作者:George Novack翻译:Bach(才云)
校对:星空下的文仔(才云)、bot(才云)
K8sMeetup
为什么要使用机器学习流水线
现在,机器学习流水线(Machine Learning Pipeline)被大家给予了极大的关注,它旨在自动化和协调训练机器学习模型所涉及的各个步骤,但是,很多人也不清楚将机器学习工作流程建模为自动流水线到底有什么好处。
当训练新的 ML 模型时,大多数据科学家和 ML 工程师会开发一些新的 Python 脚本或 interactive notebook,以进行数据提取和预处理,来构建用于训练模型的数据集;然后创建几个其他脚本或 notebook 来尝试不同类型的模型或机器学习框架;最后收集、调试指标,评估每个模型在测试数据集上的运行情况,来确定要部署到生产中的模型。

手动机器学习工作流程
显然,这是对真正机器学习工作流程的过度简化,而且这种通用方法需要大量的人工参与,并且除了最初开发该方法的工程师之外,其他人都无法轻易重复使用。
由此,我们使用机器学习流水线来解决这些问题。与其将数据准备、模型训练、模型验证和模型部署视为特定模型中的单一代码库,不如将其视为一系列独立的模块化步骤,让每个步骤都专注于具体任务。

机器学习流水线
将机器学习工作流程建模为机器学习流水线有很多好处:
- 自动化:通过消除手动干预的需求,我们可以安排流水线按照需求重新训练模型,从而确保模型能够适应随时间变化的训练数据。
- 重复使用:由于流水线的步骤与流水线本身是分开的,所以我们可以轻松地在多个流水线中重复使用单个步骤。
- 重复性:任何数据科学家或工程师都可以通过手动工作流程重新运行流水线,这样就很清楚需要以什么顺序运行不同的脚本或 notebook。
- 环境解耦:通过保持机器学习流水线的步骤解耦,我们可以在不同类型的环境中运行不同的步骤。例如,某些数据准备步骤可能需要在大型计算机集群上运行,而模型部署步骤则可能在单个计算机上运行。
K8sMeetup
什么是 Kubeflow
Kubeflow 是一个基于 Kubernetes 的开源平台,旨在简化机器学习系统的开发和部署。Kubeflow 在官方文档中被称为 “Kubernetes 机器学习工具包”,它由几个组件(component)组成,这些组件跨越了机器学习开发生命周期的各个步骤,包括了 notebook developent environment、超参数调试、功能管理、模型服务以及 ML Pipelines。

Kubeflow 中央仪表板
在本文中,我们只关注 Kubeflow 的 Pipelines 组件。
K8sMeetup
环境
本文选择在裸机上运行的 Kubernetes 集群,但实际上我们可以在安装 Kubeflow 的任何 Kubernetes 集群上运行示例代码。
本地唯一需要的依赖项是 Kubeflow Pipelines SDK,我们可以使用 pip 安装 SDK:pip install kfp 。
K8sMeetup
Kubeflow Pipelines
Kubeflow 中的流水线由一个或多个组件(component)组成,它们代表流水线中的各个步骤。每个组件都在其自己的 Docker 容器中运行,这意味着流水线中的每个步骤都具有自己的一组依赖关系,与其他组件无关。
对于开发的每个组件,我们创建一个单独的 Docker 镜像,该镜像会接收输入、执行操作、进行输出。另外,我们要有一个单独的 Python 脚本,pipeline.py 脚本会从每个 Docker 镜像创建 Pipelines 组件,然后使用这些组件构造流水线(Pipeline)。我们总共创建四个组件:
- preprocess-data:该组件将从
sklearn.datasets中加载Boston Housing数据集,然后将其拆分为训练集和测试集。 - train-model:该组件将训练模型,以使用“Boston Housing”数据集来预测 Boston 房屋的中位数。
- test-model:该组件会在测试数据集上计算并输出模型的均方误差。
- deploy-model:在本文中,我们不会专注于模型的部署和服务,因此该组件将仅记录一条消息,指出它正在部署模型。实际情况下,这可能是将任何模型部署到 QA 或生产环境的通用组件。
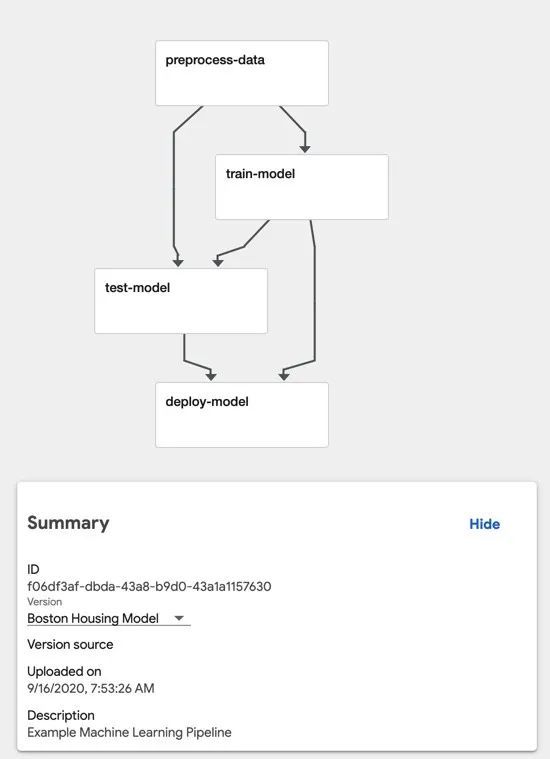
ML 流水线视图
K8sMeetup
Preprocess Data 组件
第一个 Pipelines 组件用 sklearn.datasets 加载 Boston Housing 数据集。我们使用 Sci-kit Learn 的 train_test_split 函数将此数据集分为训练集和测试集,然后用 np.save 将数据集保存到磁盘,以便以后的组件重复使用。

到目前为止,我们只有一个简单的 Python 脚本。现在,我们需要创建一个执行该脚本的 Docker 镜像,这里编写一个 Dockerfile 来创建镜像:

从 python:3.7-slim 基础镜像开始,我们使用 pip 安装必需的软件包,将预处理的 Python 脚本从本地计算机复制到容器,然后将 preprocess.py 脚本指定为容器 Entrypoint,这样在容器启动时,脚本就会执行。
K8sMeetup
构建流水线
现在,我们着手构建流水线,首先要确保可以从 Kubernetes 集群访问上文构建的 Docker 镜像。本文使用 GitHub Actions 构建镜像并将其推送到 Docker Hub。

现在定义一个组件,每个组件都要定义为一个返回 ContainerOp 类型的对象(object)。此类型来自我们先前安装的 kfp SDK。这是流水线中第一个组件的组件定义:
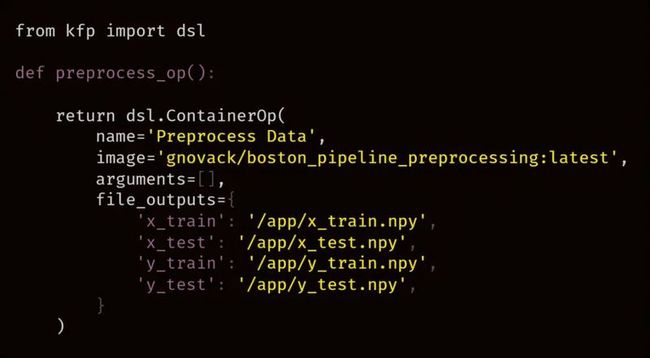
请注意,对于 image 参数,我们传递了上文 Dockerfile 定义的 Docker 镜像的名称,对于 file_outputs 参数,指定了 Python 脚本组件保存到磁盘的四个 .npy 文件的文件路径。通过将这四个文件指定为“File Output”,我们可以将它们用于流水线中的其他组件。
注意:在组件中对文件路径进行硬编码不是一个很好的做法,就如上面的代码中那样,这要求创建组件定义的人员要了解有关组件实现的特定细节。这会让组件接受文件路径作为命令行参数更加干净,定义组件的人员也可以完全控制输出文件的位置。
定义了第一个组件后,我们创建一个使用 preprocess-data 组件的流水线:
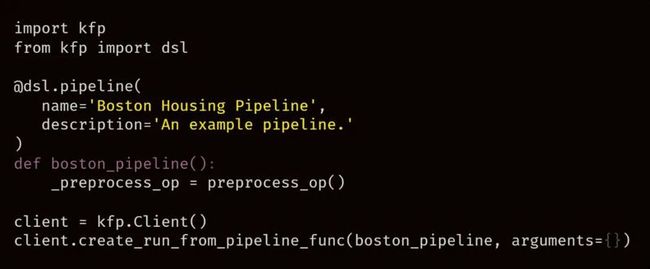
流水线由一个注解 @dsl.pipeline 修饰的 Python 函数定义。在函数内,我们可以像使用其他任何函数一样使用组件。为了运行流水线,我们创建一个 kfp.Client 对象,再调用 create_run_from_pipeline_func 函数,并传入定义流水线的函数。
如果执行该脚本,然后导航到 Kubeflow 中央仪表板流水线部分的“Experiment”视图,我们就能看到流水线的执行情况。在流水线的图形视图中单击该组件,我们还可以看到来自 preprocess-data 组件的四个文件输出。

Kubeflow 流水线用户界面
因此,我们可以运行流水线并在 GUI 中进行可视化,但是只有一个步骤的流水线并没什么意思,下面我们来创建其余的组件。
K8sMeetup
其余组件
对于 train-model 组件,我们创建一个简单的 Python 脚本,该脚本使用 Sci-kit Learn 来训练回归模型。这类似于预处理器组件的 Python 脚本,其中最大的区别是,这里用 argparse 来接受训练数据的文件路径以作为命令行参数。

这个 Dockerfile 与我们用于第一个组件的非常相似,从基础镜像开始,安装必要的软件包,将 Python 脚本复制到容器中,然后执行脚本。

其他两个组件 test-model 和 deploy-model 遵循着相同的模式。实际上,它们与我们已经实现的两个组件非常像,这里就不再赘述。如果大家有兴趣,可以在以下 GitHub 存储库中找到该流水线的所有代码:https : //github.com/gnovack/kubeflow-pipelines
就像之前的 preprocess-data 组件一样,我们将从这三个组件中构建 Docker 镜像并将其推送到 Docker Hub:
- train-model: gnovack/boston_pipeline_train
- test-model: gnovack/boston_pipeline_test
- deploy-model: gnovack/boston_pipeline_deploy
K8sMeetup
完整的流水线
现在是时候创建完整的机器学习流水线了。首先,我们为 train-model、test-model 和 deploy-model 组件创建组件定义。

该 train-model 组件的定义与之前的 preprocess-data 组件的定义之间的唯一主要区别是, train-model 接受两个参数,x_train 和 y_train,其将作为命令行参数传递给容器并进行解析,这会在使用 argparse 模块的组件实现中。
这里 test-model 和 deploy-model 组件定义为:
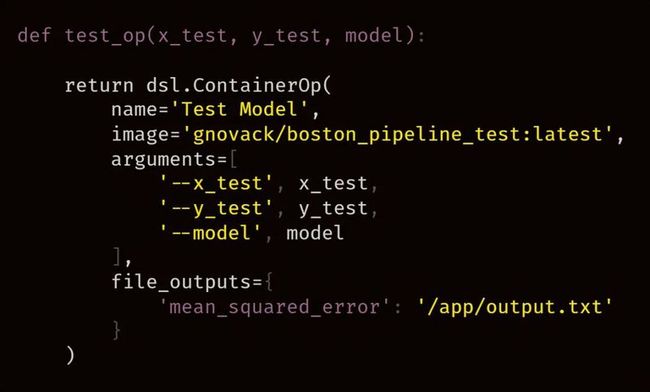
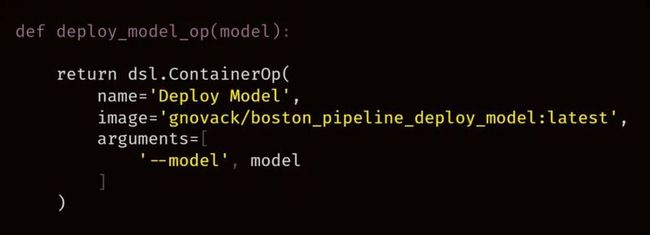
定义了四个 Pipelines 组件后,我们现在重新访问 boston_pipeline 函数,并将所有组件一起使用。

这里有几点要注意:
- 在第 6 行,当我们调用
preprocess_op()函数时,将函数的输出存储在名为_preprocess_op的变量中。要访问 preprocess-data 组件的输出,我们使用_preprocess_op.outputs['NAME_OF_OUTPUT']。 - 默认情况下,当我们从组件访问
file_outputs时,我们获取的是文件内容而不是文件路径。在本文中,由于这些不是纯文本文件,因此我们不能仅将文件内容作为命令行参数传递到 Docker 容器组件中。要访问文件路径,我们需要使用dsl.InputArgumentPath()并传入组件输出。
现在,如果我们运行创建的流水线并导航到 Kubeflow 中央仪表板中的“Pipelines UI”,我们可以看到流水线图中显示的所有四个组件。
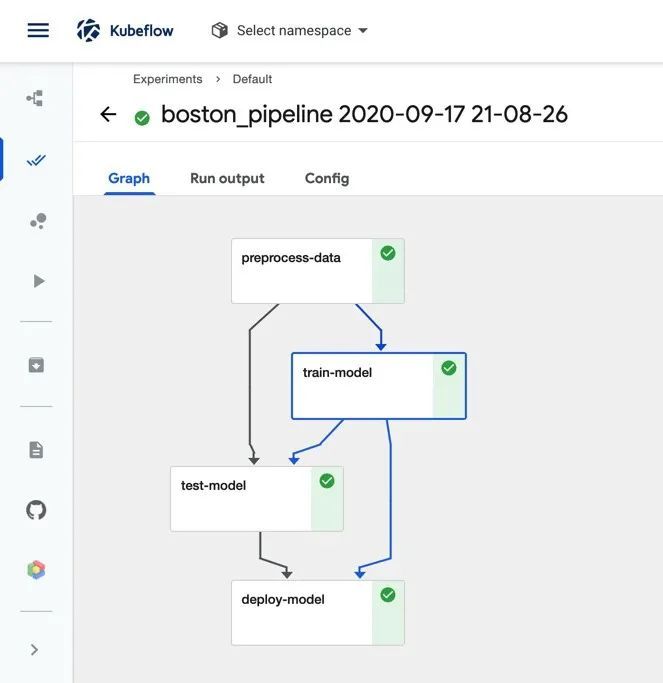
K8sMeetup
结论
在本文中,我们创建了一个非常简单的机器学习流水线,该流水线可以加载一些数据、训练模型、在保留数据集上对其进行评估、对其进行“deploy”。通过使用 Kubeflow Pipelines,我们能够将该工作流中的每个步骤封装到 Pipelines 组件中,每个组件都在各自独立的 Docker 容器环境中运行。这种封装促进了机器学习工作流程中各步骤之间的松散耦合,并为将来流水线中组件的重复使用提供了可能性。
本文简单介绍了 Kubeflow Pipelines 的功能,希望能够帮助大家了解组件(component)的基础知识,以及如何使用它们创建和运行流水线。