输率,等于传输的大小除以传输时间,这个值受网卡的带宽限制。 |
| Connection Times | 连接时间,它包括客户端向服务器建立连接、服务器端处理请求、等待报文响应的过程 |
最后的数据是请求的响应时间分布,这个数据是Time per request的实际分布,可以看出,50%的请求都在2ms内完成,99%的请求都在6ms内返回。
这个测试是在朴灵的笔记本上进行的配置如下
cpu 2.4 GHz Intel Core i5
memory GB 1333 MHz DDR3
基准测试驱动开发
Felix Geisendörfer是node早期的一个代码贡献者,它开发了几个mysql驱动,都是以追求性能著称,它在faster than c的幻灯片中提到了一种他所使用的开发模式,Benchmark Driven Development,也就是BDD,中文翻译是基准测试开发,这个BDD分为如下几个步骤:
1.写基准测试
2.写、改代码
3.收集数据
4.找出问题
5.回到第2步
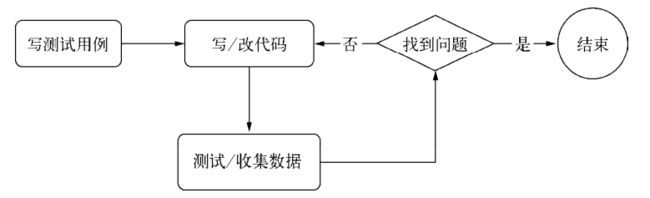
我们参照BDD的方式,验证一下cluster是否也可行。
原始代码无需更改,我们增加一个cluster.js,用于根据机器上的CPU数量启动多进程来进行服务
var cluster = require('cluster');
cluster.setupMaster({
exec: "server.js"
});
var cpus = require('os').cpus();
for (var i = 0; i < cpus.length; i++) {
cluster.fork();
}
console.log('start ' + cpus.length + ' workers.');
//启动
node cluster.js
start 4 workers
//然后用相同的参数测试
$ ab -c 10 -t 3 http://localhost:8001/
This is ApacheBench, Version 2.3 <$Revision: 655654 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking localhost (be patient)
Completed 5000 requests
Completed 10000 requests
Finished 14145 requests
Server Software:
Server Hostname: localhost
Server Port: 8001
Document Path: /
Document Length: 10240 bytes
Concurrency Level: 10
Time taken for tests: 3.010 seconds
Complete requests: 14145
Failed requests: 0
Write errors: 0
Total transferred: 145905675 bytes
HTML transferred: 144844800 bytes
Requests per second: 4699.53 [#/sec] (mean)
Time per request: 2.128 [ms] (mean)
Time per request: 0.213 [ms] (mean, across all concurrent requests)
Transfer rate: 47339.54 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.5 0 61
Processing: 0 2 5.8 1 215
Waiting: 0 2 5.8 1 215
Total: 1 2 5.8 2 215
Percentage of the requests served within a certain time (ms)
50 2 %
66 2 %
75 2 %
80 2 %
90 3 %
95 3 %
98 4 %
99 5 %
100 215 (longest request) %
从测试结果看,QPS从原来的3857.6变成了4699.53,确实提高了,但是性能并没有与cpu的数量成线性增长,这个问题,我们以后有机会在探讨吧。
测试数据与业务数据的转换
通常,在进行实际的功能开发之前,我们需要评估业务量,以便功能开发完成后,能够胜任实际的在线业务量,如果用户量只有几个,每天的pv只有几十个,那么网站开发几乎不需要什么优化就能胜任,如果pv上10万,甚至百万、千万,就需要运用性能测试来验证是否能满足实际业务需求了,如果不能满足,就要运用各种优化手段提升服务能力。
假设某个页面每天的访问量为100万,根据实际业务情况,主要访问量大致集中在10个小时以内,那么换算公式就是:
QPS = PV / 10h
100万业务量,每秒要27.7才能胜任。
总结
测试是应用或者系统最重要的质量保证手段,有单元测试实践的项目,必然对代码的粒度和层次都掌握的较好,单元测试能够保证项目每个局部的正确性,也能够在项目迭代过程中很好地监督和反馈迭代质量。