以前做 DBA 时,常用 DR 模式。LB 只处理进入的请求,将流量分发给后端,返回数据由 Real Server 直接返回到 Client, 所以模式叫 Direct Routing. 原理大家都清楚,修改二层头 mac 地址,所以他的局限也很明显,只能在同一个二层,不能跨网段。由于直接返回给 Client,一般不会面对公网用户。那么具体实现细节呢?
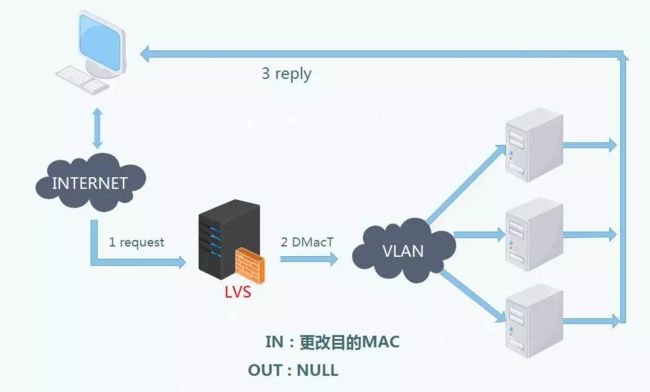
转发入口
上一篇提到,dpvs 每个 slave 核心处于轮循状态,执行三个 LOOP JOB. 最核心的就是 lcore_job_recv_fwd
static void lcore_job_recv_fwd(void *arg)
{
int i, j;
portid_t pid;
lcoreid_t cid;
struct netif_queue_conf *qconf;
cid = rte_lcore_id();
assert(LCORE_ID_ANY != cid);
// 一个核可能负责多个网卡的多个队列,所以是两个 for
// i 是指网卡号 j 是指 第 i 个网卡的第 j 的队列
for (i = 0; i < lcore_conf[lcore2index[cid]].nports; i++) {
pid = lcore_conf[lcore2index[cid]].pqs[i].id;
assert(pid <= bond_pid_end);
for (j = 0; j < lcore_conf[lcore2index[cid]].pqs[i].nrxq; j++) {
qconf = &lcore_conf[lcore2index[cid]].pqs[i].rxqs[j];
// 先从 ring 里拿数据,如果有就处理
lcore_process_arp_ring(qconf, cid);
// 再从 网卡 里拿数据
qconf->len = netif_rx_burst(pid, qconf);
lcore_stats_burst(&lcore_stats[cid], qconf->len);
lcore_process_packets(qconf, qconf->mbufs, cid, qconf->len, 0);
kni_send2kern_loop(pid, qconf);
}
}
}
这里面为什么是两个 for 呢?因为一个 lcore 核心可能负责多个网卡,每个网卡又负责多个列队。理想情况肯定是一个核只处理一个网卡的一个列队。
-
lcore_process_arp_ring先检查全局 arp_ring 环形数组是否有数据,如果有就处理。 -
netif_rx_burst是接收网卡数据的核心函数
static inline uint16_t netif_rx_burst(portid_t pid, struct netif_queue_conf *qconf)
{
struct rte_mbuf *mbuf;
int nrx = 0;
if (qconf->isol_rxq) {
/* note API rte_ring_dequeue_bulk of dpdk-16.07 is not suitable, replace with
* its bulk version after upgrading to new dpdk version */
while (0 == rte_ring_dequeue(qconf->isol_rxq->rb, (void**)&mbuf)) {
qconf->mbufs[nrx++] = mbuf;
if (unlikely(nrx >= NETIF_MAX_PKT_BURST))
break;
}
/* Shoul we integrate statistics of isolated recieve lcore into packet
* processing lcore ? No! we just leave the work to tools */
} else {
nrx = rte_eth_rx_burst(pid, qconf->id, qconf->mbufs, NETIF_MAX_PKT_BURST);
}
qconf->len = nrx;
return nrx;
}
先判断当前队列是否专职接收数据,如果是的话,将数据从 ring_buffer 取出放到
qconf->mbufs 供下文处理。否则调用 dpdk 库函数 rte_eth_rx_burst 将网卡数据取出放到 qconf->mbufs 中。
-
lcore_stats_burst统计函数,暂时忽略。 -
lcore_process_packets核心包处理入口,下文分件。 -
kni_send2kern_loop如果当前网卡数据,dpvs 不关心,那么通过 kni 接口透传到内核。比如一些 ssh 管理流量。
lcore_process_packets 二层包处理入口
这里涉及到了 dpdk 核心数据结构 mbuf, 可以类比内核的 skb, 很多二层三层的 header 转换操作都是基于 mbuf
static void lcore_process_packets(struct netif_queue_conf *qconf, struct rte_mbuf **mbufs,
lcoreid_t cid, uint16_t count, bool pkts_from_ring)
{
int i, t;
struct ether_hdr *eth_hdr;
struct rte_mbuf *mbuf_copied = NULL;
/* prefetch packets 预取一定数量的 mbuf*/
for (t = 0; t < count && t < NETIF_PKT_PREFETCH_OFFSET; t++)
rte_prefetch0(rte_pktmbuf_mtod(mbufs[t], void *));
rte_pktmbuf_mtod 预取一定数量数据包
/* L2 filter */
for (i = 0; i < count; i++) {
struct rte_mbuf *mbuf = mbufs[i];
struct netif_port *dev = netif_port_get(mbuf->port);
获取每个数据包对应的网卡信息,dpdk 中网卡叫 port
if (unlikely(!dev)) {
rte_pktmbuf_free(mbuf);
lcore_stats[cid].dropped++;
continue;
}
if (dev->type == PORT_TYPE_BOND_SLAVE) {
dev = dev->bond->slave.master;
mbuf->port = dev->id;
}
兼容处理网卡是 bond 的情况
if (t < count) {
rte_prefetch0(rte_pktmbuf_mtod(mbufs[t], void *));
t++;
}
如果包没有,那么去获取
eth_hdr = rte_pktmbuf_mtod(mbuf, struct ether_hdr *);
/* reuse mbuf.packet_type, it was RTE_PTYPE_XXX */
mbuf->packet_type = eth_type_parse(eth_hdr, dev);
获得以太网头,并判断当前二层包类型,本机 ETH_PKT_HOST、 广播或组播,一般都是本机
/*
* In NETIF_PORT_FLAG_FORWARD2KNI mode.
* All packets received are deep copied and sent to KNI
* for the purpose of capturing forwarding packets.Since the
* rte_mbuf will be modified in the following procedure,
* we should use mbuf_copy instead of rte_pktmbuf_clone.
*/
if (dev->flag & NETIF_PORT_FLAG_FORWARD2KNI) {
if (likely(NULL != (mbuf_copied = mbuf_copy(mbuf,
pktmbuf_pool[dev->socket]))))
kni_ingress(mbuf_copied, dev, qconf);
else
RTE_LOG(WARNING, NETIF, "%s: Failed to copy mbuf\n",
__func__);
}
kni 模式所有的包都要透传到内核,深考贝一份,kni_ingress 以后单独说,这里忽略
/*
* handle VLAN
* if HW offload vlan strip, it's still need vlan module
* to act as VLAN filter.
*/
if (eth_hdr->ether_type == htons(ETH_P_8021Q) ||
mbuf->ol_flags & PKT_RX_VLAN_STRIPPED) {
if (vlan_rcv(mbuf, netif_port_get(mbuf->port)) != EDPVS_OK) {
rte_pktmbuf_free(mbuf);
lcore_stats[cid].dropped++;
continue;
}
兼容处理 vlan 的情况,这里忽略,暂时不看
dev = netif_port_get(mbuf->port);
if (unlikely(!dev)) {
rte_pktmbuf_free(mbuf);
lcore_stats[cid].dropped++;
continue;
}
eth_hdr = rte_pktmbuf_mtod(mbuf, struct ether_hdr *);
}
/* handler should free mbuf */
netif_deliver_mbuf(mbuf, eth_hdr->ether_type, dev, qconf,
(dev->flag & NETIF_PORT_FLAG_FORWARD2KNI) ? true:false,
cid, pkts_from_ring);
lcore_stats[cid].ibytes += mbuf->pkt_len;
lcore_stats[cid].ipackets++;
}
}
最后就是数据包转发函数 netif_deliver_mbuf
二层处理 mbuf
分段看一下 netif_deliver_mbuf 如何实现
static inline int netif_deliver_mbuf(struct rte_mbuf *mbuf,
uint16_t eth_type,
struct netif_port *dev,
struct netif_queue_conf *qconf,
bool forward2kni,
lcoreid_t cid,
bool pkts_from_ring)
{
struct pkt_type *pt;
int err;
uint16_t data_off;
assert(mbuf->port <= NETIF_MAX_PORTS);
assert(dev != NULL);
pt = pkt_type_get(eth_type, dev);
if (NULL == pt) { // pt 为空说明没有对应协义的处理
// 如果没有转发过,那么 转发到 kni
if (!forward2kni)
kni_ingress(mbuf, dev, qconf);
else
rte_pktmbuf_free(mbuf);
return EDPVS_OK;
}
二层的包要么是 arp, 要么是 ip 包,根据 pkt_type_get 来获取处理结构体,算是工厂方法吧。这个 pt 由 netif_register_pkt 注册,查看源码可知,当前仅有两种类型工厂 ip4_pkt_type 和 arp_pkt_type,暂不支持 ipv6. 如果 pt 不存在,那么流量通过 kni 透传或是直接丢弃。
/*clone arp pkt to every queue*/ // 为什么这么搞?所有的 ARP 都要广播到所有 queue?
if (pt->type == rte_cpu_to_be_16(ETHER_TYPE_ARP) && !pkts_from_ring) {
struct rte_mempool *mbuf_pool;
struct rte_mbuf *mbuf_clone;
uint8_t i;
struct arp_hdr *arp;
unsigned socket_id;
socket_id = rte_socket_id();
mbuf_pool = pktmbuf_pool[socket_id];
rte_pktmbuf_adj(mbuf, sizeof(struct ether_hdr));
arp = rte_pktmbuf_mtod(mbuf, struct arp_hdr *);
rte_pktmbuf_prepend(mbuf,(uint16_t)sizeof(struct ether_hdr));
if (rte_be_to_cpu_16(arp->arp_op) == ARP_OP_REPLY) {
for (i = 0; i < DPVS_MAX_LCORE; i++) {
if ((i == cid) || (!is_lcore_id_fwd(i))
|| (i == rte_get_master_lcore()))
continue;
/*rte_pktmbuf_clone will not clone pkt.data, just copy pointer!*/
mbuf_clone = rte_pktmbuf_clone(mbuf, mbuf_pool);
if (mbuf_clone) {
int ret = rte_ring_enqueue(arp_ring[i], mbuf_clone);
if (unlikely(-EDQUOT == ret)) {
RTE_LOG(WARNING, NETIF, "%s: arp ring of lcore %d quota exceeded\n",
__func__, i);
}
else if (ret < 0) {
RTE_LOG(WARNING, NETIF, "%s: arp ring of lcore %d enqueue failed\n",
__func__, i);
rte_pktmbuf_free(mbuf_clone);
}
}
}
}
}
如果是 arp 类型的包,复制拷到所有队列。这块为什么这么处理呢?猜测,dpdk 程序是每个核都有本地变量,无锁的,所以邻居子系统也要每个核都是全量的。后面再验证吧。
mbuf->l2_len = sizeof(struct ether_hdr);
/* Remove ether_hdr at the beginning of an mbuf */
data_off = mbuf->data_off;
if (unlikely(NULL == rte_pktmbuf_adj(mbuf, sizeof(struct ether_hdr))))
return EDPVS_INVPKT;
调整 mbuf 指向三层 ip 层
err = pt->func(mbuf, dev);
这是核心的三层处理逻辑,通过阅读 pkt_type_get, 发现这里回调 ipv4_rcv
if (err == EDPVS_KNICONTINUE) {
if (pkts_from_ring || forward2kni) {
rte_pktmbuf_free(mbuf);
return EDPVS_OK;
}
if (likely(NULL != rte_pktmbuf_prepend(mbuf,
(mbuf->data_off - data_off)))) {
kni_ingress(mbuf, dev, qconf);
} else {
rte_pktmbuf_free(mbuf);
}
}
return EDPVS_OK;
}
有时数据包不是 dpvs 所关心的,那么通过 kni 透传给内核
三层处理 ipv4_rcv
static int ipv4_rcv(struct rte_mbuf *mbuf, struct netif_port *port)
{
struct ipv4_hdr *iph;
uint16_t hlen, len;
eth_type_t etype = mbuf->packet_type; /* FIXME: use other field ? */
assert(mbuf);
if (unlikely(etype == ETH_PKT_OTHERHOST || !port)) {
rte_pktmbuf_free(mbuf);
return EDPVS_DROP;
}
判断包类型是否是本地的,不是就丢弃
IP4_UPD_PO_STATS(in, mbuf->pkt_len);
if (mbuf_may_pull(mbuf, sizeof(struct ipv4_hdr)) != 0)
goto inhdr_error;
确保包是有效的,至少得有 ip 头
iph = ip4_hdr(mbuf); // l3 header
hlen = ip4_hdrlen(mbuf);
if (((iph->version_ihl) >> 4) != 4 || hlen < sizeof(struct ipv4_hdr))
goto inhdr_error;
if (mbuf_may_pull(mbuf, hlen) != 0)
goto inhdr_error;
有了 ip 头,ip 数据包也得是有效的
if (unlikely(!(port->flag & NETIF_PORT_FLAG_RX_IP_CSUM_OFFLOAD))) {
if (unlikely(rte_raw_cksum(iph, hlen) != 0xFFFF))
goto csum_error;
}
CSUM 计算,如果网卡硬件不带计算功能,那么程序调用 rte_raw_cksum 计算
len = ntohs(iph->total_length);
if (mbuf->pkt_len < len) {
IP4_INC_STATS(intruncatedpkts);
goto drop;
} else if (len < hlen)
goto inhdr_error;
/* trim padding if needed */
if (mbuf->pkt_len > len) {
if (rte_pktmbuf_trim(mbuf, mbuf->pkt_len - len) != 0) {
IP4_INC_STATS(indiscards);
goto drop;
}
}
mbuf->userdata = NULL;
mbuf->l3_len = hlen;
#ifdef CONFIG_DPVS_IPV4_DEBUG
ip4_dump_hdr(iph, mbuf->port);
#endif
return INET_HOOK(INET_HOOK_PRE_ROUTING, mbuf, port, NULL, ipv4_rcv_fin);
csum_error:
IP4_INC_STATS(csumerrors);
inhdr_error:
IP4_INC_STATS(inhdrerrors);
drop:
rte_pktmbuf_free(mbuf);
return EDPVS_INVPKT;
}
最后调用 INET_HOOK(INET_HOOK_PRE_ROUTING, mbuf, port, NULL, ipv4_rcv_fin) 先调用 INET_HOOK_PRE_ROUTING 这个钩子所注册的回调,然后根据返回值判断是否走 ipv4_rcv_fin,不同转发模式行为是不同的。
三层钩子入口 INET_HOOK
int INET_HOOK(unsigned int hook, struct rte_mbuf *mbuf,
struct netif_port *in, struct netif_port *out,
int (*okfn)(struct rte_mbuf *mbuf))
{
struct list_head *hook_list;
struct inet_hook_ops *ops;
struct inet_hook_state state;
int verdict = INET_ACCEPT;
state.hook = hook;
hook_list = &inet_hooks[hook];
获取 INET_HOOK_PRE_ROUTING 对应的钩子回调函数数组
#ifdef CONFIG_DPVS_IPV4_INET_HOOK
rte_rwlock_read_lock(&inet_hook_lock);
#endif
ops = list_entry(hook_list, struct inet_hook_ops, list);
if (!list_empty(hook_list)) {
verdict = INET_ACCEPT;
list_for_each_entry_continue(ops, hook_list, list) {
repeat:
verdict = ops->hook(ops->priv, mbuf, &state);
if (verdict != INET_ACCEPT) {
if (verdict == INET_REPEAT)
goto repeat;
break;
}
}
}
遍历回调函数数组,并执行。根据返回值来判断是否全部执行,这里细节比较多,稍后再说。
#ifdef CONFIG_DPVS_IPV4_INET_HOOK
rte_rwlock_read_unlock(&inet_hook_lock);
#endif
if (verdict == INET_ACCEPT || verdict == INET_STOP) {
return okfn(mbuf);
} else if (verdict == INET_DROP) {
rte_pktmbuf_free(mbuf);
return EDPVS_DROP;
} else { /* INET_STOLEN */
return EDPVS_OK;
}
}
根据返回值 verdict 判断后续操作,比如 synproxy 第一步处理就会返回 INET_STOLEN,如果 INET_ACCEPT 执行 okfn 所指向的 ipv4_rcv_fin,不同模式不同阶段的值不同
三层钩子 INET_HOOK_PRE_ROUTING
了解 linux iptables 的都知道,tcp 协义栈各种 hook 钩子。dpvs 自实现的也有,不过很精简,先看一下 INET_HOOK_PRE_ROUTING 都注册了哪些回调。
static struct inet_hook_ops dp_vs_ops[] = {
{
.hook = dp_vs_in,
.hooknum = INET_HOOK_PRE_ROUTING,
.priority = 100,
},
{
.hook = dp_vs_pre_routing,
.hooknum = INET_HOOK_PRE_ROUTING,
.priority = 99,
},
};
查看 ip_vs_core.c dp_vs_init 会注册这个钩子,注意权重值 priority, 查看注册函数 ipv4_register_hooks 意思是值越小的越先执行。那么本次回调,先执行 dp_vs_pre_routing,再执行 dp_vs_in
三层钩子回调 dp_vs_pre_routing
static int dp_vs_pre_routing(void *priv, struct rte_mbuf *mbuf,
const struct inet_hook_state *state)
{
struct dp_vs_iphdr iph;
int af;
struct dp_vs_service *svc;
af = AF_INET;
// 填充四层失败,还要返回 ACCEPT?
if (EDPVS_OK != dp_vs_fill_iphdr(af, mbuf, &iph))
return INET_ACCEPT;
/* Drop all ip fragment except ospf */
if ((af == AF_INET) && ip4_is_frag(ip4_hdr(mbuf))
&& (iph.proto != IPPROTO_OSPF)) {
dp_vs_estats_inc(DEFENCE_IP_FRAG_DROP);
return INET_DROP;
}
/* Drop udp packet which send to tcp-vip */
if (g_defence_udp_drop && IPPROTO_UDP == iph.proto) {
if ((svc = dp_vs_lookup_vip(af, IPPROTO_UDP, &iph.daddr)) == NULL) {
if ((svc = dp_vs_lookup_vip(af, IPPROTO_TCP, &iph.daddr)) != NULL) {
dp_vs_estats_inc(DEFENCE_UDP_DROP);
return INET_DROP;
}
}
}
/* Synproxy: defence synflood */
if (IPPROTO_TCP == iph.proto) {
int v = INET_ACCEPT;
if (0 == dp_vs_synproxy_syn_rcv(af, mbuf, &iph, &v))
return v;
}
return INET_ACCEPT;
}
这里有个最重要的功能是 syn_proxy,后文再细讲,目前只用在 nat、full-nat 模式下
三层钩子回调 dp_vs_in
dp_vs_in 开始进入 lvs 模块,之前的都是前戏。这块代码非常复杂,简单说,对于存在的 proxy 连接,判断方向(client -> LB 或是 rs -> LB),直接发送流量。新来的请求,查找 virtual server,根据 LB 算法查找对应后端 real server,建立连接,并保存这个会话,大并发时这个会话非常庞大。这里细节也非常多。
static int dp_vs_in(void *priv, struct rte_mbuf *mbuf,
const struct inet_hook_state *state)
{
struct dp_vs_iphdr iph;
struct dp_vs_proto *prot;
struct dp_vs_conn *conn;
int dir, af, verdict, err, related;
bool drop = false;
eth_type_t etype = mbuf->packet_type; /* FIXME: use other field ? */
assert(mbuf && state);
/* cannot use mbuf->l3_type which is conflict with m.packet_type
* or using wrapper to avoid af check here */
/* af = mbuf->l3_type == htons(ETHER_TYPE_IPv4) ? AF_INET : AF_INET6; */
af = AF_INET;
if (unlikely(etype != ETH_PKT_HOST))
return INET_ACCEPT;
数据包不是发往本机的,那么返回。这里为什么不是 drop 呢?
if (dp_vs_fill_iphdr(af, mbuf, &iph) != EDPVS_OK)
return INET_ACCEPT;
if (unlikely(iph.proto == IPPROTO_ICMP)) {
/* handle related ICMP error to existing conn */
verdict = dp_vs_in_icmp(mbuf, &related);
if (related || verdict != INET_ACCEPT)
return verdict;
/* let unrelated and valid ICMP goes down,
* may implement ICMP fwd in the futher. */
}
处理 ICMP 消息,暂时不看,只关注 tcp4 主流程
prot = dp_vs_proto_lookup(iph.proto);
if (unlikely(!prot))
return INET_ACCEPT;
查找四层处理协义,目前实现了 tcp、udp、icmp 三种
/*
* Defrag ipvs-forwarding TCP/UDP is not supported for some reasons,
*
* - RSS/flow-director do not support TCP/UDP fragments, means it's
* not able to direct frags to same lcore as original TCP/UDP packets.
* - per-lcore conn table will miss if frags reachs wrong lcore.
*
* If we redirect frags to "correct" lcore, it may cause performance
* issue. Also it need to understand RSS algorithm. Moreover, for the
* case frags in same flow are not occur in same lcore, a global lock is
* needed, which is not a good idea.
*/
if (ip4_is_frag(ip4_hdr(mbuf))) {
RTE_LOG(DEBUG, IPVS, "%s: frag not support.\n", __func__);
return INET_DROP;
}
划重点,这里涉及 dpvs 核心优化 fdir,以后单独讲
/* packet belongs to existing connection ? */
conn = prot->conn_lookup(prot, &iph, mbuf, &dir, false, &drop);
根据不同四层协义,调用 conn_lookup 函数查找会话。有可能会 drop 掉。dir 是设置数据流方向,从 client 到 LB,还是从 real server 到 LB
if (unlikely(drop)) {
RTE_LOG(DEBUG, IPVS, "%s: deny ip try to visit.\n", __func__);
return INET_DROP;
}
// 如果没找到,那么调用 conn_sched 去和 real server 连接
if (unlikely(!conn)) {
/* try schedule RS and create new connection */
if (prot->conn_sched(prot, &iph, mbuf, &conn, &verdict) != EDPVS_OK) {
/* RTE_LOG(DEBUG, IPVS, "%s: fail to schedule.\n", __func__); */
return verdict;
}
/* only SNAT triggers connection by inside-outside traffic. */
if (conn->dest->fwdmode == DPVS_FWD_MODE_SNAT)
dir = DPVS_CONN_DIR_OUTBOUND;
else
dir = DPVS_CONN_DIR_INBOUND;
}
对于新建立的连接,肯定是没有会话的。conn_sched 根据请求选择一个后端 real server 建立连接。
if (conn->flags & DPVS_CONN_F_SYNPROXY) {
if (dir == DPVS_CONN_DIR_INBOUND) {
/* Filter out-in ack packet when cp is at SYN_SENT state.
* Drop it if not a valid packet, store it otherwise */
if (0 == dp_vs_synproxy_filter_ack(mbuf, conn, prot,
&iph, &verdict)) {
dp_vs_stats_in(conn, mbuf);
dp_vs_conn_put(conn);
return verdict;
}
/* "Reuse" synproxy sessions.
* "Reuse" means update syn_proxy_seq struct
* and clean ack_mbuf etc. */
if (0 != dp_vs_synproxy_ctrl_conn_reuse) {
if (0 == dp_vs_synproxy_reuse_conn(af, mbuf, conn, prot,
&iph, &verdict)) {
dp_vs_stats_in(conn, mbuf);
dp_vs_conn_put(conn);
return verdict;
}
}
} else {
/* Syn-proxy 3 logic: receive syn-ack from rs */
if (dp_vs_synproxy_synack_rcv(mbuf, conn, prot,
ip4_hdrlen(mbuf), &verdict) == 0) {
dp_vs_stats_out(conn, mbuf);
dp_vs_conn_put(conn);
return verdict;
}
}
}
特殊处理 syn proxy
if (prot->state_trans) {
err = prot->state_trans(prot, conn, mbuf, dir);
if (err != EDPVS_OK)
RTE_LOG(WARNING, IPVS, "%s: fail to trans state.", __func__);
}
conn->old_state = conn->state;
tcp 状态转移,这个很好理解
/* holding the conn, need a "put" later. */
if (dir == DPVS_CONN_DIR_INBOUND)
return xmit_inbound(mbuf, prot, conn);
else
return xmit_outbound(mbuf, prot, conn);
}
根据流量方向 dir,来选择如何写数据。
dp_vs_in 查找存在的连接
static struct dp_vs_conn *
tcp_conn_lookup(struct dp_vs_proto *proto, const struct dp_vs_iphdr *iph,
struct rte_mbuf *mbuf, int *direct, bool reverse, bool *drop)
{
struct tcphdr *th, _tcph;
struct dp_vs_conn *conn;
assert(proto && iph && mbuf);
th = mbuf_header_pointer(mbuf, iph->len, sizeof(_tcph), &_tcph);
if (unlikely(!th))
return NULL;
if (dp_vs_blklst_lookup(iph->proto, &iph->daddr, th->dest, &iph->saddr)) {
*drop = true;
return NULL;
}
conn = dp_vs_conn_get(iph->af, iph->proto,
&iph->saddr, &iph->daddr, th->source, th->dest, direct, reverse);
/*
* L2 confirm neighbour
* pkt in from client confirm neighbour to client
* pkt out from rs confirm neighbour to rs
*/
if (conn != NULL) {
if (th->ack) {
if ((*direct == DPVS_CONN_DIR_INBOUND) && conn->out_dev
&& (conn->out_nexthop.in.s_addr != htonl(INADDR_ANY))) {
neigh_confirm(conn->out_nexthop.in, conn->out_dev);
} else if ((*direct == DPVS_CONN_DIR_OUTBOUND) && conn->in_dev
&& (conn->in_nexthop.in.s_addr != htonl(INADDR_ANY))) {
neigh_confirm(conn->in_nexthop.in, conn->in_dev);
}
}
}
return conn;
}
首先通过 dp_vs_blklst_lookup 查找 ip 黑名单,然后调用 dp_vs_conn_get 查找。 最后要确认邻居子系统。
struct dp_vs_conn *dp_vs_conn_get(int af, uint16_t proto,
const union inet_addr *saddr, const union inet_addr *daddr,
uint16_t sport, uint16_t dport, int *dir, bool reverse)
{
uint32_t hash;
struct conn_tuple_hash *tuphash;
struct dp_vs_conn *conn = NULL;
#ifdef CONFIG_DPVS_IPVS_DEBUG
char sbuf[64], dbuf[64];
#endif
if (unlikely(reverse))
hash = conn_hashkey(af, daddr, dport, saddr, sport);
else
hash = conn_hashkey(af, saddr, sport, daddr, dport);
#ifdef CONFIG_DPVS_IPVS_CONN_LOCK
rte_spinlock_lock(&this_conn_lock);
#endif
if (unlikely(reverse)) { /* swap source/dest for lookup */
list_for_each_entry(tuphash, &this_conn_tab[hash], list) {
if (tuphash->sport == dport
&& tuphash->dport == sport
&& inet_addr_equal(af, &tuphash->saddr, daddr)
&& inet_addr_equal(af, &tuphash->daddr, saddr)
&& tuphash->proto == proto
&& tuphash->af == af) {
/* hit */
conn = tuplehash_to_conn(tuphash);
rte_atomic32_inc(&conn->refcnt);
if (dir)
*dir = tuphash->direct;
break;
}
}
} else {
list_for_each_entry(tuphash, &this_conn_tab[hash], list) {
if (tuphash->sport == sport
&& tuphash->dport == dport
&& inet_addr_equal(af, &tuphash->saddr, saddr)
&& inet_addr_equal(af, &tuphash->daddr, daddr)
&& tuphash->proto == proto
&& tuphash->af == af) {
/* hit */
conn = tuplehash_to_conn(tuphash);
rte_atomic32_inc(&conn->refcnt);
if (dir)
*dir = tuphash->direct;
break;
}
}
}
return conn;
}
dp_vs_conn_get 使用五元组进行索引,
在这里可以看到,dir 方向被赋值,而 tuphash->direct 来自建立连接时初始化。
list_for_each_entry 是一个链表遍历的宏,dpvs 使用的链表和内核是一样的。数据结构以后单独说。
dp_vs_in 新建立连接
新建的连接由 conn_sched 进行调度,对于 tcp 服务调用 tcp_conn_sched
static int tcp_conn_sched(struct dp_vs_proto *proto,
const struct dp_vs_iphdr *iph,
struct rte_mbuf *mbuf,
struct dp_vs_conn **conn,
int *verdict)
{
struct tcphdr *th, _tcph;
struct dp_vs_service *svc;
assert(proto && iph && mbuf && conn && verdict);
th = mbuf_header_pointer(mbuf, iph->len, sizeof(_tcph), &_tcph);
if (unlikely(!th)) {
*verdict = INET_DROP;
return EDPVS_INVPKT;
}
获取 tcp header, 只是指针操作,不涉及数据复制
/* only TCP-SYN without other flag can be scheduled */
if (!th->syn || th->ack || th->fin || th->rst) {
/* Drop tcp packet which is send to vip and !vport */
if (g_defence_tcp_drop &&
(svc = dp_vs_lookup_vip(iph->af, iph->proto, &iph->daddr))) {
dp_vs_estats_inc(DEFENCE_TCP_DROP);
*verdict = INET_DROP;
return EDPVS_INVPKT;
}
*verdict = INET_ACCEPT;
return EDPVS_INVAL;
}
对于新建立的连接,只允许 syn 请求,其它的丢弃
svc = dp_vs_service_lookup(iph->af, iph->proto,
&iph->daddr, th->dest, 0, mbuf, NULL);
if (!svc) {
/* Drop tcp packet which is send to vip and !vport */
if (g_defence_tcp_drop &&
(svc = dp_vs_lookup_vip(iph->af, iph->proto, &iph->daddr))) {
dp_vs_estats_inc(DEFENCE_TCP_DROP);
*verdict = INET_DROP;
return EDPVS_INVPKT;
}
*verdict = INET_ACCEPT;
return EDPVS_NOSERV;
}
dp_vs_service_lookup 根据请求目地址和端口来查找服务,如果找不到丢弃。
*conn = dp_vs_schedule(svc, iph, mbuf, false);
if (!*conn) {
dp_vs_service_put(svc);
*verdict = INET_DROP;
return EDPVS_RESOURCE;
}
dp_vs_service_put(svc);
return EDPVS_OK;
}
dp_vs_schedule 根据服务来选择后端 real server 建立连接。
dp_vs_in 新建立连接后端调度dp_vs_schedule
struct dp_vs_conn *dp_vs_schedule(struct dp_vs_service *svc,
const struct dp_vs_iphdr *iph,
struct rte_mbuf *mbuf,
bool is_synproxy_on)
{
uint16_t _ports[2], *ports; /* sport, dport */
struct dp_vs_dest *dest;
struct dp_vs_conn *conn;
struct dp_vs_conn_param param;
struct sockaddr_in daddr, saddr;
int err;
assert(svc && iph && mbuf);
ports = mbuf_header_pointer(mbuf, iph->len, sizeof(_ports), _ports);
if (!ports)
return NULL;
/* persistent service */
if (svc->flags & DP_VS_SVC_F_PERSISTENT)
return dp_vs_sched_persist(svc, iph, mbuf, is_synproxy_on);
长连接请求行为是有些差异的,暂时忽略,后面再分析。
dest = svc->scheduler->schedule(svc, mbuf); // 特定的调度算法
if (!dest) {
RTE_LOG(WARNING, IPVS, "%s: no dest found.\n", __func__);
#ifdef CONFIG_DPVS_MBUF_DEBUG
dp_vs_mbuf_dump("found dest failed.", iph->af, mbuf);
#endif
return NULL;
}
根据特定算法选择 real server, 常用的有 rr, wrr, wlc 以后再分析。返回 dest 结构体是后端 rs
if (dest->fwdmode == DPVS_FWD_MODE_SNAT) {
if (unlikely(iph->proto == IPPROTO_ICMP)) {
struct icmphdr *ich, _icmph;
ich = mbuf_header_pointer(mbuf, iph->len, sizeof(_icmph), &_icmph);
if (!ich)
return NULL;
ports = _ports;
_ports[0] = icmp4_id(ich);
_ports[1] = ich->type << 8 | ich->code;
/* ID may confict for diff host,
* need we use ID pool ? */
dp_vs_conn_fill_param(iph->af, iph->proto,
&iph->daddr, &dest->addr,
ports[1], ports[0],
0, ¶m);
} else {
/* we cannot inherit dest (host's src port),
* that may confict for diff hosts,
* and using dest->port is worse choice. */
memset(&daddr, 0, sizeof(daddr));
daddr.sin_family = AF_INET;
daddr.sin_addr = iph->daddr.in;
daddr.sin_port = ports[1];
memset(&saddr, 0, sizeof(saddr));
saddr.sin_family = AF_INET;
saddr.sin_addr = dest->addr.in;
saddr.sin_port = 0;
err = sa_fetch(NULL, &daddr, &saddr);
if (err != 0) {
#ifdef CONFIG_DPVS_MBUF_DEBUG
dp_vs_mbuf_dump("sa_fetch failed.", iph->af, mbuf);
#endif
return NULL;
}
dp_vs_conn_fill_param(iph->af, iph->proto,
&iph->daddr, &dest->addr,
ports[1], saddr.sin_port,
0, ¶m);
}
} else {
snat 特殊处理,暂时不看,以后分析
if (unlikely(iph->proto == IPPROTO_ICMP)) {
struct icmphdr *ich, _icmph;
ich = mbuf_header_pointer(mbuf, iph->len, sizeof(_icmph), &_icmph);
if (!ich)
return NULL;
ports = _ports;
_ports[0] = icmp4_id(ich);
_ports[1] = ich->type << 8 | ich->code;
dp_vs_conn_fill_param(iph->af, iph->proto,
&iph->saddr, &iph->daddr,
ports[0], ports[1], 0, ¶m);
} else {
ICMP 处理暂时不看,以后分析
dp_vs_conn_fill_param(iph->af, iph->proto,
&iph->saddr, &iph->daddr,
ports[0], ports[1], 0, ¶m);
}
}
填充参数 proto, caddr, vaddr, cport, vport 供新建连接使用
conn = dp_vs_conn_new(mbuf, ¶m, dest,
is_synproxy_on ? DPVS_CONN_F_SYNPROXY : 0);
if (!conn) {
if (dest->fwdmode == DPVS_FWD_MODE_SNAT && iph->proto != IPPROTO_ICMP)
sa_release(NULL, &daddr, &saddr);
#ifdef CONFIG_DPVS_MBUF_DEBUG
dp_vs_mbuf_dump("create conn failed.", iph->af, mbuf);
#endif
return NULL;
}
dp_vs_stats_conn(conn);
return conn;
}
dp_vs_conn_new 根据参数,目标机器信息建立代理连接
dp_vs_in 新建立连接dp_vs_conn_new
struct dp_vs_conn * dp_vs_conn_new(struct rte_mbuf *mbuf,
struct dp_vs_conn_param *param,
struct dp_vs_dest *dest, uint32_t flags)
{
struct dp_vs_conn *new;
struct conn_tuple_hash *t;
uint16_t rport;
__be16 _ports[2], *ports;
int err;
assert(mbuf && param && dest);
if (unlikely(rte_mempool_get(this_conn_cache, (void **)&new) != 0)) {
RTE_LOG(WARNING, IPVS, "%s: no memory\n", __func__);
return NULL;
}
memset(new, 0, sizeof(struct dp_vs_conn));
new->connpool = this_conn_cache;
内存池,这很重要,malloc 分配内存很慢的
/* set proper RS port */
if ((flags & DPVS_CONN_F_TEMPLATE) || param->ct_dport != 0)
rport = param->ct_dport;
else if (dest->fwdmode == DPVS_FWD_MODE_SNAT) {
if (unlikely(param->proto == IPPROTO_ICMP)) {
rport = param->vport;
} else {
ports = mbuf_header_pointer(mbuf, ip4_hdrlen(mbuf),
sizeof(_ports), _ports);
if (unlikely(!ports)) {
RTE_LOG(WARNING, IPVS, "%s: no memory\n", __func__);
goto errout;
}
rport = ports[0];
}
} else
rport = dest->port;
/* init inbound conn tuple hash */
t = &tuplehash_in(new);
t->direct = DPVS_CONN_DIR_INBOUND; // 入口流量,肯定是外网进来的
t->af = param->af;
t->proto = param->proto;
t->saddr = *param->caddr; // 源地址是 外网 client addr
t->sport = param->cport;
t->daddr = *param->vaddr; // 目地地址是 服务虚IP地址
t->dport = param->vport;
INIT_LIST_HEAD(&t->list);
/* init outbound conn tuple hash */
t = &tuplehash_out(new);
t->direct = DPVS_CONN_DIR_OUTBOUND; // 出口
t->af = param->af;
t->proto = param->proto;
if (dest->fwdmode == DPVS_FWD_MODE_SNAT)
t->saddr.in.s_addr = ip4_hdr(mbuf)->src_addr;
else
t->saddr = dest->addr;
t->sport = rport;
t->daddr = *param->caddr; /* non-FNAT */
t->dport = param->cport; /* non-FNAT */
INIT_LIST_HEAD(&t->list);
conn 连接有一个 tuplehash 数组元素,长度方2,保存两个方向的 tupehash 结构体。不同方向的源地址和目的地址意义是不同的。
/* init connection */
new->af = param->af;
new->proto = param->proto;
new->caddr = *param->caddr;
new->cport = param->cport;
new->vaddr = *param->vaddr;
new->vport = param->vport;
new->laddr = *param->caddr; /* non-FNAT */
new->lport = param->cport; /* non-FNAT */
if (dest->fwdmode == DPVS_FWD_MODE_SNAT)
new->daddr.in.s_addr = ip4_hdr(mbuf)->src_addr;
else
new->daddr = dest->addr;
new->dport = rport;
连接保存 caddr, vaddr, cport, vport 信息
/* neighbour confirm cache 邻居子系统*/
new->in_nexthop.in.s_addr = htonl(INADDR_ANY);
new->out_nexthop.in.s_addr = htonl(INADDR_ANY);
new->in_dev = NULL;
new->out_dev = NULL;
/* Controll member */
new->control = NULL;
rte_atomic32_clear(&new->n_control);
/* caller will use it right after created,
* just like dp_vs_conn_get(). */
rte_atomic32_set(&new->refcnt, 1);
new->flags = flags;
new->state = 0;
#ifdef CONFIG_DPVS_IPVS_STATS_DEBUG
new->ctime = rte_rdtsc();
#endif
/* bind destination and corresponding trasmitter */
err = conn_bind_dest(new, dest);
if (err != EDPVS_OK) {
RTE_LOG(WARNING, IPVS, "%s: fail to bind dest: %s\n",
__func__, dpvs_strerror(err));
goto errout;
}
conn_bind_dest 在这里设置转发模式相关的几个发包收包操作,非常重要
/* FNAT only: select and bind local address/port */
if (dest->fwdmode == DPVS_FWD_MODE_FNAT) {
if ((err = dp_vs_laddr_bind(new, dest->svc)) != EDPVS_OK)
goto unbind_dest;
}
full-nat 特殊处理,以后再分析
/* add to hash table (dual dir for each bucket) */
if ((err = conn_hash(new)) != EDPVS_OK)
goto unbind_laddr;
conn_hash 将连接加到 this_conn_tab 流表,仔细看实现,实际上是将 tuphash 两个方向的都加到流表里,方便不同方向的检索。
/* timer */
new->timeout.tv_sec = conn_init_timeout;
new->timeout.tv_usec = 0;
默认超时时间
/* synproxy 用于 syn proxy 使用*/
INIT_LIST_HEAD(&new->ack_mbuf);
rte_atomic32_set(&new->syn_retry_max, 0);
rte_atomic32_set(&new->dup_ack_cnt, 0);
if ((flags & DPVS_CONN_F_SYNPROXY) && !(flags & DPVS_CONN_F_TEMPLATE)) {
struct tcphdr _tcph, *th;
struct dp_vs_synproxy_ack_pakcet *ack_mbuf;
struct dp_vs_proto *pp;
th = mbuf_header_pointer(mbuf, ip4_hdrlen(mbuf), sizeof(_tcph), &_tcph);
if (!th) {
RTE_LOG(ERR, IPVS, "%s: get tcphdr failed\n", __func__);
goto unbind_laddr;
}
/* save ack packet */
if (unlikely(rte_mempool_get(this_ack_mbufpool, (void **)&ack_mbuf) != 0)) {
RTE_LOG(ERR, IPVS, "%s: no memory\n", __func__);
goto unbind_laddr;
}
ack_mbuf->mbuf = mbuf;
list_add_tail(&ack_mbuf->list, &new->ack_mbuf);
new->ack_num++;
sp_dbg_stats32_inc(sp_ack_saved);
/* save ack_seq - 1 */
new->syn_proxy_seq.isn =
htonl((uint32_t) ((ntohl(th->ack_seq) - 1)));
/* save ack_seq */
new->fnat_seq.fdata_seq = htonl(th->ack_seq);
/* FIXME: use DP_VS_TCP_S_SYN_SENT for syn */
pp = dp_vs_proto_lookup(param->proto);
new->timeout.tv_sec = pp->timeout_table[new->state = DPVS_TCP_S_SYN_SENT];
}
sync proxy 非常重要,以后分析
this_conn_count++;
/* schedule conn timer */
dpvs_time_rand_delay(&new->timeout, 1000000);
if (new->flags & DPVS_CONN_F_TEMPLATE)
dpvs_timer_sched(&new->timer, &new->timeout, conn_expire, new, true);
else
dpvs_timer_sched(&new->timer, &new->timeout, conn_expire, new, false);
#ifdef CONFIG_DPVS_IPVS_DEBUG
conn_dump("new conn: ", new);
#endif
return new;
unbind_laddr:
dp_vs_laddr_unbind(new);
unbind_dest:
conn_unbind_dest(new);
errout:
rte_mempool_put(this_conn_cache, new);
return NULL;
}
最后将连接加到定时器,管理连接超时。tcp 不同状态的超时时间是不同的,以后单独分析定时器
dp_vs_in 新建立连接conn_bind_dest
switch (dest->fwdmode) {
case DPVS_FWD_MODE_NAT:
conn->packet_xmit = dp_vs_xmit_nat;
conn->packet_out_xmit = dp_vs_out_xmit_nat;
break;
case DPVS_FWD_MODE_TUNNEL:
conn->packet_xmit = dp_vs_xmit_tunnel;
break;
case DPVS_FWD_MODE_DR:
conn->packet_xmit = dp_vs_xmit_dr;
break;
case DPVS_FWD_MODE_FNAT:
conn->packet_xmit = dp_vs_xmit_fnat;
conn->packet_out_xmit = dp_vs_out_xmit_fnat;
break;
case DPVS_FWD_MODE_SNAT:
conn->packet_xmit = dp_vs_xmit_snat;
conn->packet_out_xmit = dp_vs_out_xmit_snat;
break;
default:
return EDPVS_NOTSUPP;
}
conn_bind_dest 只贴了核心部分,可以看到 NAT 相关的流量都要经过 LB,而 DR TUNNEL 是不需要经过的,只有入流量,没有出。
xmit_inbound xmit_outbound 回写数据
再回头看 dp_vs_in,由于 DR 模式只有入口流量,所以只会调用 xmit_inbound.
/* forward to RS */
err = conn->packet_xmit(prot, conn, mbuf);
if (err != EDPVS_OK)
RTE_LOG(DEBUG, IPVS, "%s: fail to transmit: %d\n", __func__, err);
dp_vs_conn_put(conn);
/* always stolen the packet */
return INET_STOLEN;
而最终 xmit_inbound 调用 conn_bind_dest 指定的 dp_vs_xmit_dr, 并且永远返回 INET_STOLEN,再回到 INET_HOOK,如果返回值是 INET_STOLEN,那么不会调 okfn 回调。
dp_vs_xmit_dr 写数据给 rs
由于 dr 工作在二层同一个物理网络,所以最终调用 neigh_resolve_output 邻居子系统,将包发出去。
neigh_fill_mac(neighbour, m);
netif_xmit(m, neighbour->port);
最终调用两个函数,neigh_fill_mac 负责填充 mac, netif_xmit 负责发送数据。
static void neigh_fill_mac(struct neighbour_entry *neighbour, struct rte_mbuf *m)
{
struct ether_hdr *eth;
uint16_t pkt_type;
m->l2_len = sizeof(struct ether_hdr);
eth = (struct ether_hdr *)rte_pktmbuf_prepend(m, (uint16_t)sizeof(struct ether_hdr));
ether_addr_copy(&neighbour->eth_addr,ð->d_addr);
ether_addr_copy(&neighbour->port->addr,ð->s_addr);
pkt_type = (uint16_t)m->packet_type;
eth->ether_type = rte_cpu_to_be_16(pkt_type);
}
这里很明显了,ether_addr_copy(&neighbour->eth_addr,ð->d_addr) 将目的 mac 地址改写成邻居子系统中查到的 real server 地址,将源 mac 改写成当前 LB 网卡的地址。
int netif_xmit(struct rte_mbuf *mbuf, struct netif_port *dev)
{
int ret = EDPVS_OK;
uint16_t mbuf_refcnt;
if (unlikely(NULL == mbuf || NULL == dev)) {
if (mbuf)
rte_pktmbuf_free(mbuf);
return EDPVS_INVAL;
}
if (mbuf->port != dev->id)
mbuf->port = dev->id;
/* assert for possible double free */
mbuf_refcnt = rte_mbuf_refcnt_read(mbuf);
assert((mbuf_refcnt >= 1) && (mbuf_refcnt <= 64));
if (dev->flag & NETIF_PORT_FLAG_TC_EGRESS) {
mbuf = tc_handle_egress(netif_tc(dev), mbuf, &ret);
if (likely(!mbuf))
return ret;
}
return netif_hard_xmit(mbuf, dev);
}
netif_xmit 发送数据前先通过 tc_handle_egress 做流控,以后单独分析。然后通过 netif_hard_xmit 将数据写到网卡。
小结
通篇都是代码,比较难读。其他转发模式稍后分析,关于 dpvs 的优化点也一一详解。