Common Type System—Memory Layout at C# Online.NET
Memory Layout
Let’s briefly consider the memory layout for objects and values. It should help to illustrate some of the fundamental differences. Consider if we had a class and a struct, both containing two int fields:
class SampleClass
{
public int x;
public int y;
}
struct SampleStruct
{
public int x;
public int y;
}
They both appear similar, but instances of them are quite different. This can be seen graphically in Figure 1, and is described further below.
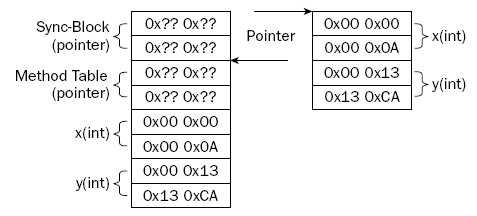
Figure 1: Object and value memory layout.
You’ll immediately notice that the size of a value is smaller than that of an object.
Object Layout
An object is completely self-describing. Areference to it is the size of a machine pointer—that is, 32 bits on a 32-bit machine, 64 bits on a 64-bit—that points into the GC heap. The target of the pointer is actually another pointer, which refers to an internal CLR data structure called a method table. The method table facilitates method calls and is also used to obtain an object’s type dynamically. The double word before that (fancy name for 4 bytes, or 32 bits) makes up the so-called sync-block, which is used to store such miscellaneous things as locking, COM interoperability, and hash code caching (among others). After these come the actual values that make up instance state of the object.
The sum of this is that there is roughly a quad word (8-byte, 64-bit) overhead per object. This is, of course, on a 32-bit machine; for 64-bit machines, the size would be slightly larger. The exact number is an implementation detail and can actually grow once you start using certain parts of the runtime. For example, the sync-block points at other internal per-object runtime data structures that can collect dust over time as you use an object.
Value Layout
Values are not self-describing at all. Rather they are just a glob of bytes that compose its state. Notice above that the pointer just refers to the first byte of our value, with no sync-block or method table involved. You might wonder how type checking is performed in the absence of any type information tagged to an instance. A method table does of course exist for each value type. The solution is that the location in which a value is stored may only store values of a certain type. This is guaranteed by the verifier.
For example, a method body can have a number of local slots in which values may be stored, each of which stores only values of a precise type; similarly, fields of a type have a precise type. The size of the storage location for values is always known statically. For example, the SampleStruct above consumes 64 bits of space, because it consists of two 32-bit integers. Notice that there is no overhead—what you see is what you get. This is quite different from reference types, which need extra space to carry runtime type information around. In cases where structs aren’t properly aligned, the CLR will pad them; this occurs for structs that don’t align correctly on word boundaries.
- Note that the layout of values can be controlled with special hints to the CLR. This topic is discussed below when we talk about the subject of fields.
Lastly, because values are really just a collection of bytes representing the data stored inside an instance, a value cannot take on the special value of null. In other words, 0 is a meaningful value for all value types. The Nullable<T> type adds support for nullable value types. We discuss this shortly.
Discovering a Type’s Size
The size of a value type can be discovered in C# by using the sizeof(T) operator, which returns the size of a target type T. It uses the sizeof instruction in the IL:
Console.WriteLine(sizeof(SampleStruct));
For primitive types, this simply embeds the constant number in the source file instead of using the sizeof instruction, since these do not vary across implementations. For all other types, this requires unsafe code permissions to execute.
Object and Value Unification
As we’ve seen, objects and values are treated differently by the runtime. They are represented in different manners, with objects having some overhead for virtual method dispatch and runtime type identity, and values being simple raw sequences of bytes. There are some cases where this difference can cause a mismatch between physical representation and what you would like to do. For example:
-
- Storing a value in a reference typed as
Object, either a local, field, or argument, for example, will not work correctly. A reference expects that the first double word it points to will be a pointer to the method table for an object.
- Storing a value in a reference typed as
-
- Calling methods on a value that have been defined on a type other than the value requires that a
thispointer compatible with the original method definition be defined. The value of a derived value type will not suffice.
- Calling methods on a value that have been defined on a type other than the value requires that a
-
- Invoking virtual methods on a value requires a virtual method table, as described in the section on virtual methods. A value doesn’t point to a method table, due to the lack of a method table, and thus we could not dispatch correctly.
-
- Similar to virtual methods, calling interface methods requires that an interface map be present. This is only available through the object’s method table. Values don’t have one.
To solve all four of these problems, we need a way to bridge the gap between objects and values.
Boxing and Unboxing
This is where boxing and unboxing come into the picture. Boxing a value transforms it into an object by copying it to the managed GC heap into an object-like structure. This structure has a method table and generally looks just like an object such that Object compatibility and virtual and interface method dispatch work correctly. Unboxing a boxed value type provides access to the raw value, which most of the time is copied to the caller’s stack, and which is necessary to store it back into a slot typed as holding the underlying value type.
Some languages perform boxing and unboxing automatically. Both C# and VB do. As an example, the C# compiler will notice assignment from int to object in the following program:
int x = 10;
object y = x;
int z = (int)y;
It responds by inserting a box instruction in the IL automatically when y is assigned the value of x, and an unbox instruction when z is assigned the value of y:
ldc.i4.s 10
stloc.0
ldloc.0
box [mscorlib]System.Int32
stloc.1
ldloc.1
unbox.any [mscorlib]System.Int32
stloc.2
The code loads the constant 10 and stores it in the local slot 0; it then loads the value 10 onto the stack and boxes it, storing it in local slot 1; lastly, it loads the boxed 10 back onto the stack, unboxes it into an int, and stores the value in local slot 2. You might have noticed the IL uses the unbox.any instruction. The difference between unbox and unbox.any is clearly distinguished in Chapter 3, although the details are entirely an implementation detail.
Null Unification
A new type, System.Nullable<T>, has been added to the BCL in 2.0 for the purpose of providing null semantics for value types. It has deep support right in the runtime itself. (Nullable<T> is a generic type. If you are unfamiliar with the syntax and capabilities of generics, I recommend that you first read about this at the end of this chapter. The syntax should be more approachable after that. Be sure to return, though; Nullable<T> is a subtly powerful new feature.)
The T parameter for Nullable<T> is constrained to struct arguments. The type itself offers two properties:
namespace System
{
struct Nullable<T> where T : struct
{
public Nullable(T value);
public bool HasValue { get; }
public T Value { get; }
}
}
The semantics of this type are such that, if HasValue is false, the instance represents the semantic value null. Otherwise, the value represents its underlying Value. C# provides syntax for this. For example, the first two and second two lines are equivalent in this program:
Nullable<int> x1 = null;
Nullable<int> x2 = new Nullable<int>();
Nullable<int> y1 = 55;
Nullable<int> y2 = new Nullable<int>(55);
Furthermore, C# aliases the type name T? to Nullable<T>; so, for example, the above example could have been written as:
int? x1 = null;
int? x2 = new int?();
int? y1 = 55;
int? y2 = new int?(55);
This is pure syntactic sugar. C# compiles it into the proper Nullable<T> construction and property accesses in the IL.
C# also overloads nullability checks for Nullable<T> types to implement the intuitive semantics. That is, x == null, when x is a Nullable<T> where HasValue == false, evaluates to true. To maintain this same behavior when a Nullable<T> is boxed—transforming it into its GC heap representation— the runtime will transform Nullable<T> values where HasValue == false into real null references. Notice that the former is purely a language feature, while the latter is an intrinsic property of the type’s treatment in the runtime.
To illustrate this, consider the following code:
int? x = null;
Console.WriteLine(x == null);
object y = x; // boxes ‘x’, turning it into a null
Console.WriteLine(y == null);
As you might have expected, both WriteLines print out "True." But this only occurs because the language and runtime know intimately about the Nullable<T> type.
Note also that when a Nullable<T> is boxed, yet HasValue == true, the box operation extracts the Value property, boxes that, and leaves that on the stack instead. Consider this in the following example:
int? x = 10;
Console.WriteLine(x.GetType());
This snippet prints out the string "System.Int32", not "System.Nullable`1<System.Int32>", as you might have expected. The reason is that, to call GetType on the instance, the value must be boxed. This has to do with how method calls are performed, namely that to call an inherited instance method on a value type, the instance must first be boxed. The reason is that the code inherited does not know how to work precisely with the derived type (it was written before it even existed!), and thus it must be converted into an object. Boxing the Nullable<T> with HasValue == true results in a boxed int on the stack, not a boxed Nullable<T>. We then make the method invocation against that.