数据分析实战 -- 股票量化交易分析
前景提要
大二实习结束过去五个多月了。
当时入职数据分析还算是有点基础进入的公司。
如今这么久不学数据分析了,似乎都有点生疏了。
今天写个数据分析实战,为了弥补一下亏欠粉丝的承诺吧。
主要目标
- 使用Python爬取股票数据
- 数据清洗并上传至HDFS
- 使用PyHive对股票数据进行分析
- Python数据分析-量化交易
股票量化交易分析
使用Python爬取股票数据
我们这次的目标地址是url:网易行情中心 沪深行情
在这个网站里面找到行业面板,里面随便点开一个行业信息,我在这里点开通用设备制造。
因为我看见这些行业中,通用设备制造里面的股份有点多,所以以这个为例,其他均相同。

点开后会进入该行业的行情中心,我们找到一个你觉得顺眼的股份点击进入,查看某一个股份信息,我们这次实战根据一个股份来做分析统计。其余均相同。

我们进入一个股份后,为了减轻我们的负担,使用该网页自带的下载数据功能下载,点开资金流向里面的历史交易数据,将之前的数据通通下载到本地。
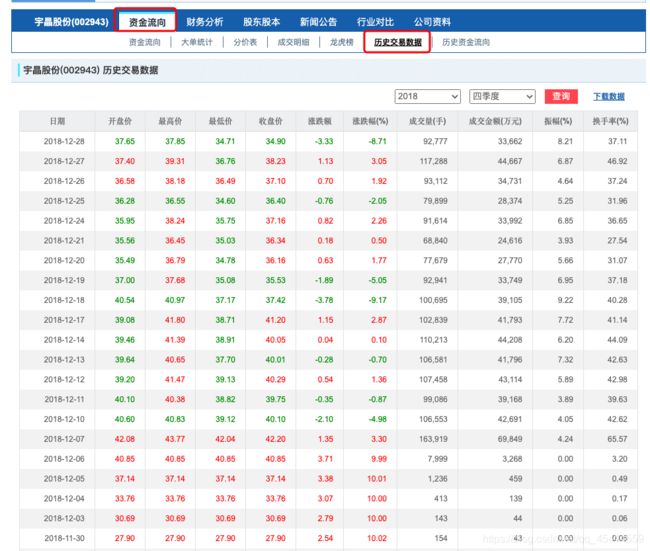
在谷歌的下载内容里面找到我们刚才下载下来的文件。
如果想和我下一样的,请点击这个链接

分析URL下载地址
当然我们做量化交易不能单独使用一支股票作为我们的数据,我们还需要使用爬虫使我们的数据量最大化。
我们观察一下网页的链接地址:http://quotes.money.163.com/service/chddata.html?code=0601318&start=20070301&end=20180301&fields=TCLOSE;HIGH;LOW;TOPEN;LCLOSE;CHG;PCHG;TURNOVER;VOTURNOVER;VATURNOVER;TCAP;MCAP
大致分析一下,可以发现code值就是股票代码,start和end分别是开始和结束的日期,那就通过修改参数进行批量下载吧。以通用设备制造为例,我们首先进入这个网站
寻找XML地址
我们刷新该网页,点开XML选项,从第一个开始寻找每一个股份都在哪里。
发现第三个XML就是我们要寻找的。
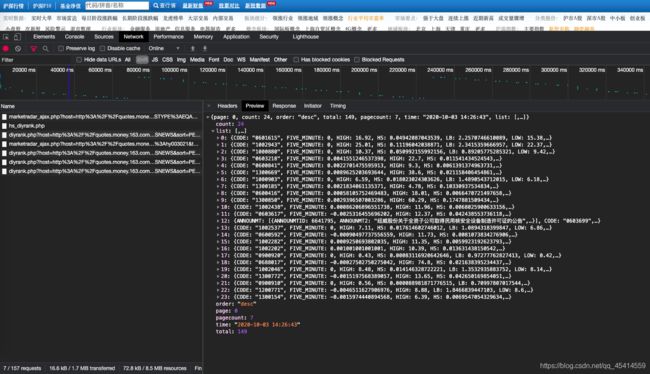
里面的东西很全。Preview是返回的序列,pagecount是当前金融类的总页数,知道页数就可以循环拿到所有的股票数据了。
初学爬虫简单介绍一下数据采集
- requests 模块
# 1、get无参数实例
import requests
ret = requests.get('https://www.baidu.com/')
# 2、get有参数实例
import requests
payload = {
'key1': 'value1', 'key2': 'value2'}
ret = requests.get("https://www.baidu.com/", params=payload)
# 1、基本post实例
import requests
payload = {
'key1': 'value1', 'key2': 'value2'}
ret = requests.post("https://www.baidu.com/", data=payload)
# 2、post发送请求头和数据实例
import requests
import json
url = 'https://www.baidu.com/'
payload = {
'some': 'data'}
headers = {
'content-type': 'application/json'}
ret = requests.post(url, data=json.dumps(payload), headers=headers)
GET请求的数据会附在URL之后(就是把数据放置在HTTP协议头中),以?分割URL和传输数据,参数之间以&相连,如果数据是英文字母/数字,原样发送,如果是空格,转换为+,如果是中文/其他字符,则直接把字符串用BASE64编码;POST把提交的数据则放置在是HTTP包的包体中。
- 对于多线程和多进程的缺点是在IO阻塞时会造成了线程和进程的浪费,所以异步IO是首选,在该实战中用到的是gevent + requests
import gevent
import requests
from gevent import monkey
monkey.patch_all()
def fetch_async(method, url, req_kwargs):
print(method, url, req_kwargs)
response = requests.request(method=method, url=url, **req_kwargs)
print(response.url, response.content)
# ##### 发送请求 #####
gevent.joinall([
gevent.spawn(fetch_async, method='get', url='https://www.python.org/', req_kwargs={
}),
gevent.spawn(fetch_async, method='get', url='https://www.yahoo.com/', req_kwargs={
}),
gevent.spawn(fetch_async, method='get', url='https://github.com/', req_kwargs={
}),
])
# ##### 发送请求(协程池控制最大协程数量) #####
# from gevent.pool import Pool
# pool = Pool(None)
# gevent.joinall([
# pool.spawn(fetch_async, method='get', url='https://www.python.org/', req_kwargs={}),
# pool.spawn(fetch_async, method='get', url='https://www.yahoo.com/', req_kwargs={}),
# pool.spawn(fetch_async, method='get', url='https://www.github.com/', req_kwargs={}),
# ])
编写程序设计
我们首先建立一个文件夹,里面包含四个文件夹。
文件夹含义:
bin:项目的执行文件
conf:配置文件
core:核心代码文件
share:共享文件
- 我们在bin目录下创建python代码,名字叫crawler_start.py
- 我们在conf目录下创建python代码,名字叫setting.py
- 我们在core目录下创建python代码,名字叫crawler_main.py
编辑bin/crawler_start.py,内容如下:
import os
import sys
base_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(base_dir)
from core import crawler_main
if __name__ == '__main__':
crawler_main.run()
启动文件程序比较简单,base_dir是项目根目录的绝对路径,把这个路径加入到python环境变量中,这样就可以导入core下的crawler_main。
编辑conf/settings.py,内容如下:
import os
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
# 股票的行业ID
INDUSTRY_ID = {
"financial_ID": "hy010000",
"medicine_ID": "hy003014", }
# 行业对应的数据先设置为空,主程序中存储股票代码的序列
STOCK_CODE = {
"financial": None,
"medicine": None, }
settings文件中主要存放固定的常量。
编辑core/crawler_main.py,内容如下:
# coding:utf-8
import os
import json
import gevent
import requests
from gevent import monkey
from gevent.pool import Pool
from conf import settings
# 把标准库中的thread/socket等给替换掉.这样我们在后面使用socket的时候可以跟平常一样使用,无需修改任何代码,但是它变成非阻塞的了
monkey.patch_all()
def get_code(industry_id, page_num=0):
"""
访问行业概况的页面,获取json序列;
拿到页面总数,循环当前行业的股票代码存到列表中。
:param industry_id:股票行业的代码
:param page_num:网页的页面数
:return:返回一个列表,存的是当前行业所有的股票代码
"""
temp = []
industry_url = 'http://quotes.money.163.com/hs/service/diyrank.php?host=http%3A%2F%2Fquotes.money.163.com%2Fhs%2Fservice%2Fdiyrank.php&page={page_num}&query=PLATE_IDS%3A{industry_id}&fields=NO%2CSYMBOL%2CNAME%2CPRICE%2CPERCENT%2CUPDOWN%2CFIVE_MINUTE%2COPEN%2CYESTCLOSE%2CHIGH%2CLOW%2CVOLUME%2CTURNOVER%2CHS%2CLB%2CWB%2CZF%2CPE%2CMCAP%2CTCAP%2CMFSUM%2CMFRATIO.MFRATIO2%2CMFRATIO.MFRATIO10%2CSNAME%2CCODE%2CANNOUNMT%2CUVSNEWS&sort=PERCENT&order=desc&count=24&type=query'
response = requests.get(
industry_url.format(
page_num=page_num, industry_id=industry_id),
)
list_obj = json.loads(response.text)
page = list_obj["page"]
pagecount = list_obj["pagecount"]
for i in list_obj["list"]:
temp.append(i["CODE"])
for i in range(page + 1, pagecount):
response = requests.get(
industry_url.format(
page_num=i, industry_id=industry_id),
)
list_obj = json.loads(response.text)
for j in list_obj["list"]:
temp.append(j["CODE"])
return temp
def fetch_async(method, url, args):
"""
当一个greenlet遇到IO操作时,比如访问网络,
就自动切换到其他的greenlet,等到IO操作完成,
再在适当的时候切换回来继续执行。由于IO操作非常耗时,
经常使程序处于等待状态,有了gevent为我们自动切换协程,
就保证总有greenlet在运行,而不是等待IO。
:param method:请求方式
:param url:网页地址
:param args:字典
:return:
"""
response = requests.request(method=method, url=url)
print(url)
try:
g = response.iter_lines()
next(g)
with open(os.path.join(settings.BASE_DIR, "share", args["save_dir"], args["stock_code"] + ".csv"), "w", encoding="utf-8") as wf:
wf.write(next(g).decode(encoding='gbk') + '\n')
for row in g:
if row != b'':
wf.write(row.decode(encoding='gbk') + '\n')
except StopIteration:
os.remove(os.path.join(settings.BASE_DIR, "share", args["save_dir"], args["stock_code"] + ".csv"))
def main(stock_dic):
"""
通过列表生成式,把下载csv文件的地址格式化,生成每个任务。
:param stock_dic:
:return:
"""
download_url = 'http://quotes.money.163.com/service/chddata.html?code={stock_code}&start=20170101&end=20180101&fields=TCLOSE;HIGH;LOW;TOPEN;LCLOSE;CHG;PCHG;TURNOVER;VOTURNOVER;VATURNOVER;TCAP;MCAP'
for name, list_obj in stock_dic.items():
if not os.path.exists(os.path.join(settings.BASE_DIR, "share", name)):
os.mkdir(os.path.join(settings.BASE_DIR, "share", name))
pool = Pool(10)
# 所有任务
request_list = [pool.spawn(fetch_async, method='get', url=download_url.format(stock_code=i),
args={
"stock_code": i, "save_dir": name}) for i in
list_obj]
# 开始执行,等待它们完成任务
gevent.joinall(request_list)
print("crawler to complete.")
def run():
medicine_list = get_code(settings.INDUSTRY_ID["medicine_ID"])
financial_list = get_code(settings.INDUSTRY_ID["financial_ID"])
settings.STOCK_CODE["medicine"] = medicine_list
settings.STOCK_CODE["financial"] = financial_list
main(settings.STOCK_CODE)
- 执行启动文件会运行run函数;
- 第一个执行get_code函数,是获取某行业所有股票代码,通过industry_url获取总页码,循环每一页获取股票代码,最后将获取的所有股票代码存到列表中返回;
- 下面执行main函数,通过列表生成式,把下载csv文件的地址格式化,生成每个任务。
代码测试
运行crawler_start
查看share目录中是否存在下载的目录,这里我们爬取了金融类和医疗类的股票信息

数据清洗上传到HDFS
数据清洗是对数据进行重新审查和校验的过程,目的在于删除重复信息、纠正存在的错误,并提供数据一致性。
数据清洗从名字上也看的出就是把“脏”的“洗掉”,指发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等。因为数据仓库中的数据是面向某一主题的数据的集合,这些数据从多个业务系统中抽取而来而且包含历史数据,这样就避免不了有的数据是错误数据、有的数据相互之间有冲突,这些错误的或有冲突的数据显然是我们不想要的,称为“脏数据”。我们要按照一定的规则把“脏数据”“洗掉”,这就是数据清洗。而数据清洗的任务是过滤那些不符合要求的数据,将过滤的结果交给业务主管部门,确认是否过滤掉还是由业务单位修正之后再进行抽取。不符合要求的数据主要是有不完整的数据、错误的数据、重复的数据三大类。数据清洗是与问卷审核不同,录入后的数据清洗一般是由计算机而不是人工完成。
python连接HDFS
首先先下载第三方库HDFS
pip install hdfs
运用python中的hdfs模块,连接hadoop hdfs的程序:
import hdfs
#创建hdfs连接实例,要保证hadoop已经启动
client = hdfs.Client("http://127.0.0.1: 50070")
#对hdfs进行操,创建/hdfs_ test_ dir目录
client.makedirs("/hdfs_test_dir', permission=755)
程序编写
首先先jps检查一下hadoop是否启动
cd /apps/hadoop/sbin
./start-all.sh
我们在刚才下载的share文件夹下重新建立python文件
- 在bin下创建python文件,名为upload_start.py、cleanout_start.py
- 在core下创建python文件,名为upload_file.py、cleanout_file.py
编辑bin/upload_start.py,内容如下:
import os
import sys
base_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(base_dir)
from core import upload_file
if __name__ == '__main__':
upload_file.run()
启动文件程序比较简单,base_dir是项目根目录的绝对路径,把这个路径加入到python环境变量中,这样就可以导入core下的upload_file。
编辑bin/cleanout_start.py,内容如下:
import os
import sys
base_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(base_dir)
from core import cleanout_file
if __name__ == '__main__':
cleanout_file.run()
启动文件程序比较简单,base_dir是项目根目录的绝对路径,把这个路径加入到python环境变量中,这样就可以导入core下的cleanout_file。
编辑conf/settings.py,追加内容如下:
HDFS_SAVE_DIR = "/stock_data"
HDFS_API_URL = "http://127.0.0.1:50070"
settings文件中主要存放固定的常量。
编辑core/upload_file.py,该段代码功能为:先创建目录,再将数据上传到hdfs,内容如下:
#!/usr/bin/env python
import hdfs
import os
from conf import settings
def run():
client = hdfs.Client(settings.HDFS_API_URL)
# 在hdfs系统创建/stock_data目录,权限755
client.makedirs(settings.HDFS_SAVE_DIR, permission=755)
# share中的数据上传hdfs的/stock_data目录
upload_status = client.upload(
settings.HDFS_SAVE_DIR,
os.path.join(settings.BASE_DIR, "share")
)
print(upload_status)
编辑core/cleanout_file.py,该段代码功能为:遍历每个目录的每个文件,运用pandas模块打开文件,将第三列数据清洗,保存文件,内容如下:
import pandas as pd
import os
from conf import settings
def run():
data_file = os.path.join(settings.BASE_DIR, 'share')
for d in os.listdir(data_file):
for f in os.listdir(os.path.join(data_file, d)):
current_file = os.path.join(data_file, d, f)
df = pd.read_csv(current_file, header=None)
df[2] = df.apply(lambda x: df[df.iloc[:, 2].duplicated() == True].head(1).iloc[:, 2], axis=1)
df.to_csv(current_file, header=None, index=None, encoding='utf-8')
print('cleanout file to complete.')
运行cleanout_start.py和upload_start.py文件即可
使用PyHive对股票数据进行分析
实验环境
hive-1.1.0-cdh5.4.5
hadoop-2.6.0-cdh5.4.5
mysql-5.5.53
实验内容
案例分析一:分析通用设备制造全部股票2019年的总涨跌额,并排出上涨股票前十名。
案例分析二:分析通用设备制造股票2019年成交量最大的前10天,成交金额分别为多少。
案例分析三:分析2019全年股票成交量前十名,并指出成交量第一的股票最新流通市值为多少。将Hive中的结果表通过Sqoop命令导入到Mysql中。
实验步骤
首先,切换到/apps/hadoop/etc/hadoop目录下,使用vim编辑core-site.xml文件。
cd /apps/hadoop/etc/hadoop
vim core-site.xml
修改hadoop的配置文件core-site.xml,在xml文件中< configuration> < /configuration>之间插入如下代码,保存退出。
<property>
<name>hadoop.proxyuser.amiee.groupsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.amiee.hostsname>
<value>*value>
property>
切换到/apps/hadoop/sbin目录下,开启hadoop相关进程
cd /apps/hadoop/sbin
./start-all.sh
将之前清洗后的数据上传至HDFS中的根目录下
hadoop fs -put /data/mydata/data /
启动mysql服务
sudo service mysql start
python安装pyhive、thrift、sasl、thrift_sasl模块
pip install pyhive thrift sasl thrift_sasl -i https://pypi.douban.com/simple
启动hiveserver2服务,&表示后台运行
hive --service hiveserver2 &
编写程序
首先导入pyhive模块并连接hive
from pyhive import hive
cursor = hive.connect(host='127.0.0.1', username='amiee').cursor()
创建并使用stockhive数据库
# create database stockhive
cursor.execute("create database if not exists stockhive")
# use database stockhive
cursor.execute("use stockhive")
我们以通用设备制造股票为例子,创建hive外部表,名为financial,建表语句如下:
# create table financial
cursor.execute("create external table if not exists financial\
( date date,\
Stock_code string,\
name string,\
Closing_price float,\
Highest_price float,\
Lowest_price float,\
Opening_price float,\
Before_the_close float,\
Change_amount float,\
Quote_change float,\
Turnover_rate float,\
Volume int,\
Turnover float,\
The_total_market_capitalization string,\
Circulation_market_capitalization string) \
row format delimited fields terminated by ',' \
lines terminated by '\n' \
location '/data/financial'")
该表字段解释如下:
date, 日期, 2020-10-03,
Stock_code, 股票代码, '600000,
name, 名称, 浦发银行,
Closing_price, 收盘价, 16.3,
Highest_price, 最高价, 16.44,
Lowest_price, 最低价, 16.17,
Opening_price, 开盘价, 16.21,
Before_the_close, 前收盘, 16.21,
Change_amount, 涨跌额, 0.09,
Quote_change, 涨跌幅, 0.5552,
Turnover_rate, 换手率, 0.0791,
Volume, 成交量, 16237125,
Turnover, 成交金额, 265043268.0,
The_total_market_capitalization, 总市值, 3.52377962729e+11,
Circulation_market_capitalization 流通市值 3.34456742479e+11
查看financial表信息
cursor.execute("desc financial")
for i in cursor.fetchall():
print(i)

为date创建索引
cursor.execute("create index index_date on table financial(date) \
as'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' \
with deferred rebuild")
案例分析一:查询通用设备制造全部股票2019年的总涨跌额,并排出上涨股票前十名
查询通用设备制造全部股票2019年的总涨跌额
cursor.execute("select Stock_code,sum(Change_amount) from financial group by Stock_code")
for i in cursor.fetchall():
print(i)
**PS:**执行该sql会调用MapReduce,因此会有一定执行时间,等待即可,同时我们可以在启动hiveserver2的终端界面看到该MapReduce执行过程,方便我们检查错误。

创建分析结果表result0,包含两个字段(Stock_code string,Change_amount_sum float),并以\t为分隔符。并分析出2019年上涨股票的前10名并将结果插入result0表中
cursor.execute("create table result0(Stock_code string,Change_amount_sum float) \
row format delimited fields terminated by '\t' \
stored as textfile")
cursor.execute("insert into table result0 \
select Stock_code,sum(Change_amount) as change_amount_sum from financial \
group by Stock_code \
order by change_amount_sum desc \
limit 10")
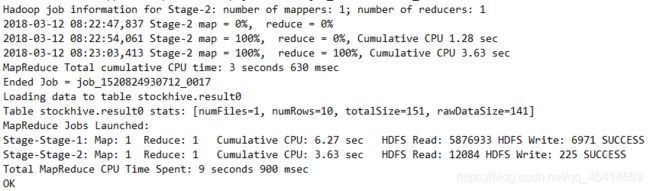
查询result0表中内容
cursor.execute("select * from result0")
for i in cursor.fetchall():
print(i)

案例分析二:分析金融类股票2019年成交量最大的前10天,成交金额分别为多少
创建分析结果表result1并将分析结果插入该表,result1表包含四个字段(Stock_code string,date date,max_volume int,turnover float),以\t为分隔符。
cursor.execute("create table result1 row format delimited fields terminated by '\t' \
stored as textfile \
as select stock_code,date,max(volume) as max_volume,turnover from financial \
group by stock_code,date,turnover \
order by max_volume desc limit 10")
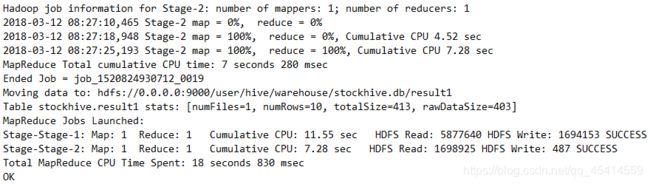
案例分析三:分析2019全年股票成交量前十名并指出成交量第一的股票最新流通市值为多少
创建result2表,包含股票代码stock_code和成交量volume两个字段,以\t为分隔符。
cursor.execute("create table result2 row format delimited fields terminated by '\t' \
stored as textfile \
as select stock_code,sum(volume) as sum_volume from financial \
group by stock_code \
order by sum_volume desc limit 10")
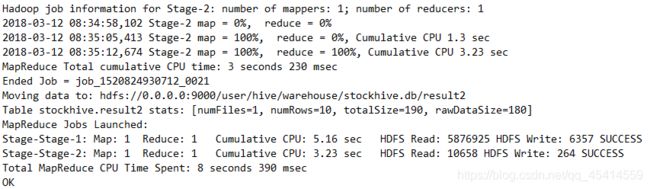
result2表内容为2019全年股票成交量前十名的企业。
cursor.execute("select * from result2")
for i in cursor.fetchall():
print(i)

使用Sqoop将分析结果数据持久化到Mysql数据库
开启mysql数据库
mysql -u root -p

创建并使用stock数据库
create database stock;
use stock;

创建三张表result_0、result_1、result_2分别对应hive中的result0、result1、result2
create table result_0 (stock_code varchar(100),change_amount_sum float);
create table result_1 (stock_code varchar(100),date date,max_volume int,turnover float);
create table result_2 (stock_code varchar(100),sum_volume bigint);

使用Sqoop命令将Hive中的result0表、result1表、result2表导入到Mysql中的result_0表、result_1表、result_2表。
- result0导入result_0
sqoop export \
--connect jdbc:mysql://localhost:3306/stock?characterEncoding=UTF-8 \
--username root \
--password strongs \
--table result_0 \
--export-dir /user/hive/warehouse/stockhive.db/result0/000000_0 \
--input-fields-terminated-by '\t'
- result1导入result_1
sqoop export \
--connect jdbc:mysql://localhost:3306/stock?characterEncoding=UTF-8 \
--username root \
--password strongs \
--table result_1 \
--export-dir /user/hive/warehouse/stockhive.db/result1/000000_0 \
--input-fields-terminated-by '\t'
- result2导入result_2
sqoop export \
--connect jdbc:mysql://localhost:3306/stock?characterEncoding=UTF-8 \
--username root \
--password strongs \
--table result_2 \
--export-dir /user/hive/warehouse/stockhive.db/result2/000000_0 \
--input-fields-terminated-by '\t'
至此数据导入完成。
Python数据分析–量化交易
1.股票:股票是股份公司发给出资人的一种凭证,股票的持有者就是股份公司的股东。
2.股票的作用:
- 出资证明、证明股东身份、对公司经营发表意见
- 公司分红、交易获利
3.影响股价的因素:
- 公司自身因素:股票自身价值是决定股价最基本的因素,而这主要取决于发行公司的经营业绩、资信水平以及连带而来的股息红利派发状况、发展前景、股票预期收益水平等。
- 行业因素:行业在国民经济中地位的变更,行业的发展前景和发展潜力,新兴行业引来的冲击等,以及上市公司在行业中所处的位置,经营业绩,经营状况,资金组合的改变及领导层人事变动等都会影响相关股票的价格。
- 市场因素:投资者的动向,大户的意向和操纵,公司间的合作或相互持股,信用交易和期货交易的增减,投机者的套利行为,公司的增资方式和增资额度等,均可能对股价形成较大影响。
- 心理因素:情绪波动,判断失误,盲目追随大户、狂抛抢购
- 经济因素:经济周期,国家的财政状况,金融环境,国际收支状况,行业经济地位的变化,国家汇率的调整等
- 政治因素
4.量化投资:利用计算机技术并且采用一定的数学模型去实践投资理念,实现投资策略的过程。
5.量化投资的优势:
- 避免主观情绪、人性弱点和认知偏差,选择更加客观
- 能同时包括多角度的观察和多层次的模型
- 及时跟踪市场变化,不断发现新的统计模型,寻找交易机会
- 在决定投资策略后,能通过回测验证其效果
6.学习Python数据分析(量化交易)主要使用以下第三方相关模块:
- NumPy:数值计算
- pandas:数据分析
- Matplotlib:图标绘制
7.学习使用NumPy+pandas+Matplotlib完成股票金叉死叉、双均线的计算
入门Numpy
扩展库 numpy 是 Python 支持科学计算的重要扩展库,是数据分析和科学计算领域如 scipy、pandas、sklearn 等众多扩展库中必备的扩展库之一,提供了强大的 N 维数组及其相关的运算、复杂的广播函数、C/C++和Fortran代码集成工具以及线性代数、傅里叶变换和随机数生成等功能。本次重点讲解数组和矩阵及其相关的运算。
我曾教过一期很完整的Numpy教程,如果想要正式了解的话请点击->我的博客连接
NumPy的主要功能:
- ndarray,一个多维数组结构,高效且节省空间
- 无需循环对整组数据进行快速运算的数学函数
- 读写磁盘数据的工具以及用于操作内存映射文件的工具
- 线性代数、随机数生成和傅里叶变换功能
- 用于集成C、C++等代码的工具
安装方法:pip install numpy -i https://pypi.douban.com/simple
引用方式:import numpy as np
常用属性:
- T 数组的转置(对高维数组而言)
- dtype 数组元素的数据类型
- size 数组元素的个数
- ndim 数组的维数
- shape 数组的维度大小(以元组形式)
入门Pandas
pandas是Python的一个用于数据分析的库:http://pandas.pydata.org
API速查:http://pandas.pydata.org/pandas-docs/stable/api.html
统计、分组、排序、透视表自由转换,如果你已经很熟悉结构化数据库与Excel的功能,就会知道pandas有过之而无不及。
我曾教过两期很完整的Pandas教程,如果想要正式了解的话请点击
我的第一篇入门介绍
我的第二篇进阶介绍
pandas的主要功能:
- 具备对其功能的数据结构DataFrame、Series
- 集成时间序列功能
- 提供丰富的数学运算和操作
- 灵活处理缺失数据
安装方法:pip install pandas -i https://pypi.douban.com/simple
引用方法:import pandas as pd
pandas-Series特性:
Series支持NumPy模块的特性(下标):
- 从ndarray创建Series:Series(arr)
- 与标量运算:sr*2
- 两个Series运算:sr1+sr2
- 索引:sr[0], sr[[1,2,4]]
- 切片:sr[0:2]
- 通用函数:np.abs(sr)
- 布尔值过滤:sr[sr>0]
Series支持字典的特性(标签):
- 从字典创建Series:Series(dic)
- in运算:’a’ in sr
- 键索引:sr[‘a’], sr[[‘a’, ‘b’, ‘d’]]
pandas-Series缺失数据:
**缺失数据:**使用NaN(Not a Number)来表示缺失数据。其值等于np.nan。内置的None值也会被当做NaN处理。
处理缺失数据的相关方法:
- dropna() 过滤掉值为NaN的行
- fillna() 填充缺失数据
- isnull() 返回布尔数组,缺失值对应为True
- notnull() 返回布尔数组,缺失值对应为False
- 过滤缺失数据:sr.dropna() 或 sr[sr.notnull()]
- 填充缺失数据:sr.fillna(0)
pandas-DataFrame:
DataFrame是一个表格型的数据结构,含有一组有序的列。
DataFrame可以被看做是由Series组成的字典,并且共用一个索引。
入门Matplotlib
Matplotlib是一个强大的Python绘图和数据可视化的工具包。
安装方法:pip install matplotlib -i https://pypi.douban.com/simple
引用方法:import matplotlib.pyplot as plt
绘图函数:plt.plot()
显示图像:plt.show()
Matplotlib-plot:
plot函数:
- 线型linestyle(-,-.,–,…)
- 点型marker(v,^,s,*,H,+,x,D,o,…)
- 颜色color(b,g,r,y,k,w,…)
我们在这里使用我们已经储备好的data.csv文件。
该文件我已经传入百度网盘中,各位可以直接下载使用。
链接: https://pan.baidu.com/s/1NZgtx5wS0aZWRybfsu41hQ 密码: jc9a
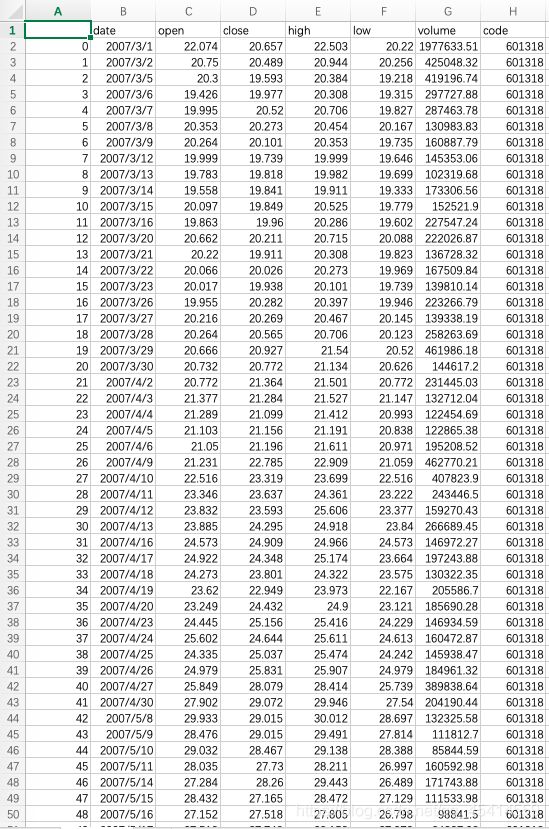
在test.py文件下编写代码,导入numpy、pandas、matplotlib,并读取data.csv中的数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('data.csv',index_col='date',parse_dates=['date'])
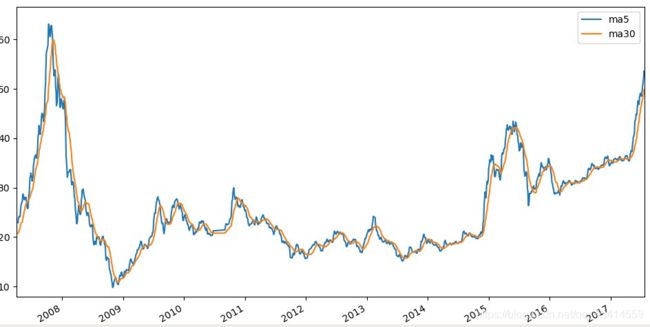
均线: 对于每一个交易日,都可以计算出前N天的移动平均值,然后把这些移动平均值连起来,成为一条线,就叫做N日移动平均线。
举例: 比如前5个交易日的收盘价分别为10,9,9,10,11元,那么,5日的移动平均股价为9.8元。同理,如果下一个交易日的收盘价为12,那么在下一次计算移动平均值的时候,需要计算9,9,10,11,12元的平均值,也就是10.2元。将这平均值连起来,就是均线。
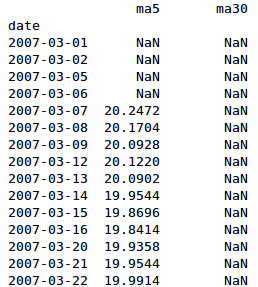
计算5日均线和30日均线
方法一:常规的for循环方法,缺点是运行时间长:
df['ma5'] = np.nan
df['ma30'] = np.nan
for i in range(4, len(df)):
df.loc[df.index[i],'ma5'] = df['close'][i-4:i+1].mean()
for i in range(29, len(df)):
df.loc[df.index[i],'ma30'] = df['close'][i-29:i+1].mean()
print(df['ma5'])
print(df['ma30'] )
方法二:使用cunsum函数计算,这里涉及到位移函数shift()
sr = df['close'].cumsum()
df['ma5'] = (sr - sr.shift(1).fillna(0).shift(4))/5
df['ma30'] = (sr - sr.shift(1).fillna(0).shift(29))/30
print(df['ma5'])
print(df['ma30'] )
方法三,使用rolling()函数中的mean()方法
df['ma5'] = df['close'].rolling(5).mean()
df['ma30'] = df['close'].rolling(30).mean()
print(df['ma5'])
print(df['ma30'] )
计算金叉、死叉
双均线策略,通过建立m天移动平均线,n天移动平均线,则两条均线必有交点。若m>n,n天平均线“上穿越”m天均线则为买入点,我们称之为金叉。反之为卖出点,我们称之为死叉。
口诀:
短期均线上穿长期均线为金叉
短期均线下穿长期均线为死叉
继续编写test.py文件,去掉NaN,因为有NaN的数据不满足双均线策略
df = df.dropna()
使用位移函数shift():
death_cross = df[(df['ma30']>=df['ma5'])&(df['ma30']<df['ma5']).shift(1)].index
golden_cross = df[(df['ma30']<=df['ma5'])&(df['ma30']>df['ma5']).shift(1)].index
print('golden_cross:',golden_cross)
print('death_cross:',death_cross)

通过Matplotlib做出5日和30日的双均线图像
df[['ma5','ma30']].plot()
plt.show()
因为知识量有点杂多,所以这期没有全部代码。
望各位想要入门数据分析的小伙伴们,继续努力。