【数据结构Python描述】树堆(heap)简介和Python手工实现及使用树堆实现优先级队列
文章目录
- 一、堆数据结构简介
-
- 1. 定义
- 2. 性质
- 二、堆数据结构应用
-
- 1. `add(k, v)`
-
- 完全二叉树性质保证
- 堆序性质保证
- 2. `remove_min()`
-
- 完全二叉树性质保证
- 堆序性质保证
- 三、堆数据结构实现
-
- 1. 实现方式选择
- 2. 数据结构实现
-
- 2.1 堆的ADT
- 2.2 堆方法实现
-
- `_parent()`
- `_left()`
- `_right()`
- `_has_left()`
- `_has_right()`
- `_swap()`
- `_upheap()`
- `_downheap()`
- 2.3 优先级队列方法实现
-
- `__init__()`
- `__len__()`
- `add(k, v)`
- `min()`
- `remove_min()`
- 2.4 基于堆的优先级队列方法复杂度分析
- 四、完整测试代码
在【数据结构Python描述】优先级队列简介及Python手工实现中,我们使用位置列表作为键值对形式记录的存储容器,通过两种策略分别给出了一个优先级队列实现:
UnsortedPriorityQueue:队列中的记录不按照键的大小顺序排列;SortedPriorityQueue:队列中的记录按照键的大小顺序排列。
由此,在比较这两种不同策略的实现后,可以发现一个有趣的现象:
UnsortedPriorityQueue中插入记录方法add()的最坏时间复杂度虽然为 O ( 1 ) O(1) O(1),但是查找(或同时删除)键最小的记录的方法min()(或remove_min())的最坏时间复杂度为 O ( n ) O(n) O(n);SortedPriorityQueue中虽然查找(或同时删除)键最小记录的方法min()(或remove_min())的最坏时间复杂度为 O ( 1 ) O(1) O(1),但插入记录方法add()的最坏时间复杂度虽然为 O ( n ) O(n) O(n)。
实际上,由上述分析可知,如果实际要求add()、min()和remove_min()三个方法的最坏时间复杂度均低于 O ( n ) O(n) O(n),则上述两种实现方式均无法满足要求。
为了实现上述需求,则需要使用本文介绍的一种新的数据结构——二叉堆。更具体地,可以使用本文将介绍的二叉堆来实现优先级队列,以达到记录插入和删除的最坏时间复杂度均为 l o g ( n ) log(n) log(n)。
一、堆数据结构简介
1. 定义
二叉堆:堆首先是一种特殊的二叉树
T,该二叉树T的每个结点处保存了一条键值对形式的记录,除此之外该二叉树T还具有以下两条性质:
- 堆序性质:如果
p代表堆T任意一个除根结点的结点位置,则对于保存在位置p处的记录,其键大于或等于p的父结点处记录的键;- 完全二叉树性质:堆
T是一个完全二叉树,即如果二叉树的高度为h,则树的第 0 0 0, 1 1 1, 2 2 2, . . . ... ..., h − 1 h-1 h−1层均有 2 i 2^i 2i(其中 0 ≤ i ≤ h − 1 0\le{i}\le{h-1} 0≤i≤h−1)个结点,且第 h h h层的结点都保存在尽量靠左的位置。
实际上,由于根据上述定义,键最小的记录保存在根结点处,因此满足上述定义的二叉堆又叫最小堆(min-heap),本文主要以最小堆为例进行分析。
如果将上述定义中的堆序性质修改为:如果p代表堆T任意一个除根结点的结点位置,则对于保存在位置p处的记录,其键小于或等于p的父结点处的记录的键,则这样的二叉堆称为最大堆(max-heap)。
下面给出一个满足上述最小堆定义的例子:

需要注意的是:
- 堆序性质保证了沿着从根结点开始到叶子结点结束的任意一条路径,路径上每一个位置处的键(非严格)单调递增,且键最小的记录在根结点处;
- 本文所描述的数据结构堆和计算机内存中的堆无任何关系,请读者注意区分;
- 由于数据结构堆实际是一种特殊的完全二叉树,因此本文后续将不区分堆和完全二叉树的概念。
2. 性质
高度:对于保存 n n n条记录的堆
T,其高度为 ⌊ l o g ( n ) ⌋ \lfloor log(n) \rfloor ⌊log(n)⌋,其中 ⌊ x ⌋ \lfloor x \rfloor ⌊x⌋表示对 x x x向下取整。
证明:由于堆T是一个完全二叉树,则其从第 0 0 0层到第 h − 1 h-1 h−1层的结点数目为 1 + 2 + 2 2 + ⋅ ⋅ ⋅ + 2 h − 1 = 2 h − 1 1+2+2^2+\cdot\cdot\cdot+2^{h-1}=2^h-1 1+2+22+⋅⋅⋅+2h−1=2h−1,而第 h h h层的结点数目最少为 1 1 1个,最多为 2 h 2^h 2h个,因此:
( 2 h − 1 ) + 1 ≤ n ≤ ( 2 h − 1 ) + 2 h (2^h-1)+1\le{n}\le(2^h-1)+2^h (2h−1)+1≤n≤(2h−1)+2h
即:
2 h ≤ n ≤ 2 h + 1 − 1 2^h\le{n}\le2^{h+1}-1 2h≤n≤2h+1−1
对上面表达式的左边部分同时两边取对数得 h ≤ l o g ( n ) h\le{log(n)} h≤log(n),对上面表达式右边部分移项后两边取对数再移项后得 h ≥ ( l o g ( n + 1 ) − 1 ) h\ge({log(n+1)-1}) h≥(log(n+1)−1)。
即:
( l o g ( n + 1 ) − 1 ) ≤ h ≤ l o g ( n ) (log(n+1)-1)\le{h}\le{log(n)} (log(n+1)−1)≤h≤log(n)
又由于 h h h为正整数,则必有 h = ⌊ l o g ( n ) ⌋ h=\lfloor log(n) \rfloor h=⌊log(n)⌋。
二、堆数据结构应用
由上述关于堆T的高度性质可知,如果对T进行的修改类操作(如添加、删除类操作)可实现正比于其高度 h h h的时间复杂度,则对于有 n n n条记录的T这写修改类操作的时间复杂度为 l o g ( n ) log(n) log(n)。
自然地,如果可以使用堆T作为保存优先级队列的所有键值对形式记录,则基于此实现的优先级队列,其add()、min()、remove_min()等操作有望实现 l o g ( n ) log(n) log(n)的最坏时间复杂度。
实际上,如果使用堆实现的优先级队列,对于其ADT中的所有方法:
__len__()和is_empty()方法的实现非常简单,仅需返回或判断底层完全二叉树的结点个数属性即可;min()方法的实现也很直接,因为上述堆序性质保证了键最小的记录保存在根结点处;add()和remove_min()两个方法的实现较为复杂,因为要保证在记录条目增删前后仍然保持堆的堆序性质和完全二叉树性质。
因此,下面着重从理论上分析如何基于堆来实现优先级队列的add()和remove_min()两个方法:
1. add(k, v)
首先考虑将键值对形式的记录保存在堆的结点中,但需要注意的是该操作之后需要同时保证堆序性质和完全二叉树性质。
完全二叉树性质保证
为确保不违背完全二叉树性质,add(k, v)方法需要将结点保存在二叉树最底层最右侧结点的右侧紧邻位置或者新一层结点的最左侧位置。
下图以满足上述堆定义的图为例,假设现在需要向其中增加一条键为2,值为'T'的记录(2, 'T'),则图(a)和(b)分别表示执行add(2, 'T')之前和之后(部分)堆的状态:

堆序性质保证
上述步骤虽然确保了满足堆的完全二叉树性质,但是当调用add(k, v)方法之前堆不为空,则有可能仅完成上述步骤将违背堆的堆序性质。原因在于,如果假设插入完全二叉树的结点的位置为p,且该结点的父结点位置为q,则有可能 k p < k q k_p\lt{k_q} kp<kq。
针对上述可能,我们需要交换位置p和q处结点的键值对形式记录,此操作后原本位置p处的记录将上移一层,如果此时完全二叉树已满足堆序性质,则插入操作才算完成,否则交换操作继续。
针对上述分析,有如下图的示例:
- 图(c)和(d)表示继图(b)状态后,完成记录
(20, 'B')和(2, 'T')交换的过程和结果; - 图(e)和(f)、图(g)和(h)分别表示继续进行结点间记录交换的过程和结果。
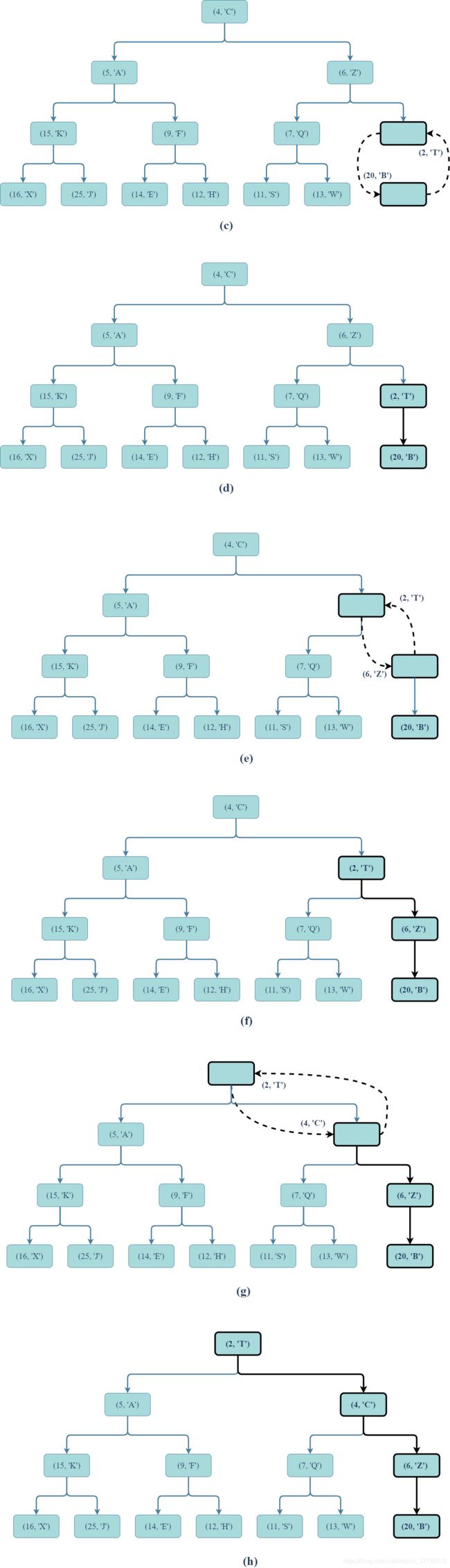
实际上,上述一系列操作也称为自堆底向上冒泡(up-heap bubbling)算法,而且在最坏情况下(如上图所示),此算法将使得新结点处的记录一直被交换至根结点处,此时交换操作的次数为堆的高度即 l o g ( n ) log(n) log(n)( n n n为堆的总结点数)。
2. remove_min()
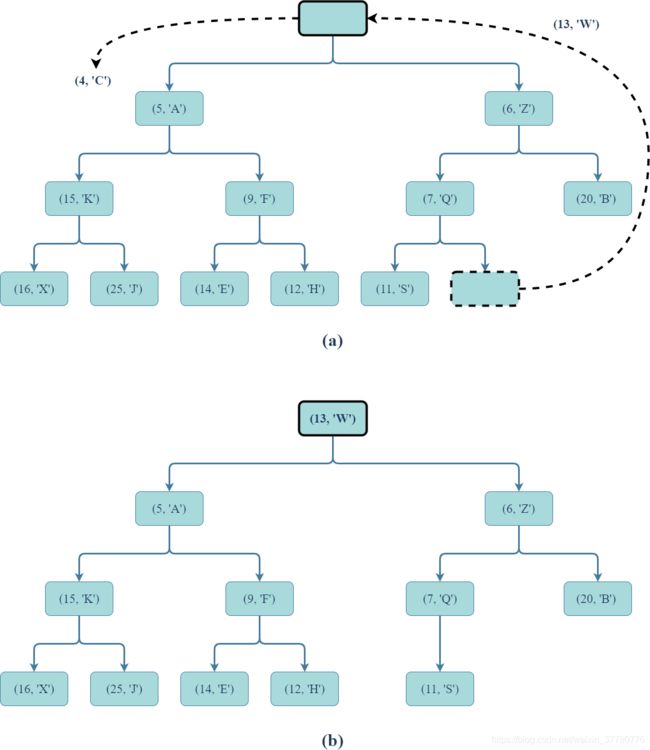
根据堆的定义,使用堆T实现的优先级队列中键最小的记录必然保存在根结点处,但实现remove_min()方法时不能直接将根结点删除,因为此时会形成两个互不相连的子树,即破坏了堆的完全二叉树性质。
完全二叉树性质保证
为解决上述问题,可以:
- 先删除堆最底层最右侧结点并返回保存的记录;
- 然后使用上述返回的记录替换根结点处的记录。
下图为上述操作的示例:
堆序性质保证
完成上述操作后仍存在的问题是,此时树虽然是完全二叉树,但可能并不是堆,因为该二叉树可能不满足堆序性质。
实际上,如果删除堆的最底层最右侧结点后,完全二叉树中:
- 仅有一个结点,则该完全二叉树同时也是堆;
- 不止一个结点,则令
p表示堆T的根结点位置,在以下两种情况下:p只有左子结点,且其位置为c;p有左、右两个子结点,令其键较小的子结点的位置为c。
如果 k p > k c k_p\gt{k_c} kp>kc,则类似上述实现add(k, v),此时完全二叉树不是堆,需要交换位置p和c处的记录直至整个完全二叉树满足堆序性质。下面系列图例表达了这一具体过程:

实际上,与之前自堆底向上冒泡(up-heap bubbling)算法相对,上述过程也称为自堆顶向下冒泡(down-heap bubbling),且类似地该算法的最坏时间复杂度为 l o g ( n ) log(n) log(n)(其中 n n n为堆中元素个数)。
三、堆数据结构实现
1. 实现方式选择
由于堆实际上是一种特殊的二叉树,则你可能第一反应是根据【数据结构Python描述】树的简介、基本概念和手动实现一个二叉树中定义专门的结点类,并以结点的链式方式来实现堆。
实际上,通过上述方式实现堆本身并没有问题,但问题在于本文在开头引出的问题及其解决方案,即本文实现堆的目的是使用堆来进一步实现更加优化的优先级队列(相比于之前使用位置列表实现优先级队列),因此使用基于结点链式结构实现堆有以下主要缺陷:
- 实现起来较为复杂,
- 进一步实现的优先级队列的部分操作时间复杂度高,对于优先级队列的
add()和remove_min()方法,其实现依赖于先找到堆中的最后一个结点,而这对于基于结点链式结构实现的堆来说时间复杂度为 O ( n ) O(n) O(n)。
实际上,除了使用基于结点链式结构来实现二叉树,另一种方式是使用列表作为存储每一个结点元素的容器来实现。
具体地,假设完全二叉树T的所有结点均保存在列表A中,假设函数 f ( p ) f(p) f(p)将结点位置p映射为列表A中的正整数索引,则T中所有结点在列表A中对应的索引为:
- 如果位置
p处为根结点,则 f ( p ) = 0 f(p)=0 f(p)=0; - 如果
p是位置q处结点的左子结点的位置,则 f ( p ) = 2 f ( q ) + 1 f(p)=2f(q)+1 f(p)=2f(q)+1; - 如果
p是位置q处结点的右子结点的位置,则 f ( p ) = 2 f ( q ) + 2 f(p)=2f(q)+2 f(p)=2f(q)+2。
基于上述定义,则将上述满足堆定义的完全二叉树转换为列表存储形式为:

由上述可知:
- 将保存业务元素的结点进行链式存储,其优势是可以较为直观地体现完全二叉树的结构,劣势是访问任意结点的遍历较为耗时;
- 将完全二叉树各个结点的业务元素保存在列表中,其优势是根据列表索引访问任意结点的业务元素,劣势是完全二叉树的结构是隐式的。
2. 数据结构实现
下面结合上述理论分析,继承优先级队列抽象基类PriorityQueueBase,通过使用普通列表作为堆中结点的存储容器,进而使用堆保存键值对形式记录,实现高效的优先级队列HeapPriorityQueue。
2.1 堆的ADT
下面是堆的常用ADT方法,需要注意的是所有方法均为非公共方法,因为本文最终目的是实现一个面向用户的高效优先级队列,而用户无需了解或使用底层的堆是如何实现的。
| 方法名称 | 方法描述 |
|---|---|
_parent(j) |
对于堆T,如果其某结点处的业务元素保存在列表的索引j处,返回其父结点处业务元素在列表中的索引。 |
_left(j) |
对于堆T,如果其某结点处的业务元素保存在列表的索引j处,返回其左子结点处业务元素在列表中的索引。 |
_right(j) |
对于堆T,如果其某结点处的业务元素保存在列表的索引j处,返回其右子结点处业务元素在列表中的索引。 |
_has_left(j) |
对于堆T,如果其某结点处的业务元素保存在列表的索引j处,如果该结点有左子结点则返回True,否则返回False。 |
_has_right(j) |
对于堆T,如果其某结点处的业务元素保存在列表的索引j处,如果该结点有右子结点则返回True,否则返回False。 |
_swap(i, j) |
对于完全二叉树T,假设其一对父子结点的业务元素分别保存在列表的索引i和j处,如果父子结点的业务元素违背了堆序性质则交换这对结点的业务元素。 |
_upheap(j) |
自堆底向上冒泡(up-heap bubbling)算法实现。 |
_downheap(j) |
自堆顶向下冒泡(up-heap bubbling)算法实现。 |
2.2 堆方法实现
_parent()
根据堆中子结点和其父结点的业务元素在列表中的索引关系可得:
def _parent(self, j):
"""
返回父结点处业务元素在列表中的索引
:param j: 任意结点处的业务元素在列表中的索引
:return: 父结点处业务元素在列表中的索引
"""
return (j - 1) // 2
_left()
该方法实现类似_parent()方法:
def _left(self, j):
"""
返回左子结点处业务元素在列表中的索引
:param j: 任意结点处的业务元素在列表中的索引
:return: 左子结点处业务元素在列表中的索引
"""
return 2 * j + 1
_right()
该方法实现类似_parent()方法:
def _right(self, j):
"""
返回右子结点处业务元素在列表中的索引
:param j: 任意结点处的业务元素在列表中的索引
:return: 右子结点处业务元素在列表中的索引
"""
return 2 * j + 1
_has_left()
该方法实现依赖于_left()方法:
def _has_left(self, j):
"""
如结点有左子结点则返回True,否则返回False
:param j: 任意结点处的业务元素在列表中的索引
:return: 判断结点是否有左子结点的Boolean结果
"""
return self._left(j) < len(self._data) # 确保列表索引不越界
_has_right()
该方法实现依赖于_right()方法:
def _has_right(self, j):
"""
如结点有右子结点则返回True,否则返回False
:param j: 任意结点处的业务元素在列表中的索引
:return: 判断结点是否有右子结点的Boolean结果
"""
return self._right(j) < len(self._data) # 确保列表索引不越界
_swap()
实现该方法仅需交换列表两个索引处的业务元素即可:
def _swap(self, i, j):
"""
交换一对父子结点的业务元素
:param i: 业务元素在列表中的索引
:param j: 业务元素在列表中的索引
:return: None
"""
self._data[i], self._data[j] = self._data[j], self._data[i]
_upheap()
该方法实现遵照本文前述理论分析以确保向堆中插入新业务元素后不破坏其堆序性质:
def _upheap(self, j):
"""
自堆底向上冒泡算法
:param j: 堆底结点处业务元素在列表中的索引
:return: None
"""
parent = self._parent(j)
if j > 0 and self._data[j] < self._data[parent]:
self._swap(j, parent)
self._upheap(parent) # 递归调用
_downheap()
该方法实现遵照本文前述理论分析以确保删除堆中根结点业务元素后不破坏其堆序性质:
def _downheap(self, j):
"""
自堆顶向下冒泡算法
:param j: 结点处业务元素在列表中的索引
:return: None
"""
if self._has_left(j):
left = self._left(j)
small_child = left
# 如果有左、右两个子结点,令small_child引用键较小子结点的业务元素在列表中的索引
if self._has_right(j):
right = self._right(j)
if self._data[right] < self._data[left]:
small_child = right
# 至少根结点有左子结点时,才有可能self虽然是完全二叉树但不是堆
if self._data[small_child] < self._data[j]:
self._swap(j, small_child)
self._downheap(small_child) # 递归调用
2.3 优先级队列方法实现
下面基于上述堆的各ADT方法实现优先级队列:
__init__()
实现初始化方法仅需指定用于保存优先级队列记录的容器的空列表:
def __init__(self):
"""将创建的优先级队列初始化为空"""
self._data = list()
__len__()
实现该方法仅需返回列表长度即可:
def __len__(self):
"""返回优先级队列中的记录条目数"""
return len(self._data)
add(k, v)
实现该方法需要:
- 先将新键值对封装为记录对象后追加至列表尾部;
- 然后调用自堆底向上冒泡算法的实现
_upheap()确保完全二叉树满足堆序性质。
def add(self, key, value):
"""向优先级队列中插入一条key-value记录"""
self._data.append(self._Item(key, value)) # 新记录条目插入并确保完全二叉树性质
self._upheap(len(self._data) - 1) # 确保满足堆序性质
min()
实现该方法仅需返回根结点处的键值对即可:
def min(self):
"""返回(但不删除)优先级队列中键最小的记录,如优先级队列此时为空则抛出异常"""
if self.is_empty():
raise Empty('优先级队列为空!')
item = self._data[0]
return item.key, item.value
remove_min()
实现该方法需要:
- 先判断优先级队列是否为空;
- 其次交换根结点和堆最底层最右侧结点处记录;
- 然后删除堆最底层最右侧结点,并保存该结点处记录(经上述交换操作后,此记录的键为堆中最小的);
- 再调用自堆顶向下冒泡算法的实现
_downheap()确保经过交换操作后完全二叉树满足堆序性质; - 最后返回键最小记录的键和值。
def remove_min(self):
"""回并删除优先级队列中键最小的记录,如优先级队列此时为空则抛出异常"""
if self.is_empty():
raise Empty('优先级队列为空!')
self._swap(0, len(self._data) - 1) # 将根结点处键最小记录交换至完全二叉树最底层最右侧结点处
item = self._data.pop()
self._downheap(0) # 确保完全二叉树满足堆序性质,即确定需保存在根结点处的键最小记录
return item.key, item.value
2.4 基于堆的优先级队列方法复杂度分析
针对基于堆实现的优先级队列,其ADT方法的时间复杂度如下表所示,其中 n n n表示方法执行时优先级队列中记录条目数:
| 方法名称 | 时间复杂度 |
|---|---|
__len__() |
O ( 1 ) O(1) O(1) |
is_empty() |
O ( 1 ) O(1) O(1) |
min() |
O ( 1 ) O(1) O(1) |
add() |
O ( l o g ( n ) ) O(log(n)) O(log(n))1 |
remove_min() |
O ( l o g ( n ) ) O(log(n)) O(log(n))1 |
实际上,上述表格的分析基于以下事实:
- 堆
T具有 n n n个结点,每个结点保存一个键值对的引用; - 堆
T的高度为 l o g ( n ) log(n) log(n),因为T为完全二叉树; min()方法的最坏时间复杂度为 O ( 1 ) O(1) O(1),因为根结点保存了键最小的记录;- 实现
add()和remove_min()方法需要找到键最小的记录,对于基于列表实现的堆和结点链式存储的堆,该操作的时间复杂度分别为 O ( 1 ) O(1) O(1)和 O ( l o g ( n ) ) O(log(n)) O(log(n)); - 在最坏情况下,自堆底向上冒泡和自堆顶向下冒泡的次数等于堆的高度。
至此,我们实现了本文开头期望的均能高效执行增(add(k, v))、删(remove_min())、查(min())操作的优先级队列。
四、完整测试代码
完整测试代码如下,其中使用了【数据结构Python描述】优先级队列简介及Python手工实现中的优先级队列抽象基类PriorityQueueBase:
# heap_priority_queue.py
from priority_queue import PriorityQueueBase
class Empty(Exception):
"""尝试对空优先级队列进行删除操作时抛出的异常"""
pass
class HeapPriorityQueue(PriorityQueueBase):
"""使用堆存储键值对形式记录的优先级队列"""
def __init__(self):
"""将创建的优先级队列初始化为空"""
self._data = list()
def _parent(self, j):
"""
返回父结点处业务元素在列表中的索引
:param j: 任意结点处的业务元素在列表中的索引
:return: 父结点处业务元素在列表中的索引
"""
return (j - 1) // 2
def _left(self, j):
"""
返回左子结点处业务元素在列表中的索引
:param j: 任意结点处的业务元素在列表中的索引
:return: 左子结点处业务元素在列表中的索引
"""
return 2 * j + 1
def _right(self, j):
"""
返回右子结点处业务元素在列表中的索引
:param j: 任意结点处的业务元素在列表中的索引
:return: 右子结点处业务元素在列表中的索引
"""
return 2 * j + 2
def _has_left(self, j):
"""
如结点有左子结点则返回True,否则返回False
:param j: 任意结点处的业务元素在列表中的索引
:return: 判断结点是否有左子结点的Boolean结果
"""
return self._left(j) < len(self._data) # 确保列表索引不越界
def _has_right(self, j):
"""
如结点有右子结点则返回True,否则返回False
:param j: 任意结点处的业务元素在列表中的索引
:return: 判断结点是否有右子结点的Boolean结果
"""
return self._right(j) < len(self._data) # 确保列表索引不越界
def _swap(self, i, j):
"""
交换一对父子结点的业务元素
:param i: 业务元素在列表中的索引
:param j: 业务元素在列表中的索引
:return: None
"""
self._data[i], self._data[j] = self._data[j], self._data[i]
def _upheap(self, j):
"""
自堆底向上冒泡算法
:param j: 结点处业务元素在列表中的索引
:return: None
"""
parent = self._parent(j)
if j > 0 and self._data[j] < self._data[parent]:
self._swap(j, parent)
self._upheap(parent) # 递归调用
def _downheap(self, j):
"""
自堆顶向下冒泡算法
:param j: 结点处业务元素在列表中的索引
:return: None
"""
if self._has_left(j):
left = self._left(j)
small_child = left
# 如果有左、右两个子结点,令small_child引用键较小子结点的业务元素在列表中的索引
if self._has_right(j):
right = self._right(j)
if self._data[right] < self._data[left]:
small_child = right
# 至少根结点有左子结点时,才有可能self虽然是完全二叉树但不是堆
if self._data[small_child] < self._data[j]:
self._swap(j, small_child)
self._downheap(small_child) # 递归调用
def __len__(self):
"""返回优先级队列中的记录条目数"""
return len(self._data)
def __iter__(self):
"""生成优先级队列中所有记录的一个迭代"""
for each in self._data:
yield each
def add(self, key, value):
"""向优先级队列中插入一条key-value记录"""
self._data.append(self._Item(key, value)) # 新记录条目插入并确保完全二叉树性质
self._upheap(len(self._data) - 1) # 确保满足堆序性质
def min(self):
"""返回(但不删除)优先级队列中键最小的记录,如优先级队列此时为空则抛出异常"""
if self.is_empty():
raise Empty('优先级队列为空!')
item = self._data[0]
return item.key, item.value
def remove_min(self):
"""回并删除优先级队列中键最小的记录,如优先级队列此时为空则抛出异常"""
if self.is_empty():
raise Empty('优先级队列为空!')
self._swap(0, len(self._data) - 1) # 将根结点处键最小记录交换至完全二叉树最底层最右侧结点处
item = self._data.pop()
self._downheap(0) # 确保完全二叉树满足堆序性质,即确定需保存在根结点处的键最小记录
return item.key, item.value
if __name__ == '__main__':
heap_queue = HeapPriorityQueue()
print(heap_queue.is_empty()) # True
heap_queue.add(4, 'C')
heap_queue.add(6, 'Z')
heap_queue.add(7, 'Q')
heap_queue.add(5, 'A')
print(heap_queue) # [(4, 'C'), (5, 'A'), (7, 'Q'), (6, 'Z')]
heap_queue.add(2, 'T')
print(heap_queue) # [(2, 'T'), (4, 'C'), (7, 'Q'), (6, 'Z'), (5, 'A')]
print(heap_queue.remove_min()) # (2, 'T')
print(heap_queue.remove_min()) # (4, 'C')
print(heap_queue) # [(5, 'A'), (6, 'Z'), (7, 'Q')]
print(heap_queue.min()) # (5, 'A')
print(heap_queue.is_empty()) # False
经摊销后的时间复杂度。 ↩︎ ↩︎