[Hadoop in China 2011] 海狗不是狗 探秘支付宝准实时搜索查询
http://storage.it168.com/a2011/1203/1283/000001283153.shtml
作为了国内最大的第三方交易平台,支付宝每天所产生的数据量无疑是难以估算的。这些数据不管是对于个人用户还是支付宝都是非常重要的。通常情况下, 个人用户会对记录在Hbase内的历史消费记录进行查询,亦或是CTU风险数据项目。并且,支付宝利用Hadoop也相对比较成熟,其下包括一站式资源服务的海豚系统,以及与Pig相关的可视化用户自主查询。这些工具和应用形成了支付宝至关重要的ADC架构体系,而在这其中最为影响用户体验则是海狗实时搜索服务。
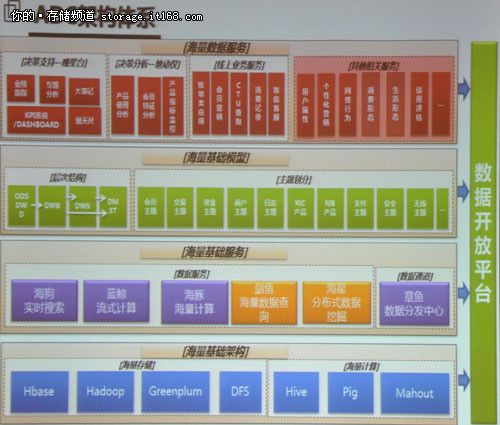
如上图所示,海狗实时搜索、蓝鲸流式计算、海豚海量计算、剑鱼海量数据查询、海星分布式数据挖掘与章鱼数据分发中心共同组成了ADC架构体系,共同为用户提供海量数据基础服务,而这些统统都与数据有关,或者说与Hadoop相关。
Note:日后重点关注下列开源产品:海量存储 :Hadoop, Hbase, Greenplum, DFS,海量计算:Hive, Pig, Mahout
Hadoop, Hbase, Hive, Pig, Mahout and Solr 为日后的关注重点。
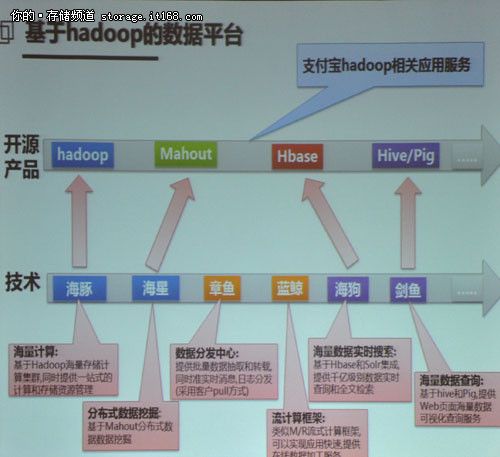
从上图可以看出,海狗海量数据实时搜索是基于Hbase和Solr集成,为用户提供千亿级别的数据实时查询和全文检索,这在支付宝的业务中是重中之重, 也是基础服务之一,必然要求数据查询结果能够实时返回。那么面对海量的数据信息,支付宝的技术团队是如何做到的呢?下面,支付宝公司架构师蒋杰将为我们揭秘海狗实时搜索的内在技术。

支付宝架构师蒋杰(平原君)
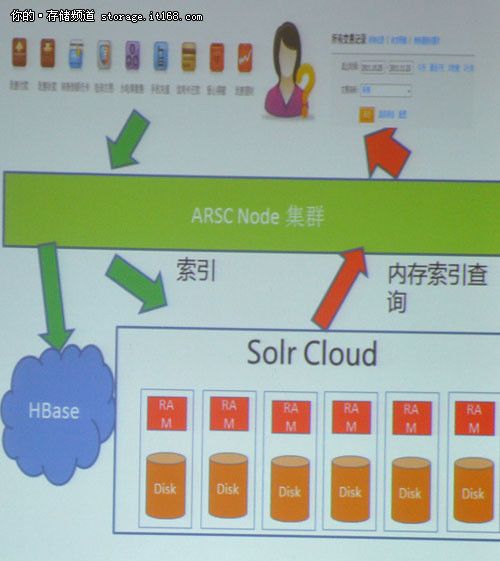
海狗实时搜索工作原理拓扑图
海狗系统(ARSC Alipay Realtime Search Cluster)是支付宝实时搜索集群平台,其是基于Hadoop、Hbase、Zookeeper、Solr以及Zoie等开源技术二次开发而 成。它的产生是为解决当前数据库无法支持海量数据的检索/全文检索、数据库存在Schema动态扩展问题、Hbase无法支持多维度检索以及普通搜索引擎无法做到实时更新数据检索等难题。
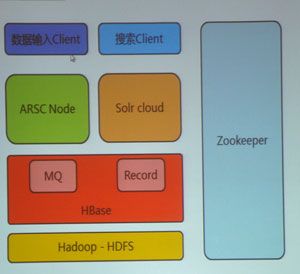
海狗系统逻辑架构
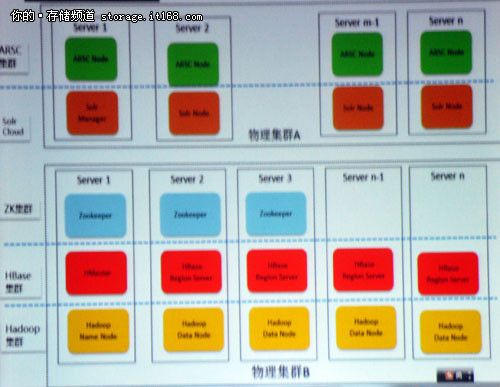
海狗集群架构
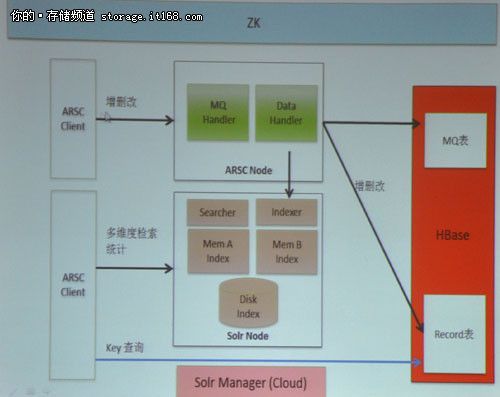
▲海狗功能模块
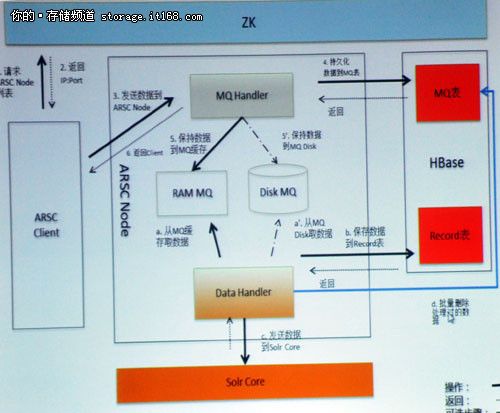
▲海狗节点示意图
ARSC Node主要作用在于能够高效地接收Client输入数据,并同步Hbase Record数据到Solr索引(WAL作用),同时还能缓存瞬时高并发数据。其工作原理是Client请求ZK,ZK取得ARSC Node列表返回给Client,ARSC Node接收Client CRUD请求,再通过MQ Handler模块持久化数据到MQ-shard表,并通过MQ Handler模块写MQ内存缓存;若内存缓存写满,那么开始写本地硬盘上,最后返回客户端。
Solr Node主要作用是接收ARSC Node发送数据并创建实时索引,以提供实时搜索。其具体工作流程如下图所示:
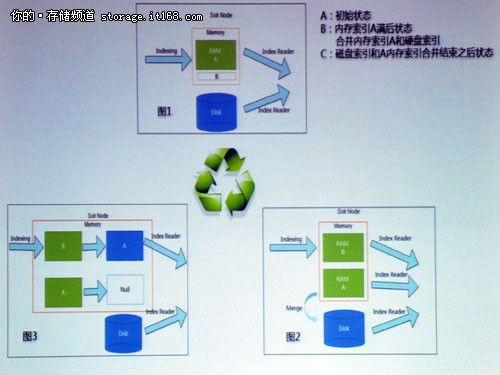
▲
Solr Core接收从MQ Push过来的数据,保存到内存索引A(B为空),内存索引A是每添加完文档后立刻更新索引,保证实时性,同时,内存索引A和硬盘上 的索引Disk,同时对外提供搜索服务。当A中的文档数量达到一定的数量时,需要同硬盘上的索引进行合并,这时候会创建内存索引B,在合并过程中新添加的 文档全部放入内存索引B中。A,B和Disk Index共同对外提供搜索服务(PS:A中的索引不会重复索引,索引一致性保证),A和Disk index合并之后,原来的索引A变为null,B改名为A,同时,并重新打开Disk索引提供搜索(Disk index=A+Old Disk index)。
海狗实时搜索的优势在于能够提供实时的数据更新和检索,能够对数值检索、枚举检索、全文检索等多种类型提供实时多维度检索,并且还可支持异步的批量查询和类SQL查询语句。并且,其扩展也非常灵活,能够对性能实现动态扩展,对容量实现线性扩展,并具备动态负载均衡以及动态的Schema扩展。