提到Redis,大家一定会想到的几个点是什么呢?
高并发,KV存储,内存数据库,丰富的数据结构,单线程(6版本之前)
那么,接下来,上面提到的这些,都会一一给大家解答,带大家领略一下Redis的魅力,文章会比较长,部分废话,请大家跳过,谢谢!~
欢迎进群973961276一起聊聊技术吹吹牛,每周都会有几次抽奖送专业书籍的活动,奖品不甚值钱,但也算个搏个彩头
===========================
为什么会出现缓存?
一般情况下,数据都是在数据库中,应用系统直接操作数据库。当访问量上万,数据库压力增大,这个时候,怎么办呢?
有小伙伴会说了,分库分表,读写分离。的确,这些确实是解决比较高的访问量的解决办法,但是,如果访问量更大,10万,100万呢?怎么分似乎都不解决问题吧,所以我们需要用到其他办法,来解决高并发带来的数据库压力。
这个时候,缓存出现了,缓存,顾名思义,就是先把数据缓存在内存中一份,当访问的时候,我们会先访问内存的数据,如果内存中的数据不存在,这个时候,我们再去读取数据库,之后把数据库中的数据再备份一份到内存中,这样下次读请求过来的时候,还是会直接先从内存中访问,访问到内存的数据了之后就直接返回了。这样做就完美的降低了数据库的压力,可能十万个请求进来,全部都访问了内存中备份的数据,而没有去访问数据库,或者说只有少量的请求访问到了数据库,这样真的是大大降低了数据库的压力,而且这样做也提高了系统响应,大家想一下,内存的读写速度是远远大于硬盘的读写速度的,一个请求进来读取的内存可以比读取硬盘快很多很多,用户的体验也会很高。
什么是缓存呢?
缓存原指CPU上的一种高速存储器,它先于内存与CPU交换数据,速度很快
现在泛指存储在计算机上的原始数据的复制集,便于快速访问。
在互联网技术中,缓存是系统快速响应的关键技术之一。
缺乏项目实战经验和想跳槽涨薪或是自我提升的朋友看这里>>c/c++ 项目实战/后台服务器开发高级架构师
觉得文字不好理解的朋友可以配合这个视频一起看>>redis、nginx及skynet源码分析探究(上)
===========================
缓存的读写模式
缓存有三种读写模式
Cache Aside Pattern(常用)
Cache Aside Pattern(旁路缓存),是最经典的缓存+数据库读写模式
读的时候,先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存,同时返回响应。
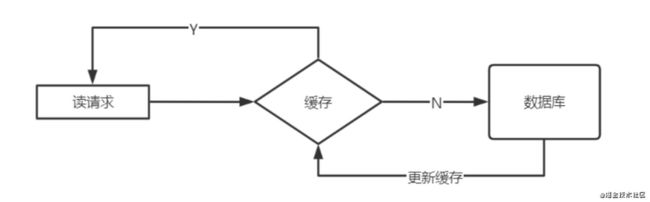
更新的时候,先更新数据库,然后再删除缓存

为什么是删除缓存,而不是更新缓存呢?
1.缓存的值是一个结构,hash,list,更新数据需要遍历
2.懒加载,使用的时候才更新缓存,也可以采用异步的方式填充缓存
高并发脏读的三种情况
1.先更新数据库,在更新缓存
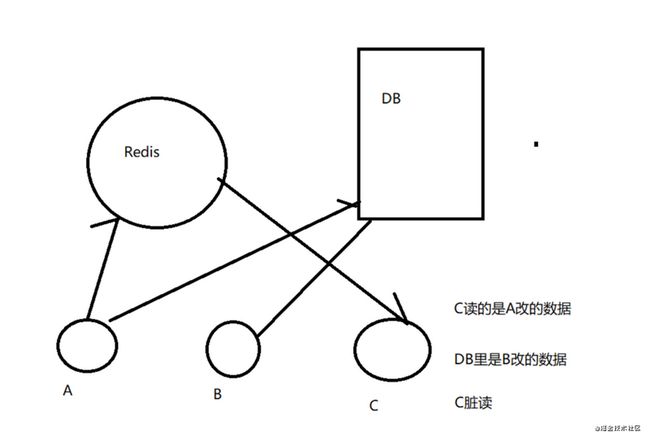
update与commit之间,更新缓存,commit失败,则DB与缓存数据不一致
2.先删除缓存,再更新数据库
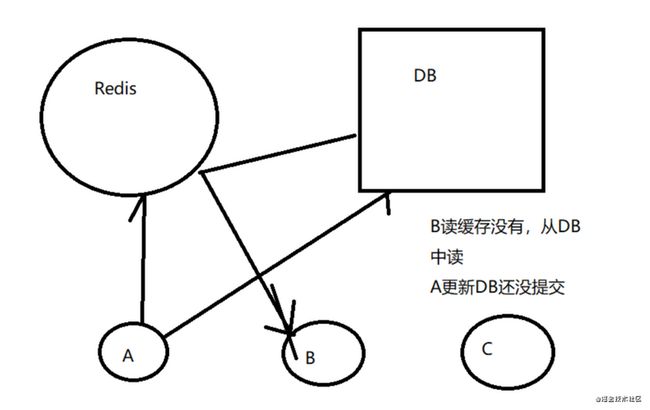
update与commit之间,有新的读,缓存空,读DB数据到缓存,数据是旧的数据
commit后DB为新的数据
则DB与缓存数据不一致
3.先更新数据库,再删除缓存(推荐)
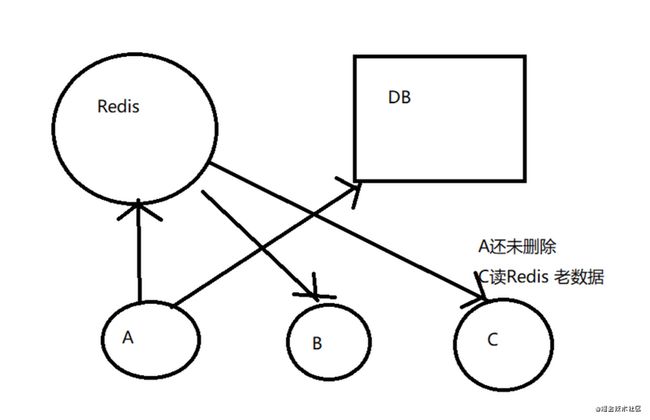
update与commit之间,有新的读,缓存空,读DB数据到缓存,数据是旧的数据
commit后DB为新的数据
则DB与缓存数据不一致
采用延时双删策略
Read/Write Through Pattern
应用程序只操作缓存,缓存操作数据库
Read-Through(穿透读模式/直读模式):应用程序读缓存,缓存没有,由缓存回源到数据库,并写入缓存
Write-Through(穿透写模式/直写模式):应用程序写缓存,缓存写数据库。该种模式需要提供数据库的handler,开发较为复杂
Write Behind Caching Pattern
应用程序只更新缓存
缓存通过异步的方式将数据批量或合并后更新到DB中
不能时时同步,甚至会丢数据
而Redis又是什么呢?
Redis是一个高性能的开源的,C语言写的NoSQL(非关系型数据库)也叫做缓存数据库,数据保存在内存中。Redis是以key-value形式存储,和传统的关系型数据库不一样。不一定遵循传统数据库的那些基本要求。比如,不遵循SQL标准,事务,表结构等。Redis有非常丰富的数据类型,比如String,list,set,zset,hash等
Redis可以做一些什么呢?
- 上面说的可以减轻数据库压力,提高并发量,提高系统响应时间
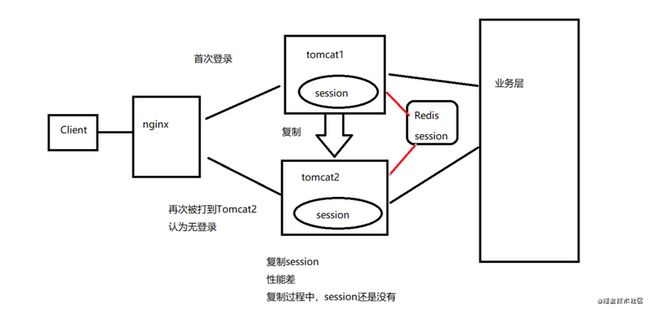
- 做Session分离
传统的Session是由自己的tomcat进行维护和管理的,在集群和分布式情况下,不同的tomcat要管理不同的session,只能在各个tomcat之间,通过网络和IO进行session复制,极大的影响了系统的性能
Redis解决了这一个问题,将登陆成功后的session信息,存放在Redis中,这样多个tomcat就可以共享Session信息了
- 做分布式锁
一般Java中的锁都是多线程锁,是在一个进程中的,多个进程在并发的时候也会产生问题,也要控制时序性,这个时候Redis可以用来做分布式锁,使用Redis的setnx命令来实现
用Redis做缓存,有这么有多优点,那么,缺点是不是也会对应的有很多呢?
- 额外的硬件支出
缓存是一种软件系统中以空间换时间的技术,需要额外的磁盘空间和内存空间来存储数据
- 高并发缓存失效
在高并发的情况下,会出现缓存失效(缓存穿透,缓存雪崩,缓存击穿等问题)造成瞬间数据库访问量增大,甚至崩溃,所以这些问题是一定要去解决的
- 缓存与数据库数据同步
缓存与数据库无法做到数据的时时同步
- 缓存并发竞争
多个Redis客户端同时对一个key进行set值的时候由于执行顺序引起的并发的问题
Redis的安装这里就不说了,mac,windows,linux网上各种安装教程,很多,大家去网上搜搜跟着做就ok了,比较简单,接下来,带着大家来分析一下,Redis中的一些常见的数据类型吧。
Redis的数据结构
Redis是一个key-value的存储系统,key的类型是字符串
Redis中常见的value的数据类型,有五种,string,list,hash,set,zset
string字符串类型
string适合做单值缓存,对象缓存,分布式锁等
命令名称
命令格式
命令描述
set
set key value
赋值
get
get key
取值
getset
getset key value
取值并赋值
setnx
setnx key value
当value不存在时采用赋值
set key value NX PX 3000 原子操作,px 设置毫秒数
append
append key value
向尾部追加值
strlen
strlen key
获取字符串长度
incr
incr key
递增数字
incrby
incrby key increment
增加指定的整数
decr
decr key
递减数字
decrby
decrby key decrement
减少指定的整数
mset
mset key value key value
批量赋值
mget
mget key key
批量取值
接下来,我们执行以下Redis的这些命令
set命令:
127.0.0.1:6379> set name liuxixi
OK
复制代码get命令:
127.0.0.1:6379> set name liuxixi
OK
127.0.0.1:6379> get name
"liuxixi"
复制代码getset命令:
127.0.0.1:6379> getset name lixixi
"liuxixi"
127.0.0.1:6379> get name
"lixixi"
复制代码setnx命令:
127.0.0.1:6379> setnx age 12
(integer) 1 //第一次返回1代表设置成功
127.0.0.1:6379> setnx age 13
(integer) 0 //第二次返回0代表没有设置成功
复制代码append命令:
127.0.0.1:6379> append name xi
(integer) 8 //返回的8是value的长度
127.0.0.1:6379> get name
"lixixixi"
复制代码strlen命令:
127.0.0.1:6379> strlen name
(integer) 8
复制代码incr命令:
127.0.0.1:6379> incr age //可以用来做点赞功能
(integer) 14
127.0.0.1:6379> get age
"14"
复制代码incrby命令:
127.0.0.1:6379> incrby age 3
(integer) 17
127.0.0.1:6379> get age
"17"
复制代码decr命令:
127.0.0.1:6379> decr age
(integer) 16
127.0.0.1:6379> get age
"16"
复制代码decrby命令:
127.0.0.1:6379> decrby age 3
(integer) 13
127.0.0.1:6379> get age
"13"
复制代码hash散列类型
命令名称
命令格式
命令描述
hset
hset key field value
赋值,不区别新增或修改
hmset
hmset field1 value1 field2 value2
批量赋值
hsetnx
hsetnx key field value
赋值,如果filed存在则不操作
hexists
hexists key filed
查看某个field是否存在
hget
hget key field
获取一个字段值
hmget
hmget key field1 field2 ...
获取多个字段值
hgetall
hgetall key
hdel
hdel key field1 field2..
删除指定字段
hincrby
hincrby key field increment
指定字段自增increment
hlen
hlen key
获得字段数量
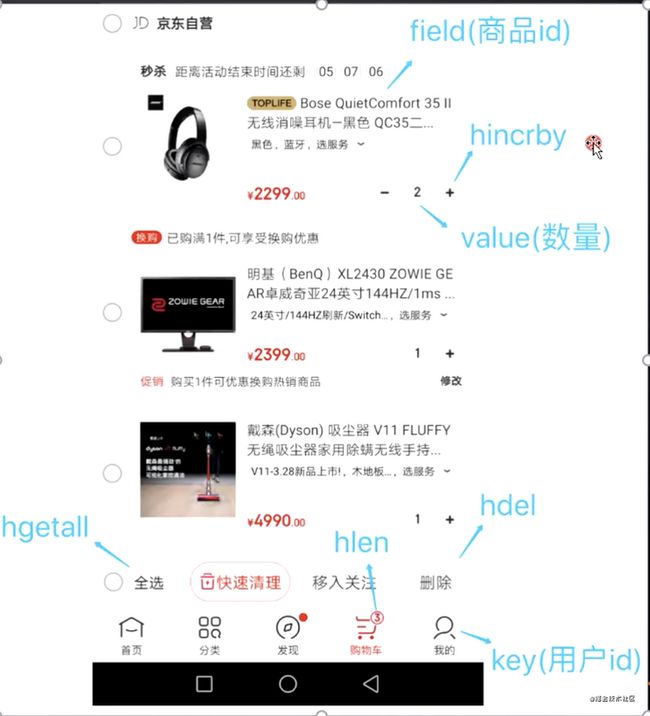
应用场景:可以做电商购物车
电商购物车:
- 以用户id为key
- 商品id为field
- 商品数量为value
购物车操作:
- 添加商品:hset cart:1001 10088 1
- 增加数量:hincrby cart:1001 10088 1
- 商品总数:hlen cart:1001
- 删除商品:hdel cart:1001 10088
- 获取购物车所有商品:hgetall cart:1001
hash结构的优缺点
优点
- 同类数据归类整合存储,方便数据管理
- 相比string操作消耗内存与cpu更小
- 相比string存储更节省空间
缺点
- 过期功能不能使用在field上,只能用在key上
- Redis集群架构下不适合大规模使用
list列表类型
list列表类型可以存储有序,可重复的元素
获取头部或尾部附近的记录是极快的
list的元素个数最多为2^31-1个(40亿)
常见操作命令如下:
命令名称
命令格式
命令描述
lpush
lpush key v1 v2 v3 ...
从左侧插入列表
lpop
lpop key
从列表左侧取出
rpush
rpush key v1 v2 v3 ...
从右侧插入列表
rpop
rpop key
从列表右侧取出
lpushx
lpushx key value
将值插入到列表头部
rpushx
rpushx key value
将值插入到列表尾部
blpop
blpop key timeout
从列表左侧取出,当列表为空时阻塞,可以设置最大阻塞时 间,单位为秒
brpop
blpop key timeout
从列表右侧取出,当列表为空时阻塞,可以设置最大阻塞时 间,单位为秒
llen
llen key
获得列表中元素个数
lindex
lindex key index
获得列表中下标为index的元素 index从0开始
lrange
lrange key start end
返回列表中指定区间的元素,区间通过start和end指定
lrem
lrem key count value
删除列表中与value相等的元素
当count>0时, lrem会从列表左边开始删除;当count<0时, lrem会从列表后边开始删除;当count=0时, lrem删除所有值 为value的元素
lset
lset key index value
将列表index位置的元素设置成value的值
ltrim
ltrim key start end
对列表进行修剪,只保留start到end区间
rpoplpush
rpoplpush key1 key2
从key1列表右侧弹出并插入到key2列表左侧
brpoplpush
brpoplpush key1 key2
从key1列表右侧弹出并插入到key2列表左侧,会阻塞
linsert
linsert key BEFORE/AFTER pivot value
将value插入到列表,且位于值pivot之前或之后
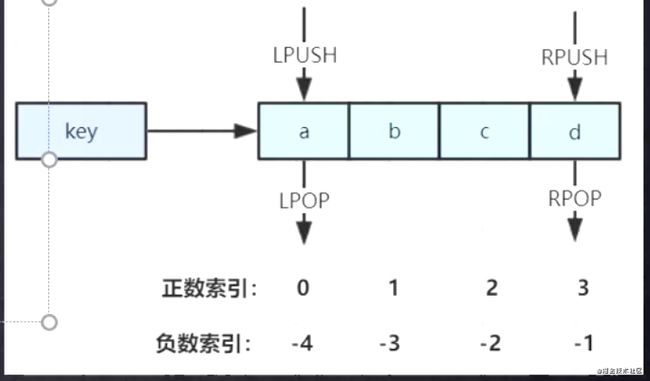
常用数据结构
Stack(栈)=LPUSH+LPOP
Queue(队列)=LPUSH+RPOP
BlockingMQ(阻塞队列)=LPUSH+BRPOP
list应用场景:
微博和微信公众号消息流
微博和公众号都是新发的消息是在最上面的
- MacTalk发微博,消息ID为10018
LPUSH msg:{ID} 10018
- 备胎说车发微博,消息ID为10086
LPUSH msg:{ID} 10086
- 查看最新微博消息
LRANGE msg:{ID} 0 4
如果微博大V,或者微信大V,关注比较高的,几千个,上万个,可以分批发,比如先给在线的发,这样就很快了
set集合类型
set:无序,唯一元素
集合中最大的成员数为2^32-1
常见操作命令如下表:
命令名称
命令格式
命令描述
sadd
sadd key mem1 mem2 ....
为集合添加新成员
srem
srem key mem1 mem2 ....
删除集合中指定成员
smembers
smembers key
获得集合中所有元素
spop
spop key
返回集合中一个随机元素,并将该元素删除
srandmember
srandmember key
返回集合中一个随机元素,不会删除该元素
scard
scard key
获得集合中元素的数量
sismember
sismember key member
判断元素是否在集合内
sinter
sinter key1 key2 key3
求多集合的交集
sdiff
sdiff key1 key2 key3
求多集合的差集
sunion
sunion key1 key2 key3
求多集合的并集
应用场景:
适用于不能重复的且不需要顺序的数据结构
比如:关注的用户,还可以通过spop进行随即抽奖
微信抽奖小程序:
- 点击参与抽奖加入集合
SADD key {userId}
- 查看参与抽奖所有用户
SMEMBERS key
- 抽取count名中奖者
SRANDMEMBER key [count] / SPOP key [count]
微信微博点赞,收藏,标签
- 点赞
SADD like:{消息ID} {用户ID}
- 取消点赞
SREM like:{消息ID} {用户ID}
- 检查用户是否点过赞
SISMEMBMR like:{消息ID} {用户ID}
- 获取点赞的用户列表
SMEMBERS like:{消息ID}
- 获取点赞用户数
SCARD like:{消息ID}
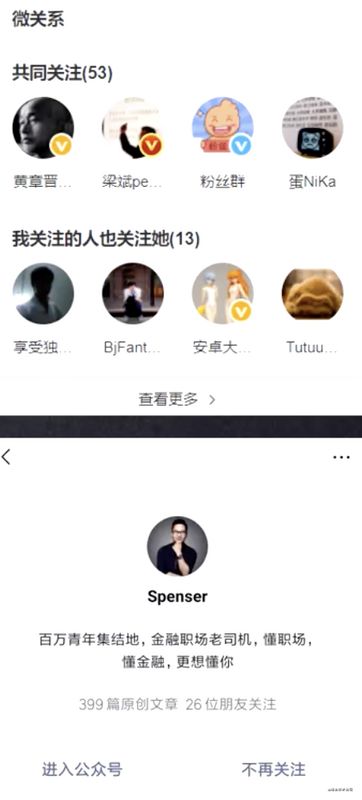
集合操作实现微博微信关注模型
- 你关注的人
xx -> {x , xxx}
- 我关注的人
Ll -> {xx , xxx}
- 我和你关注的人
SINTER xx LI -> {xxx}
- 我关注的人也关注他:
SISMEMBER xx LI
- 我可能认识的人:
SDIFF xx LI -> {xx}
zset有序集合类型
元素本身是无序不重复的
每一个元素关联一个分数(score)
可按分数排序,分数可重复
常见操作命令如下表:
命令名称
命令格式
命令描述
zadd
zadd key score1 member1 score2 member2 ...
为有序集合添加新成员
zrem
zrem key mem1 mem2 ....
删除有序集合中指定成员
zcard
zcard key
获得有序集合中的元素数量
zcount
zcount key min max
返回集合中score值在[min,max]区间 的元素数量
zincrby
zincrby key increment member
在集合的member分值上加increment
zscore
zscore key member
获得集合中member的分值
zrank
zrank key member
获得集合中member的排名(按分值从 小到大)
zrevrank
zrevrank key member
获得集合中member的排名(按分值从大到小)
zrange
zrange key start end
获得集合中指定区间成员,按分数递增 排序
zrevrange
zrevrange key start end
获得集合中指定区间成员,按分数递减 排序
应用场景:
由于可以按照分值排序,所以适用于各种排行榜。比如:点赞排行榜,销量排行榜,关注排行榜等。
举例:
127.0.0.1:6379> zadd hit:1 100 item1 20 item2 45 item3
(integer) 3
127.0.0.1:6379> zcard hit:1
(integer) 3
127.0.0.1:6379> zscore hit:1 item3
"45"
127.0.0.1:6379> zrevrange hit:1 0 -1
1) "item1"
2) "item3"
3) "item2"
127.0.0.1:6379>
复制代码zset集合操作实现排行榜
- 点击新闻
ZINCRBY hotNews:20190819 1 守护香港
- 展示当日排行前十
ZREVRANGE hotNews:20190819 0 9 WITHSCORES
- 七日搜索榜单计算
ZUNIONSTORE hotNews:20190813-20190819 7
hotNews:20190813 hotNews:20190814... hotNews:20190819
- 展示七日排行前十
ZREVRANGE hotNews:20190813-201908109 0 9 WITHSCORES
Redis的单线程和高性能
Redis是单线程的么?
Redis的单线程主要是指Redis的网络IO和键值对读写是由一个线程来完成的,这也是Redis对外提供键值存储服务的主要流程。但Redis的其他功能,比如持久化,异步删除,集群数据同步等,都是由额外的线程执行的。
Redis单线程为什么还能这么快?
这里我们在本地测试一下Redis支持的并发
执行这条命令: ./redis-benchmark get
结果:
====== get ======
100000 requests completed in 1.02 seconds
50 parallel clients
3 bytes payload
keep alive: 1
host configuration "save": 900 1 300 10 60 10000
host configuration "appendonly": no
multi-thread: no
0.00% <= 0.1 milliseconds
13.00% <= 0.2 milliseconds
55.85% <= 0.3 milliseconds
80.60% <= 0.4 milliseconds
92.57% <= 0.5 milliseconds
97.12% <= 0.6 milliseconds
99.06% <= 0.7 milliseconds
99.68% <= 0.8 milliseconds
99.86% <= 0.9 milliseconds
99.90% <= 1.0 milliseconds
99.90% <= 1.1 milliseconds
99.90% <= 1.2 milliseconds
99.91% <= 1.3 milliseconds
99.93% <= 1.4 milliseconds
99.95% <= 1.5 milliseconds
99.97% <= 1.6 milliseconds
99.98% <= 1.7 milliseconds
99.99% <= 1.8 milliseconds
99.99% <= 1.9 milliseconds
100.00% <= 2 milliseconds
100.00% <= 2 milliseconds
98328.42 requests per second
复制代码这里我们可以看到,没秒的话,差不多可以支持小10万的并发,这已经是一个很恐怖的数据了
因为它的所有数据都在内存中,所有的运算都是内存级别的运算,而且单线程避免了多线程的切换性能消耗问题。正因为Redis是单线程的,所以要小心使用Redis命令,对于那些耗时的指令(比如keys),一定要谨慎使用,一不小心就可能导致Redis卡顿。
Redis单线程如何处理那么多并发客户端连接?
Redis的IO多路复用:Redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,一次放到文件事件分派器,事件分派器将事件分发给事件处理器。
Redis的一些其它高级命令
keys
全量遍历键,用来列出所有满足特定正则字符串规则的key,当Redis数据量比较大时,性能比较差,要避免使用
scan:渐进式遍历键
SCAN cursor [MATCH pattern] [COUNT count]
scan参数提供了三个参数,第一个是cursor整数值(hash桶的索引值),第二个是key的正则模式,第三个是一次遍历key的数量(参考值,底层遍历的数量不一定),并不是符合条件的结果数量。第一次遍历时,cursor值为0,然后将返回结果中第一个整数值作为下一次遍历的cursor。一直遍历到返回的cursor值为0时结束。
127.0.0.1:6379> scan 0 match key* count 3
1) "12" //这个12代表返回下一次扫描的游标数,下一次scan就需要从这个数开始扫描
2) 1) "key4"
127.0.0.1:6379> scan 12 match key* count 3
1) "26"
2) 1) "key1"
2) "key3"
复制代码注意:但是scan并非完美无暇,如果在scan的过程中如果有键的变化(增加,删除,修改),那么遍历效果可能会碰到如下问题:新增的键可能没有遍历到,遍历出了重复的键等情况,也就是说scan并不能保证完整的键遍历出来所有的键,这些是我们在开发时需要考虑的。
Redis核心设计原理
Redis作为key-value存储系统,数据结构如下:
一个Redis实例对应多个DB,一个DB对应多个key,key一般都是string的,后面的value叫做RedisObject,不是说value就是string,list,map这些,而是说这些所有的类型,都被Redis封装成了一个叫RedisObjcet,具体是哪个类型呢?这里是用指针的方式来指向具体是哪个类型
为什么要这么做,主要是为了提高Redis的性能
PS:这里插一句,为什么使用指针的方式要比使用对象本身的方式性能更好呢?
这里有两点:
第一点是动态分配,还有指针的一大特点在于你只需要在前面声明一下指针指向的类型(而如果要使用实际的对象,你还需要定义一下)。这样你就能降低你的编译单元之间的耦合性从而减少编译时间
RedisDB结构
Redis没有表的概念,Redis实例所对应的DB以编号区分,DB本身就是key的命名空间
比如:user:1000作为key的值,表示在user这个命名空间下id为1000的元素,类似于user表的id=1000的行
SDS字符串
众所周知,Redis是用C语言来实现的,在C语言中,String这个类型,其实就是一个char数组,比如char data[]="xxx0",但是,客户端往Redis发送set命令,是可以发任意的字符串的,是没有校验的,所以假如我们发了一个字符串xx0xx,那么0后面的xx是不会读的,只会读前面的xx(C语言中用"0"表示字符串结束,如果字符串本身就有"0"字符,字符串就会被截断)
所以Redis自实现了一个string叫sds,sds中记录了一个len和一个char buf[],len用来记录buf的长度,比如char buf[] = "xx0xx",那么len就是5,sds中还有一个比较重要的属性就是free,表示还剩余多少
free是通过改变len来计算,比如"xxx1234" 改成 "xxx123456",那么会按照(len+addlen)*2=18 来扩容,这个时候len变成了9,free就是18-9也变成了9
比如:
char buf[] = "xxx1234" 改成 "xxx123456" //这里的buf是柔性数组
free:12 变成free:10
len:8 变成len:10
复制代码Redis这样设计SDS有什么好处:
- 二进制安全的数据结构
- 提供了内存预分配机制,避免了频繁的内存分配
- 兼容C语言的函数库
- 有单独的统计变量len和free,可以方便的得到字符串长度,这样就避免了读取不完整的风险。
- 内容存放在柔性数组buf中,SDS对上层暴露的指针不是指向结构体SDS的指针,而是直接指向柔性数组buf的指针。上层可像读取C字符串一样读取SDS的内容,兼容C语言处理字符串的各种函数。
这里解释一下什么叫柔型数组:
柔型数组即数组大小待定的数组,C语言中结构体的最后一个元素可以是大小未知的数组,也就是所谓的0长度,所以我们可以用结构体来创建柔性数组。柔性数组主要用途是为了满足需要变长度的结构体,为了解决使用数组时内存的冗余和数组的越界问题
这也是Redis3.2之前所实现的。