前言
微信搜【 Java3y】关注这个有梦想的男人,点赞关注是对我最大的支持!文本已收录至我的GitHub:https://github.com/ZhongFuCheng3y/3y,有300多篇原创文章,最近在连载面试和项目系列!
今天想跟大家一起入门一下kylin(麒麟)。
由于工作需要,前段时间对kylin简单入了个门,现在来写写笔记(我的文字或许能帮助到你入门kylin,至少看完这篇应该能知道kylin是干什么的)。
不多BB,开始吧

kylin介绍
kylin是我们国人主导并贡献到Apache基金会的开源项目,所以我们会有中文文档学习:
http://kylin.apache.org/cn/
从官方我们可以看到对kylin的介绍:Apache Kylin™是一个开源的、分布式的分析型数据仓库,提供Hadoop/Spark 之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由 eBay 开发并贡献至开源社区,它能在亚秒内查询巨大的表。
看到这个介绍,只能用两个字来形容kylin:牛逼。那牛逼在哪呢?下面再说
第一眼看过去,可能有的同学不知道OLAP是什么东西,我下面来简单解释一下吧。(Hadoop/Spark/SQL/大数据这些词天天能看见,即便不懂它的原理,你都知道这些东西是有什么用,是用来干嘛的,对吧?)
看到OLAP就不得不提它的兄弟OLTP,我们简单来看看他们的全称和翻译的中文是什么:
- OLTP:On-Line Transaction Processing(联机事务处理)
- OLAP:On-Line Analytical Processing(联机分析处理)
中文的翻译我们怕是看不懂的了,但我们可以发现他俩的区别一个是「事务」,一个是「分析」
从应用层面看,我们可以简单地认为:OLTP主要用于业务系统,对事务的要求比较高,例如下单/交易(银行转账等业务)。OLAP主要用于数据仓库系统,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
我再画张思维导图图来给大家看一下,基本就懂了:

看到这里,你应该对OLAP有个基本的了解了。那再回到上面那句话:多维分析(OLAP)能力以支持超大规模数据,你第一反应会想到什么?
三歪第一反应想到的就是Hive(Hive底层是HDFS:支持超大规模的数据)。
那既然说到Hive了,你会发现kylin前半段话,Hive好像几乎都可以支持,但除了最后一句「它能在亚秒内查询巨大的表」。
没错,到这里就可以知道kylin的用途了:它可以在亚秒内查询巨大的表,来完成数据分析和决策
每次跑Hive我们可能都得跑几分钟(像我SQL写得烂的,跑半小时也是经常有的事),我们从业务上就希望用来分析的数据可以跑得更快,支持这种需求的kylin就火起来了。

我以Hive来引申kylin,除了kylin就没其他选择了吗?那显然不是的。
当年我刚进公司的时候,吐槽Hive跑得太慢了,隔壁的小哥就告诉我:你用presto啊,我们大数据平台都支持的。
OLAP所提供的工具框架还是很多的,下面我们来简单认识一下吧

众所周知,执行Hive实际上是跑Map-Reduce任务去HDFS拿数据。执行的过程涉及到计算和存储。
有的人觉得Hive跑Map-Reduce计算这个过程太慢了,所以就不用Map-Reduce,用别的计算引擎,比如用MPP架构来跑,但存储没变...
有的人觉得,存储在HDFS去拿数据太慢了,改个存储的地方,不从HDFS拿...
有的人觉得,这啥破玩意,计算和存储我都改了,用我的框架一站式给你解决掉...
有的人觉得,Hadoop生态还是可以的,我先聚合一把,你查的时候直接拿聚合后的数据,也是很快的...
由于每个公司的业务场景和背景不一样,每个OLAP框架的长处也不一样,所以现在有如此多的OLAP技术在发光发热...
Kylin入门
从前面我们已经知道为什么会出现如此多的OLAP的技术了,从本质上来说就是我们希望分析的数据可以让我们查得更快,而kylin是这些技术其中的一员。
从上图也可以看到kylin是完全依赖Hadoop生态的,那kylin是怎么实现提速的呢?答案就是:预聚合
假设我们从MySQL检索日期大于2020-10-20的所有数据,只要我们在日期列加上索引,可以很快就能查出相关的数据。
但如果我们从MySQL检索日期大于2020-10-20的所有数据且每个用户在这段时间内消费了多少钱且xxxx,只要数据量大,不论你怎么建索引,查询的速度就不尽人意了。
那如果我按天的维度先做好对每个用户的统计,写到一张表中,等到用户按日期检索的时候是不是就很快了(因为我已经按天聚合了一次数据,这张表比起原来的原始表数量会大大减少)
kylin就是用预聚合这种思路来提高查询的速度,使它可以在亚秒内实现查询响应。
那我们使用kylin的步骤是什么?官方已经帮我们解答了:
- 定义数据集上的一个星形或雪花形模型
- 在定义的数据表上构建
cube - 使用标准
SQL通过ODBC、JDBC或RESTFUL API进行查询,仅需亚秒级响应时间即可获得查询结果
上面几个步骤,可能你不太了解的几个词有以下 星形模型、雪花模型、cube,下面我来简单解释一下:
在数据仓库领域上,我们的主表叫做事实表,事实表外键依赖的表叫做维度表。
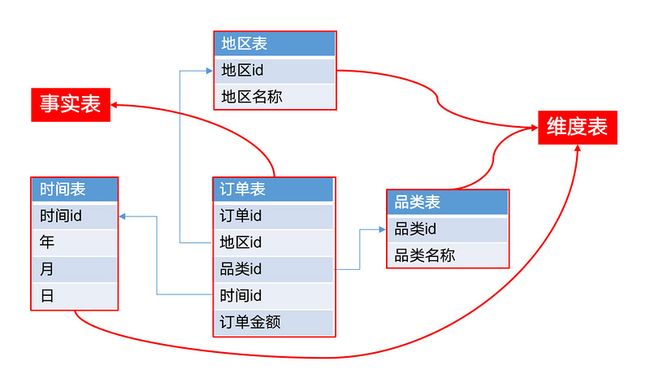
「星形模型」:所有的维度表都直连到事实表。(上图)
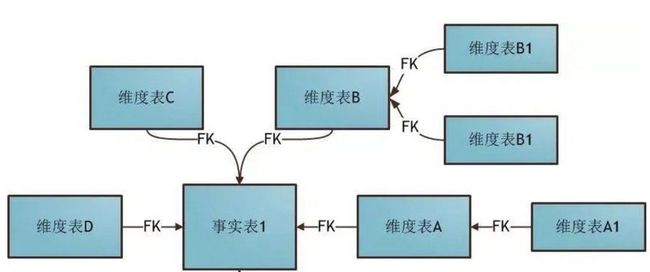
「雪花形模型」:当有一个或多个维度表没有直接连接到事实表上,而需要通过其他维表连接到事实表(下图)
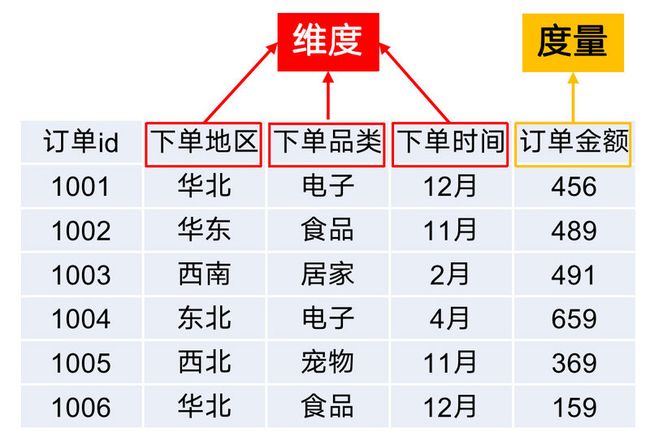
在kylin里,分析数据的角度叫做「维度」,被分析的指标叫做「度量」
好了,我们再来看看cube是什么意思吧:
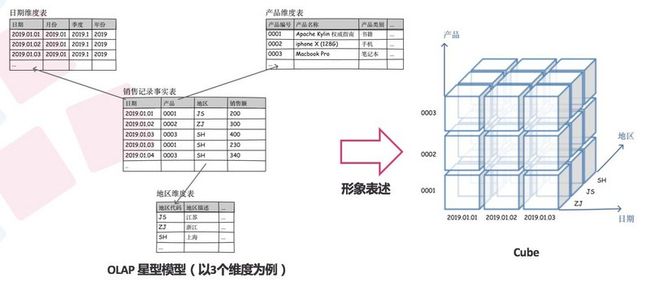
一个多维数据集称为一个OLAP Cube:上面的几张二维表我们可以形成一个数据立方体,这个数据立方体就是Cube
一个Cube可以由不同的角度去看,可以看似这多个角度都是从一个完整的Cube拆分出来的,例如:
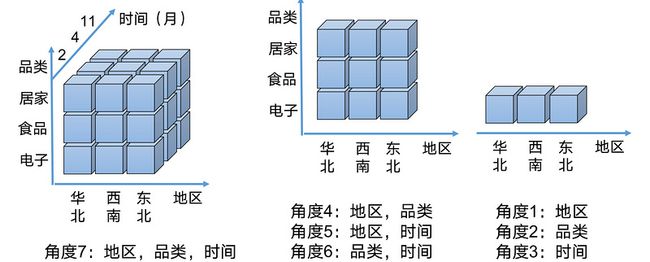
结合上面所说的:Cube实际上就是从数据集中通过不同的维度构建出来的一个立方体(虽然图上的都是三维,但你构建的Cube可以远超三维)
kylin就是在Cube这个立方体来获取数据的,从官方的说法也很明确,可以通过JDBC/RESTful的方式来获取数据。
那kylin是将聚合的数据存储在哪的呢(肯定是有存储的地方的嘛)?在HBase上。如果还没学过HBase的同学,可以先看看我以往的文章:HBase入门
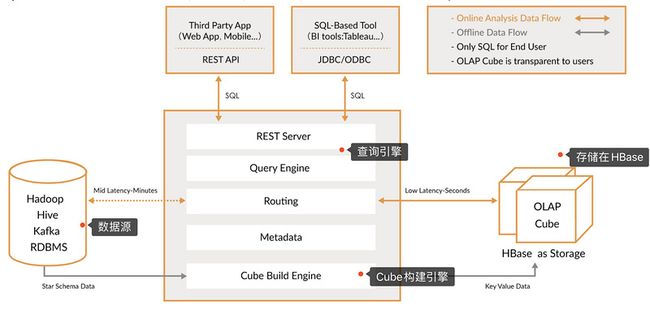
使用kylin步骤:
- 首先你得有数据(一般来自
Hive/Kafka),在Kylin上定义对应的数据模型(结构) - 通过
kylin系统配置需要聚合以及统计的字段(这块就是上面所提到的维度和度量),然后构建出Cube(这块就是kylin的预聚合,把需要统计的维度都定义好,提前计算) kylin会把数据存放在HBase上,你可以通过JDBC/RESTful的方式来查询数据
使用kylin
在官网上也列出比较常见的QA,大家可以看看:http://kylin.apache.org/cn/docs/gettingstarted/faq.html
虽然kylin能支持多维度的聚合,但我们在建Cube一般要对Cube进行剪枝(即减少Cuboid的生成)
假设我们有10 个维度,那么没有经过任何优化的Cube就会存在2的十次方 =1000+个Cuboid。
Cube 的最大物理维度数量 (不包括衍生维度) 是 63,但是不推荐使用大于 30 个维度的 Cube,会引起维度灾难。
常用的剪枝方式会用聚合组(Aggregation group)配置来实现,而在聚合组中,Mandatory(强制维度)又是用得比较多的。
比如说,本来我有A、B、C三个维度,如果我不做任何优化,我的组合应该会有7个,分别是(A)(B)(C)(AB)(ABC)(AC)(BC),如果我指定A维度为强制维度,那最后的组合就只有(A)(AB)(ABC)(AC)。强制索引指的就是:指定的字段一定会被查询条件中
除了强制维度(Mandatory),还有层级维度(Hierarchy)和联合维度(Joint)帮助我们剪枝(即减少Cuboid的生成),一般强制维度和联合维度用得比较多。
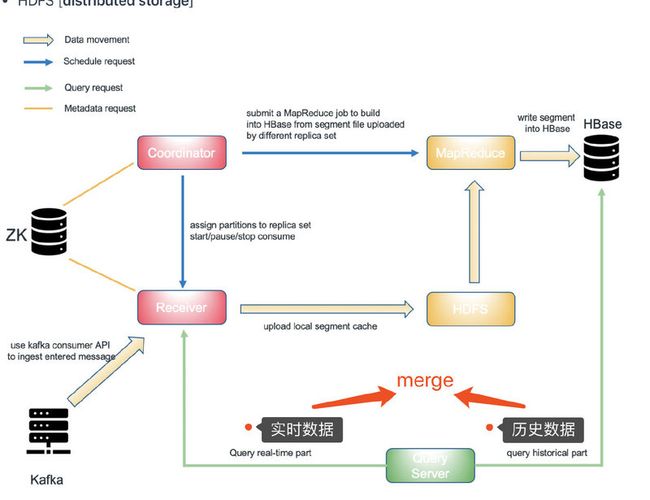
我们去查kylin数据的时候,是已经被聚合过存放在HBase的,所以查询起来是相当快的,但是构建Cube这个过程其实是挺慢的(十几分钟到半小时都是正常的)。
这就会带来延迟(Cube需要时间构建,同时也不可能秒级去请求构建一次Cube)那这能忍受吗?这意味着最新的数据得等Cube任务调度到了且Cube构建完成才能查到数据
画外音:构建Cube一般都是定时任务的方式请求kylin的api进行构建的。Kylin 没有内置的调度程度。您可以通过 REST API 从外部调度程度服务中触发 Cube 的定时构建,如 Linux 的命令
crontab、Apache Airflow 等。
但在新的kylin版本中已经支持realtime_olap了,kylin存储了实时的数据再加上HBase的数据merge后返回就实现了realtime
最后
这篇文章对kylin做了个简单的入门,细节还是得看官网(有中文,比较好读,文档也做得挺好的)。后面细节如果有必要我再来补充就好了(:
参考资料:
三歪把【大厂面试知识点】、【简历模板】、【原创文章】全部整理成电子书,共有1263页!点击下方链接直接取就好了
PDF文档的内容均为手打,有任何的不懂都可以直接来问我
