使用 EPUB 制作数字图书 基于 XML 的开放式 eBook 格式
/////////////////////////////////////////////////////////////////////////////////////////////Page1
简介: 是否需要分发文档、创建电子图书或者把喜欢的博客文章存档?EPUB 是一种开放式的数字图书规范,以常用的技术如 XML、CSS 和 XHTML 为基础,EPUB 文件可在便携式的 e-ink 设备、移动电话和桌面计算机上阅读。本教程详细阐述了 EPUB 格式,首先用 Java™ 技术示范了 EPUB 验证,然后详细说明如何使用 DocBook 和 Python 自动创建 EPUB。
开始之前
本教程讲述如何创建 EPUB 格式的电子图书。EPUB 是一种基于 XML 的、对开发者友好的格式,正逐渐成为数字图书的事实标准。但 EPUB 不仅可用于图书,还包括:
- 对文档打包以便离线阅读或者分发
- 打包博客文章或者其他 Web 内容
- 使用常见的开放源代码工具创建、搜索和整理
本教程首先手工创建一个 EPUB 图书,帮助您了解其构成和需要的文件。然后说明如何捆绑完成的数字图书,按照规范进行验证以及在不同的阅读系统上测试。
然后讨论如何从 DocBook XML 生成 EPUB — 最常用的技术文档标准之一 — 以及如何使用 Python 实现从 DocBook 到 EPUB 的自动创建。
通过本教程可以学习如下内容:
- 了解 EPUB 是什么,谁支持它,谁采用它
- 了解 EPUB 包的结构,包括需要的文件及其模式
- 如何从头创建一个内容简单而有效的 EPUB 文件
- 使用开放源代码工具从 DocBook 生成 EPUB 文件,DocBook 是一种常见的技术文档和图书模式
- 使用 Python 和 DocBook 自动转换成 EPUB
本教程对操作系统没有特殊要求,但是应该熟悉创建文件和目录的机制。建议使用 XML 编辑器或者集成开发环境(IDE)。
对于本教程后半部分的 EPUB 创建自动化内容,需要读者了解基本的 XML 处理技巧 — XSLT、 DOM 或者基于 SAX 的解析 — 并熟悉使用 XML 原生 API 构造 XML 文档。
阅读本教程不需要熟悉 EPUB 文件格式。
尝试本教程中的例子,需要一个 Java 解释器(1.5 或更高版本)和 Python 解释器(2.4 或更高版本)以及相应的 XML 库。不过,有经验的 XML 开发人员很容易将这些例子修改为适合任何编程语言和 XML 库。
/////////////////////////////////////////////////////////////////////////////////////////////Page2
关于 EPUB 格式
了解 EPUB 的背景,EPUB 最适合做什么,以及 EPUB 和便携式文档格式(PDF)的区别。
EPUB 是可逆的数字图书和出版物 XML 格式,数字出版业商业和标准协会 International Digital Publishing Forum (IDPF) 制定的标准。IDPF 于 2007 年 10 月正式采用 EPUB,随后被主流出版商迅速采用。可以使用各种开放源代码或者商业软件在所有主流操作系统、Sony PRS 之类的 e-ink 设备或者 Apple iPhone 之类的小型设备上阅读 EPUB 格式。
虽然最早采用 EPUB 的是传统的印刷品出版商,但是这并不妨碍它在电子图书中的应用。利用免费的软件工具,可以将网页捆绑成 EPUB,转化成文本文件或者将原有的 DocBook XML 文档转化成结构良好的、有效的 EPUB(后一点将在 从 DocBook 到 EPUB 一节讨论)。
PDF 仍然是世界上应用最广泛的电子文档格式。从图书出版商的角度来看,PDF 的优点包括:
- PDF 文件允许对页面布局进行像素级的控制,包括复杂的打印格式,如多栏格式和奇偶页相间的格式。
- 有多种不同的 GUI 文档工具可生成 PDF,如 Microsoft® Office Word 和 Adobe® InDesign®。
- PDF 阅读器非常普及,现在大多数计算机上都有安装。
- PDF 可以嵌入特殊的字体,精确控制最终的输出结果。
从软件开发人员的角度来看,PDF 还远远不够理想:
- 这不是一种简单易学的标准,因此编写自己的 PDF 生成代码非常困难。
- 虽然 PDF 现在是一种 International Organization for Standardization(ISO)标准(ISO 32000-1:2008),但过去一直受一家公司的控制:Adobe Systems。
- 尽管多数编程语言都提供了 PDF 库,但很多是商业产品或者嵌入到 GUI 应用程序中,外部进程不容易控制。并非所有的免费库都得到积极的维护。
- PDF 原生文本可以通过程序提取出来并进行搜索,但很少可以对 PDF 进行标记以便简单可靠地转化成 Web 友好的格式。
- PDF 文档不容易流动,就是说很难适应小屏幕或者对布局进行明显的改变。
EPUB 解决了 PDF 和开发人员友好性有关的所有瑕疵。一个 EPUB 就是一个简单 ZIP 格式文件(使用 .epub 扩展名),其中包括按照预先定义的方式排列的文件。如何制作 ZIP 文档有一些技巧,稍后将在 将 EPUB 文件捆绑为 ZIP 文档 一节介绍。除此以外,EPUB 非常简单:
- EPUB 中的所有内容基本上都是 XML。EPUB 文件可使用标准 XML 工具创建,不需要任何专门或者私有的软件。
- EPUB 内容(eBook 的具体内容)基本上都是 XHTML 1.1(另一种格式是 DTBook,为视力受限者编码书籍的一种标准。关于 DTBook 的更多信息请参阅 参考资料,本教程中不涉及这部分)。
- 大多数 EPUB XML 模式都来自现成的、可免费获得的、已发布的规范。
最关键的在于 EPUB 元数据是 XML,EPUB 内容是 XHTML。如果您的文档构建系统产生的结果用于 Web 和/或基于 XML,那么也可用于生成 EPUB。
/////////////////////////////////////////////////////////////////////////////////////////////Page3
创建第一个 EPUB
最小的 EPUB 包至少要包含几个文件。规范对于 EPUB 包中这些文件的格式、内容和位置要求可能很严格。这一节讨论使用 EPUB 标准必须 了解的基础知识。
小型 EPUB 文件的基本结构遵循 清单 1 所示的样式。准备好分发之前,整个目录结构被压缩到一个 ZIP 格式文件中,几点特殊要求将在 用 ZIP 打包 EPUB 文件 一节讨论。
mimetype
META-INF/
container.xml
OEBPS/
content.opf
title.html
content.html
stylesheet.css
toc.ncx
images/
cover.png
|
提示:可 下载 符合该结构的一个电子图书,但建议按照本教程的说明自己创建一个。
编写 EPUB 图书之前首先创建 EPUB 项目的目录。打开文本编辑器或者 Eclipse 之类的 IDE。建议采用支持 XML 的编辑器 — 具体而言就是能够根据 参考资料 给出的 Relax NG 模式进行验证。
这个文件非常简单,必须命名为 mimetype,文件内容如下:
application/epub+zip |
要注意,mimetype 文件不能包含新行或者回车。
此外,mimetype 文件必须作为 ZIP 档案中的第一个文件,而且自身不能压缩。用 ZIP 打包 EPUB 文件 一节将介绍如何使用一般的 ZIP 参数将其包含进来。现在创建该文件并保存,并确保它在 EPUB 项目的根目录中。
EPUB 根目录下必须包含 META-INF 目录,而且其中要有一个文件 container.xml。EPUB 阅读系统首先查看该文件,它指向数字图书元数据的位置。
创建目录 META-INF。在其中创建一个新文件 container.xml。container 文件非常小,但是对结构要求很严格。将 清单 2 中的代码粘贴到 META-INF/container.xml 中。
<?xml version="1.0"?>
<container version="1.0" xmlns="urn:oasis:names:tc:opendocument:xmlns:container">
<rootfiles>
<rootfile full-path="OEBPS/content.opf"
media-type="application/oebps-package+xml" />
</rootfiles>
</container>
|
full-path(粗体)的值仅仅是该文件的一部分,不同的文件可能相差甚大。目录路径必须相对于 EPUB 文件根目录本身,而不是 META-INF 目录。
mimetype 和 container 是 EPUB 档案中仅有的两个需要严格限制位置的文件。建议(尽管不是必须的)将其他文件保存到 EPUB 的子目录下(按照惯例,通常被称为 OEBPS,即 Open eBook Publication Structure,但不是必须的)。
接下来在 EPUB 项目中创建目录 OEBPS。本教程下一节将介绍 OEBPS 中的文件 — 数字图书的核心:元数据和页面。
尽管该文件名没有特殊要求,但通常被称为 content.opf。它指定了图书中所有 内容的位置,如文本和图像等其他媒体。它还给出了另一个元数据文件,内容的 Navigation Center eXtended (NCX) 表。
该 OPF 文件是 EPUB 规范中最复杂的元数据。创建 OEBPS/content.opf 并粘贴 清单 3 所示的内容。
<?xml version='1.0' encoding='utf-8'?>
<package xmlns="http://www.idpf.org/2007/opf"
xmlns:dc="http://purl.org/dc/elements/1.1/"
unique-identifier="bookid" version="2.0">
<metadata>
<dc:title>Hello World: My First EPUB</dc:title>
<dc:creator>My Name</dc:creator>
<dc:identifier id="bookid">urn:uuid:12345</dc:identifier>
<meta name="cover" content="cover-image" />
</metadata>
<manifest>
<item id="ncx" href="toc.ncx" media-type="text/xml"/>
<item id="cover" href="title.html" media-type="application/xhtml+xml"/>
<item id="content" href="content.html" media-type="application/xhtml+xml"/>
<item id="cover-image" href="images/cover.png" media-type="image/png"/>
<item id="css" href="stylesheet.css" media-type="text/css"/>
</manifest>
<spine toc="ncx">
<itemref idref="cover" linear="no"/>
<itemref idref="content"/>
</spine>
<guide>
<reference href="cover.html" type="cover" title="Cover"/>
</guide>
</package>
|
OPF 文档本身必须使用名称空间 http://www.idpf.org/2007/opf,元数据则使用 Dublin Core Metadata Initiative (DCMI) 名称空间 http://purl.org/dc/elements/1.1/。
最好现在将 OPF 和 DCMI 模式添加到 XML 编辑器中。EPUB 用到的所有模式都可以 下载。
Dublin Core 定义了一组常用的元数据,可用于描述各种不同的数字资料,它不是 EPUB 规范的一部分。所有这些术语都可以出现在 OPF 元数据部分。编写要分发的 EPUB 时,这里可以放很多内容,目前来说 清单 4 的内容就足够了。
... <metadata> <dc:title>Hello World: My First EPUB</dc:title> <dc:creator>My Name</dc:creator> <dc:identifier id="bookid">urn:uuid:12345</dc:identifier> <meta name="cover" content="cover-image" /> </metadata> ... |
有两个术语是必须的,即 title 和 identifier。按照 EPUB 规范,标识符必须 是惟一的,但是这个惟一的值要靠数字图书的创建者来定义。对于图书出版商来说,这个字段一般包含 ISBN 或者 Library of Congress 编号。对于其他 EPUB 创建者,可以考虑使用 URL 或者很大的随机生成的惟一用户 ID(UUID)。要注意,属性 unique-identifier 的值必须和 dc:identifier 元素的 ID 属性匹配。
其他和内容相关的可以考虑添加的元数据包括:
- 语言(如
dc:language)。 - 出版日期(如
dc:date)。 - 出版商(如
dc:publisher)。(可以是公司或个人的名称)。 - 版权信息(如
dc:rights)。(如果采用 Creative Commons 许可证,可以将许可证的 URL 放在这里)。
关于 DCMI 的更多信息请参阅 参考资料。
EPUB 规范没有要求包含 name 属性值为 cover 的 meta 元素,但为了增加封面和图像的可移植性,建议这样做。一些 EPUB 呈现程序喜欢使用图像文件作为封面,另一些则愿意使用包含内联封面图像的 XHTML 文件。该例子显示了这两种情况。meta 元素的 content 属性的值应该是图书封面图像在 manifest 中的 ID 号,manifest 是 OPF 文件的一部分。
OPF manifest 列出了 EPUB 内容(不包括元数据)中的所有资源。就是说,通常是组成电子图书文本的一组 XHTML 文件再加上一些相关的媒体如图像。EPUB 鼓励使用 CSS 设定图书内容的样式,因此 manifest 中也包含 CSS。进入数字图书的所有文件都必须在 manifest 中列出。
清单 5 显示了 manifest 的一部分。
... <manifest> <item id="ncx" href="toc.ncx" media-type="text/xml"/> <item id="cover" href="title.html" media-type="application/xhtml+xml"/> <item id="content" href="content.html" media-type="application/xhtml+xml"/> <item id="cover-image" href="images/cover.png" media-type="image/png"/> <item id="css" href="stylesheet.css" media-type="text/css"/> </manifest> ... |
第一项 toc.ncx(参见 下一节)是必须的。所有的项都有相应的 media-type 值,XHTML 内容的媒体类型为 application/xhtml+xml。媒体类型必须正确,不能 是 text/html 或者其他类型。
EPUB 支持四种核心 图像文件类型:Joint Photographic Experts Group (JPEG)、Portable Network Graphics (PNG)、Graphics Interchange Format (GIF) 和 Scalable Vector Graphics (SVG)。如果能够提供对核心类型的后退转换(fall-back),也可包含不支持的文件类型。关于后退转换内容的更多信息请参阅 OPF 规范。
href 属性的值应该是一个相对于该 OPF 文件 的统一资源标识符(URI)。(很容易和 container.xml 中对 OPF 文件的引用混淆,其中的引用是相对于 EPUB 的整体引用)。这里的 OPF 文件位于和内容相同的 OEBPS 目录中,因此不需要路径信息。
manifest 告诉 EPUB 阅读器哪些文件属于档案,spine 则指定这些文件出现的顺序或 — 按照 EPUB 的说法 — 数字图书的线性阅读顺序。可以将 OPF spine 看作是书中 “页面” 的顺序。按照文档顺序从上到下依次读取 spine。清单 6 显示了 OPF 文件的一个片段。
... <spine toc="ncx"> <itemref idref="cover" linear="no"/> <itemref idref="content"/> </spine> ... |
每个 itemref 元素都需要有一个 idref 属性,并且和 manifest 中的某个 ID 匹配。toc 属性也是必需的。它引用 manifest 中表示内容 NCX 表文件名的 ID。
spine 中的 linear 属性表明该项是作为线性阅读顺序中的一项,还是和先后次序无关。建议将封面定义为 linear=no。符合 EPUB 规范的阅读系统将首先打开 spine 中没有 设置为 linear=no 中的第一项。
OPF 内容文件的最后一部分是 guide。这一节是可选的,但最好保留。清单 7 显示了 guide 文件的部分内容。
... <guide> <reference href="cover.html" type="cover" title="Cover"/> </guide> ... |
guide 可以为 EPUB 阅读系统提供语义信息。manifest 定义了 EPUB 中的物理资源,spine 提供了这些资源的顺序信息,guide 负责解释这些部分的含义。下面是可以出现在 OPF guide 中的部分值:
cover:图书封面title-page:包含作者和出版商信息的页面toc:目录
完整的列表请参阅 OPF 2.0 规范(参见 参考资料)。
尽管 OCF 文件是作为 EPUB 本身的一部分定义的,但最后一个主要的元数据文件参照了不同的数字图书标准。DAISY 是一个专门为不能使用传统书籍的读者设计数据格式的组织,通常是因为视力受损或者不便于使用印刷的书籍。EPUB 借用了 DAISY 的 NCX DTD。NCX 定义了数字图书的目录表。复杂的图书中,目录表通常采用层次结构,包括嵌套的内容、章和节。
使用 XML 编辑器创建 OEBPS/toc.ncx 并粘贴 清单 8 所示的代码。
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE ncx PUBLIC "-//NISO//DTD ncx 2005-1//EN"
"http://www.daisy.org/z3986/2005/ncx-2005-1.dtd">
<ncx xmlns="http://www.daisy.org/z3986/2005/ncx/" version="2005-1">
<head>
<meta name="dtb:uid" content="urn:uuid:12345"/>
<meta name="dtb:depth" content="1"/>
<meta name="dtb:totalPageCount" content="0"/>
<meta name="dtb:maxPageNumber" content="0"/>
</head>
<docTitle>
<text>Hello World: My First EPUB</text>
</docTitle>
<navMap>
<navPoint id="navpoint-1" playOrder="1">
<navLabel>
<text>Book cover</text>
</navLabel>
<content src="title.html"/>
</navPoint>
<navPoint id="navpoint-2" playOrder="2">
<navLabel>
<text>Contents</text>
</navLabel>
<content src="content.html"/>
</navPoint>
</navMap>
</ncx>
|
DTD 要求 NCX <head> 标记中包含四个 meta 元素:
uid: 数字图书的惟一 ID。该元素应该和 OPF 文件中的dc:identifier对应。depth:反映目录表中层次的深度。该例只有一层,因此是 1。totalPageCount和maxPageNumber:仅用于纸质图书,保留 0 即可。
docTitle/text 的内容是图书的标题,和 OPF 中的 dc:title 匹配。
navMap 是 NCX 文件中最重要的部分,定义了图书的目录。navMap 包含一个或多个 navPoint 元素。每个 navPoint 都要包含下列元素:
playOrder属性,说明文档的阅读顺序。和 OPF spine 中itemref元素的顺序相同。navLabel/text元素,给出该章节的标题。通常是章的标题或者数字,如 “第一章”,或者 — 像这个例子一样 — “封面”。content元素,它的src属性指向包含这些内容的物理资源。就是 OPF manifest 中声明的文件(也可使用片段标识符引用 XHTML 内容中的锚元素 — 比如content.html#footnote1)。- 还可以有一个或多个
navPoint元素。NCX 使用嵌套的导航点表示层次结构的文档。
该文档的结构非常简单:只有两页,不存在嵌套关系。就是说有两个 navPoint 元素,它们的 playOrder 值按升序排列,从 1 开始。在 NCX 中可以命名这些章节,以便读者跳到电子图书不同的部分。
现在知道了 EPUB 需要的所有元数据,可以加入真正的图书内容了。可以使用 下载 的内容,也可以自己写,只要文件名和元数据匹配即可。
然后创建下列文件和文件夹:
- title.html:图书的标题页。创建该文件并在其中包含引用封面图片的
img元素,src的属性值为images/cover.png。 - images:在 OEBPS 下创建该文件夹,然后复制给定的示例图片(或者创建自己的图片)并命名为 cover.png。
- content.html:图书的实际文字内容。
- stylesheet.css:将该文件放在和 XHTML 文件相同的 OEBPS 目录中。该文件可以包含任意 CSS 声明,比如设置字体或者文字颜色。清单 10 给出了一个 CSS 文件的例子。
清单 9 包含了一个有效的 EPUB 内容页。将其作为标题页(title.html),用一个类似的页面作为主要内容页(content.html)。
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Hello World: My First EPUB</title>
<link type="text/css" rel="stylesheet" href="stylesheet.css" />
</head>
<body>
<h1>Hello World: My First EPUB</h1>
<div><img src="images/cover.png" alt="Title page"/></div>
</body>
</html>
|
EPUB 的 XHTML 需要符合几条要求,和一般的 Web 开发不同:
- 内容必须是有效的 XHTML 1.1:XHTML 1.0 Strict 和 XHTML 1.1 的主要区别是去掉了
name属性(使用 ID 引用锚元素)。 img元素只能引用电子图书的本地图片:该元素不能引用 Web 上的图片。- 避免使用
script:EPUB 阅读器不一定支持 JavaScript 代码。
EPUB 支持 CSS 的方式有一些细微的差别,但是不会影响样式表的一般用法(详情参阅 OPS 规范)。清单 10 中的简单 CSS 文件可以设置基本的字体,并把标题设为红色。
清单 10. 电子图书的示例样式表(stylesheet.css)
body {
font-family: sans-serif;
}
h1,h2,h3,h4 {
font-family: serif;
color: red;
} |
有趣的是,EPUB 非常支持 CSS 2 @font-face 规则,允许内嵌字体。如果创建技术文档,这点可能无关紧要,但是如果用多种语言或针对特定领域编写 EPUB,能够指定具体的字体数据就很有必要了。
现在已经准备好了创建 EPUB 图书所需的所有内容。下一节将按照 OCF 规范将图书装订起来,并看看如何进行验证。
/////////////////////////////////////////////////////////////////////////////////////////////Page4
打包和检查 EPUB
现在,应当可以对 EPUB 包进行打包。这个包可以是您自己创建的一本新书,也可使用从本文 下载 部分获得的原始文件。
EPUB 规范的 OEBPS Container Format 讨论了 EPUB 和 ZIP,最重要的几点是:
- 档案中的第一个文件必须是 mimetype 文件(参见本教程 Mimetype一节)。mimetype 文件不能被压缩。这样非 ZIP 工具就能从 EPUB 包的第 30 个字节开始读取原始字节,从而发现 mimetype。
- ZIP 档案不能加密。EPUB 支持加密,但不是在 ZIP 文件这一层上。
在类 UNIX® 操作系统上,使用 ZIP 2.3 可通过两个命令来创建 EPUB ZIP 文件,如 清单 11 所示(这些命令假设当前工作目录为 EPUB 项目。)
清单 11. 将 EPUB 打包成有效的 epub+zip 文件
$ zip -0Xq my-book.epub mimetype $ zip -Xr9Dq my-book.epub * |
第一个命令创建了一个新的 ZIP 档案,并添加了没有进行压缩的 mimetype 文件。第二个命令添加其他内容。选项 -X 和 -D 最大限度地减少 .zip 文件中无关紧要的信息;-r 递归地包含 META-INF 和 OEBPS 目录的内容。
虽然 EPUB 标准并不很难,但其 XML 文件必须符合特定的模式。如果使用模式感知的 XML 编辑器生成元数据和 XHTML,就能事半功倍。对 EpubCheck 包进行最后检查(参见 参考资料)。
Adobe 负责维护 EpubCheck 包,它是采用 Berkeley Software Distribution (BSD) 许可证的开源项目。它是一个可以作为独立工具、Web 应用程序运行的 Java 程序,或者可以将它集成到在 Java Runtime Environment (JRE) 1.5 或更高版本下运行的应用程序中。
在命令行中运行非常简单。清单 12 给出了一个例子。
$ java -jar /path/to/epubcheck.jar my-book.epub |
如果没有创建辅助文件或者元数据文件出错,可能会看到 清单 13 所示的错误消息。
my-book.epub: image file OEBPS/images/cover.png is missing
my-book.epub: resource OEBPS/stylesheet.css is missing
my-book.epub/OEBPS/title.html(7): 'OEBPS/images/cover.png':
referenced resource missing in the package
Check finished with warnings or errors!
|
这时候可能需要设置 CLASSPATH 使它指向 EpubCheck 的安装位置,因为确实需要导入几个外部库。如果得到这样的消息则需要设置 CLASSPATH:
org.xml.sax.SAXParseException: no implementation available for schema language with namespace URI "http://www.ascc.net/xml/schematron" |
如果验证成功,就会看到 “No errors or warnings detected(没有检测到错误或警告)”。祝贺您完成了第一个 EPUB!
测试不仅仅是验证,还要保证书的外观看起来不错。样式表能正确工作吗?章节的逻辑顺序是否正确?书中是否包含了所有需要的内容?
有多重 EPUB 阅读器可供选择。图 1 显示了 Adobe Digital Editions (ADE) 的屏幕截图,这是最常用的 EPUB 阅读器。
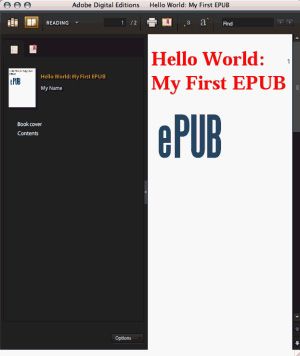
字体颜色和图像都显示出来了,不错。ADE 未能用 sans-serif 字体正确地显示标题,不过这可能是 CSS 的问题。这时候最好换一个阅读器试试。图 2 是用我自己编写的、开放源代码的、基于 Web 的 EPUB 阅读器 Bookworm 显示的同一本书。
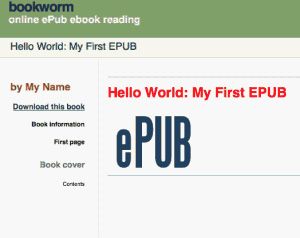
这里的问题在于 ADE 不支持这种特殊声明。如果数字图书的格式非常重要,那么就必须了解不同阅读软件的特点。
前面我们费了很大力气手工创建了一个简单的 EPUB,现在看看如何将一种常见的 XML 文档 DocBook 转换成 EPUB。
/////////////////////////////////////////////////////////////////////////////////////////////Page5
从 DocBook 到 EPUB
DocBook 是需要维护大型技术文档的开发人员常用的选择。与传统字处理程序生成的文件不同,可以使用基于文本的版本控制系统管理 DocBook 输出。由于 DocBook 是 XML,很容易将其转换成不同输出格式。2008 年夏天出现了正式的 DocBook XSL 项目,将 EPUB 作为一种输出格式。
从一个简单 DocBook 文档开始,如 清单 14 所示。该文档的类型为 book,包括前言、两个章节以及标题页面中内联显示的图像。图像和 DocBook 源文件的目录相同。可以自己创建该文件和标题页,也可 下载 本文提供的例子。
<?xml version="1.0" encoding="utf-8"?`>
<book>
<bookinfo>
<title>My EPUB book</title>
<author><firstname>Liza</firstname>
<surname>Daly</surname></author>
<volumenum>1234</volumenum>
</bookinfo>
<preface id="preface">
<title>Title page</title>
<figure id="cover-image">
<title>Our EPUB cover image icon</title>
<graphic fileref="cover.png"/>
</figure>
</preface>
<chapter id="chapter1">
<title>This is a pretty simple DocBook example</title>
<para>
Not much to see here.
</para>
</chapter>
<chapter id="end-notes">
<title>End notes</title>
<para>
This space intentionally left blank.
</para>
</chapter>
</book>
|
然后从 参考资料 下载最新版本的 DocBook XSL 样式表,并安装 xsltproc 或 Saxon 之类的 XSLT 处理程序。本文使用 xsltproc,大多数类 UNIX 系统上都能找到。转换 DocBook 文件,只需要用 DocBook XSL 中包含的 EPUB 模块运行该文件即可,如 清单 15 所示。
$ xsltproc /path/to/docbook-xsl-1.74.0/epub/docbook.xsl docbook.xml Writing OEBPS/bk01-toc.html for book Writing OEBPS/pr01.html for preface(preface) Writing OEBPS/ch01.html for chapter(chapter1) Writing OEBPS/ch02.html for chapter(end-notes) Writing OEBPS/index.html for book Writing OEBPS/toc.ncx Writing OEBPS/content.opf Writing META-INF/container.xml |
然后添加 mimetype 文件并建立 epub+zip 档案。清单 16 显示了这三个命令和通过 EpubCheck 验证程序的结果。
$ echo "application/epub+zip" > mimetype $ zip -0Xq my-book.epub mimetype $ zip -Xr9D my-book.epub * $ java -jar epubcheck.jar my-book.epub No errors or warnings detected |
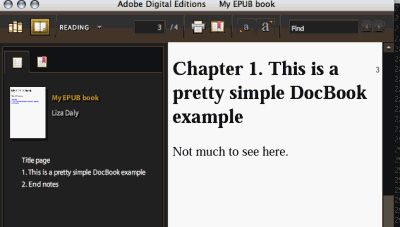
太简单了!图 3 显示了 ADE 中的结果。
图 3. ADE 显示了从 DocBook 转化得到的 EPUB
利用 Python 和 lxml 实现 DocBook-to-EPUB 转换自动化
DocBook XSL 大大降低了生成 EPUB 的复杂性,但是在 XSLT 之外还有几个步骤要执行。最后一节给出的 Python 示例程序能够生成有效的 EPUB 包。本教程显示了不同的方法,可 下载 完整的 docbook2epub.py 程序。
可使用不同的 Python XSLT 库,我喜欢 lxml。它不但提供了 XSLT 1.0 必要的功能,而且解析效率高,完全支持 XPath 1.0,提供了专门处理 HTML 的扩展。如果喜欢不同的库或者使用 Python 以外的编程语言,修改这些例子也很简单。
使用 lxml 调用 XSLT 的最有效办法是事先解析 XSLT,然后创建反复使用的转换器。这样很方便,因为我的 DocBook-to-EPUB 需要转换多个 DocBook 文件。如 清单 17 所示。
import os.path
from lxml import etree
def convert_docbook(docbook_file):
docbook_xsl = os.path.abspath('docbook-xsl/epub/docbook.xsl')
# Give the XSLT processor the ability to create new directories
xslt_ac = etree.XSLTAccessControl(read_file=True,
write_file=True,
create_dir=True,
read_network=True,
write_network=False)
transform = etree.XSLT(etree.parse(docbook_xsl), access_control=xslt_ac)
transform(etree.parse(docbook_file))
|
DocBook XSL 中的 EPUB 模块创建输出文件本身,因此转换过程什么也不返回。相反,DocBook 在当前工作目录中创建了两个文件夹(META-INF 和 OEBPS),包含转换的结果。
DocBook XSL 不会对文档中使用的任何图片执行操作,仅仅创建元数据文件和要呈现的 XHTML。由于 EPUB 规范要求 content.opf manifest 列出所有资源,可以预料到 manifest 将寻找原始 DocBook 文件引用的任何图片。清单 18 显示了这种技术,其中假定 path 变量包含 DocBook XSLT 生成的、当前所处理的 EPUB 的路径。
import os.path, shutil
from lxml import etree
def find_resources(path='/path/to/our/epub/directory'):
opf = etree.parse(os.path.join(path, 'OEBPS', 'content.opf'))
# All the opf:item elements are resources
for item in opf.xpath('//opf:item',
namespaces= { 'opf': 'http://www.idpf.org/2007/opf' }):
# If the resource was not already created by DocBook XSL itself,
# copy it into the OEBPS folder
href = item.attrib['href']
referenced_file = os.path.join(path, 'OEBPS', href):
if not os.path.exists(referenced_file):
shutil.copy(href, os.path.join(path, 'OEBPS'))
|
DocBook XSL 不会创建 mimetype 文件,不过 清单 19 中所示的代码可以完成这项任务。
def create_mimetype(path='/path/to/our/epub/directory'):
f = '%s/%s' % (path, 'mimetype')
f = open(f, 'w')
# Be careful not to add a newline here
f.write('application/epub+zip')
f.close()
|
现在只需要将文件打包成有效的 EPUB ZIP 包。需要分两步:将未经压缩的 mimetype 文件作为第一个文件加进去,然后添加其他目录。如 清单 20 所示。
清单 20. 使用 Python zipfile 模块创建 EPUB 包
import zipfile, os
def create_archive(path='/path/to/our/epub/directory'):
'''Create the ZIP archive. The mimetype must be the first file in the archive
and it must not be compressed.'''
epub_name = '%s.epub' % os.path.basename(path)
# The EPUB must contain the META-INF and mimetype files at the root, so
# we'll create the archive in the working directory first and move it later
os.chdir(path)
# Open a new zipfile for writing
epub = zipfile.ZipFile(epub_name, 'w')
# Add the mimetype file first and set it to be uncompressed
epub.write(MIMETYPE, compress_type=zipfile.ZIP_STORED)
# For the remaining paths in the EPUB, add all of their files
# using normal ZIP compression
for p in os.listdir('.'):
for f in os.listdir(p):
epub.write(os.path.join(p, f)), compress_type=zipfile.ZIP_DEFLATED)
epub.close()
|
好了!切记要进行验证。
/////////////////////////////////////////////////////////////////////////////////////////////Page6
结束语
上一节 中的 Python 脚本仅仅是充分实现 EPUB 转换自动化的第一步。为了简化起见,没有涉及一些常见的情况,比如任意嵌套的路径、样式表或者内嵌字体。Ruby 爱好者可以看看 DocBook XSL 分发包中所含的 dbtoepub,方法与此类似。
因为 EPUB 还是一种比较年轻的格式,很多有效的转换方法还等待人们去创造。所幸的是,多数结构化标记,如 reStructuredText 或 Markdown 都已经存在生成 HTML 或者 XHTML 的渠道了;稍加修改来生成 EPUB 应该非常容易,尤其是有了本文所示的 DocBook-to-EPUB Python 或 Ruby 脚本这些例子以后。
因为 EPUB 基本上就是 ZIP 和 XHTML,与其使用 .zip 文件,没有理由不使用 EPUB 来分发文档。拥有 EPUB 阅读器的读者可从传统元数据和自动目录表收益,没有阅读器的读者也可将其作为一般 ZIP 文件并在浏览器中查看 XHTML 内容。考虑将 EPUB 生成的代码添加到各类文档系统中,如 Javadoc 或 Perldoc。EPUB 是为具有图书长度的文档设计的,因此非常适合越来越多的在线或者渐进式编程图书。
涉及下载请参考原文地址