——JavaScript版查找树介绍及性能分析
JavaScript版查找树介绍及性能分析
简介: 在字典查询方面有很多经典的算法, 比如Trie(查找树), Bloom Filter(布隆过滤器). 作者在这篇文章用JavaScript实现了查找树算法, 并跟其他算法实现在空间, 时间, 内存消耗各方面做了比较. 原文在http://ejohn.org/blog/javascript-trie-performance-analysis/.
查找树是一种很简单的数据结构, 只有在叶子上才存储着完整的单词, 见下图. 可以看到, 由于单词的前缀都是共享的, 所以在空间上得到极大的压缩. 作者在Github上创建了他自己的JavaScript Trie Generator项目, 有兴趣的可以看看. (注: 基于Node.js)
 生成查找树
生成查找树
最基本的查找树生成算法如下: (注: ’0′或者’$:0′表示是完整的单词)
// 遍历字典里的所有单词
trie = {};
for ( var i = 0, l = words.length; i < l; i++ ) {
// 生成该单词的字母数组
var word = words[i], letters = word.split(""), cur = trie;
// 遍历字母
for ( var j = 0; j < letters.length; j++ ) {
var letter = letters[j], pos = cur[ letter ];
// 如果该字母在树中不存在, 就尝试创建一个叶子
if ( pos == null ) {
// 如果该字母是单词里的最后一个字母, 就置为0,
// 否则创建一个节点
cur = cur[ letter ] = (j === letters.length - 1) ? 0 : {};
// 如果该字母是一个叶子, 那就创建一个对象标记, 并继续遍历
} else if ( pos === 0 ) {
cur = cur[ letter ] = { $: 0 };
// 继续遍历
} else {
cur = cur[ letter ];
}
}
}
优化
在上面的算法中, 假设字典里包含单词["bar", "bars", "foo", "rat", "rate"], 那么生成的最后结构就类似:
var trie = {
b: {
a: {
r: {
$: 0,
s: 0
}
}
},
f: {
o: {
o: 0
}
},
r: {
a: {
t: {
$: 0
e: 0
}
}
}
};
作者之后针对这样的结构做了一些在空间上的优化, 比如那种只有一个子节点的节点可以存储为一个字符串, 比如上面的”r a t”就可以存为”rat”, 如下.
var trie = {
bar: {
$: 0,
s: 0
},
foo: 1,
rat: {
$: 0,
e: 0
}
};
通过这样的方法, 我们创建的JavaScript对象从之前的9个压缩成了3个, 但是很显然, 这个需要我们在查询上做更多的工作. 下面是这个优化查找树结构的代码:
// 优化查找树结构
function optimize( cur ) {
var num = 0;
// 遍历所有节点
for ( var node in cur ) {
// 如果该节点有子节点
if ( typeof cur[ node ] === "object" ) {
// 优化子节点
var ret = optimize( cur[ node ] );
// 如果该节点只有一个子节点
if ( ret ) {
// 删除目前的叶子
delete cur[ node ];
// 新的节点名字
node = node + ret.name;
// 重新组织结构
cur[ node ] = ret.value;
}
}
// 记录处理节点的个数
num++;
}
// 如果该节点只有一个叶子, 那么就压缩
if ( num === 1 ) {
return { name: node, value: cur[ node ] };
}
}
作者在参考有向非循环字图后做了进一步的改进. 除了把相同的前缀提取出来外, 还可以把拥有相同的后缀的单词提取出来.
比如你有6个单词: sliced, slicer, slices, diced, dicer, dices. 最后生成的查找树是:
var trie = {
slice: 1,
dice: 1,
$: [ 0, { d: 0, r: 0, s: 0 } ]
};
也就是, 最后的(d, r, s)是被slice和dice两个前缀共享的.
第一眼看上去这个并不是那么的好, 但是对于超过100,000的单词的字典, 最后结果显示空间的节省非常大. 对于实现可以查看Github.
查找单词
尤其对查找树做了压缩和优化, 查找单词并不想传统的查询, 需要一些额外的工作, 比如indexOf去比较前缀, slice去比较后缀.
function findTrieWord( word, cur ) {
// 设置查询起点
cur = cur || dict;
// 遍历节点
for ( var node in cur ) {
// 如果该单词的头是匹配节点
if ( word.indexOf( node ) === 0 ) {
// 如果该节点是数字
var val = typeof cur[ node ] === "number" && cur[ node ] ?
// 得到后缀对应的树
dict.$[ cur[ node ] ] :
// 当前节点的值
cur[ node ];
// 如果这个单词的所有字母都被查找完了
if ( node.length === word.length ) {
// Return 'true' only if we've reached a final leaf
return val === 0 || val.$ === 0;
// 继续往下查询
} else {
return findTrieWord( word.slice( node.length ), val );
}
}
}
return false;
}
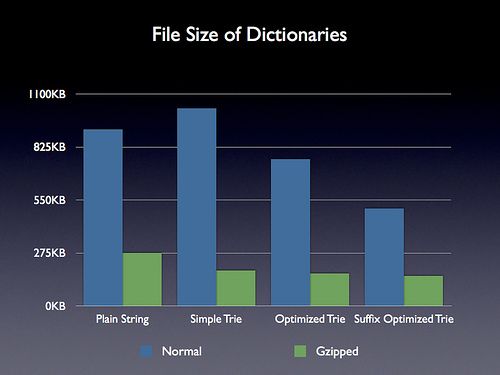
文件大小分析
用查找树最大的好处就是在文件大小上有极大的缩小. 作者采用的纯文本字典保护112429个单词, 大概916KB. 从下图中可以看到基本的string版本字典, 没有优化的查找树, 前缀优化的查找树和后缀优化的查找树在大小上的区别.
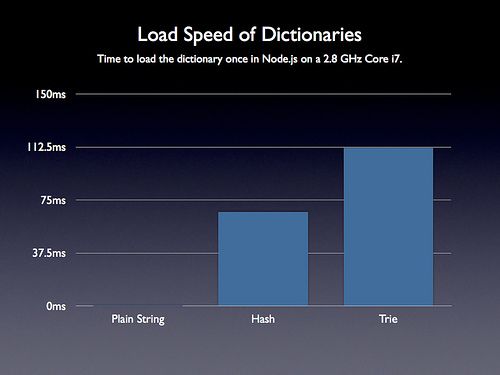
加载速度分析
可惜虽然查找树在文件大小上有个极大的改进, 但是由于需要把串行化后的JS字符串变成可用的数据, 查找树在字典加载速度上比起其他方式看上去就差多了. 更遭的是, 上面的结果是在目前能得到的最快的JavaScript环境下得到的. 在其他普通环境下, 这个结果更坏了. 比如下图的Mobile Safari 4.3.
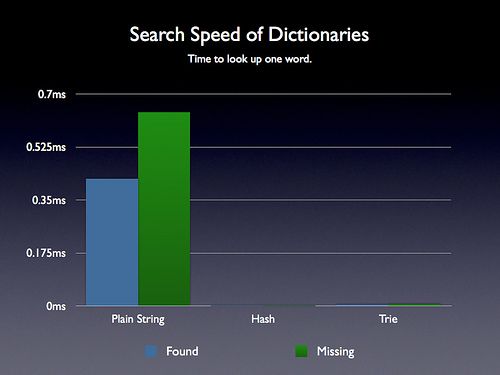
搜索速度分析
可喜的是, 至少在搜索速度上, 查找树是具有优势的. 其复杂度为O(logN).
内存使用分析
我们必须对内存情况要格外的关心, 尤其是你的应用跑在手机平台上时,因为查找树是在构建树的时候分配了对象, 因此它对内存的消耗显然比纯文本方式更大.

大家如果意犹未尽的话, 建议大家看看原文.