首先在进入主题之前我们先来回顾下经典的大数据ETL架构有哪些?
- Lambda架构
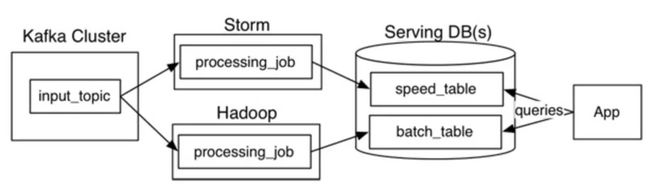
- Kappa架构
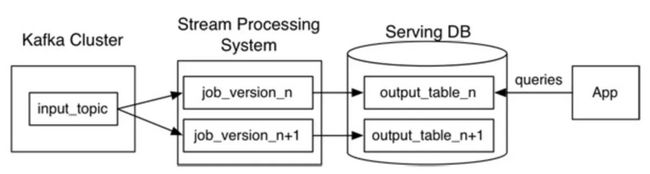
- 混合架构
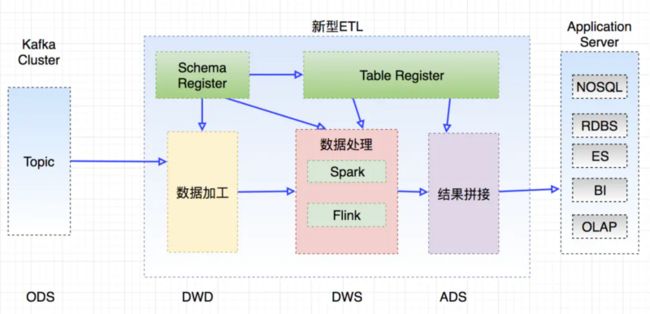
它们之间的区别如下:
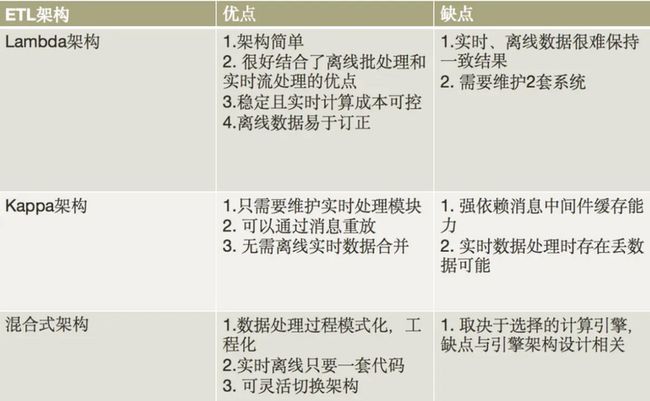
七牛的大数据平台在搭建过程中也经历了上面几个架构的变迁,也就是从最早的Lambda架构,到尝试使用Kappa架构,再到后面的新型混合ETL架构,为了满足业务需求,开发人员在这几个架构中进行折中选择,但是我们发现上面几个架构对于大数据的开发人员要求较高,主要体现在下面几个方面:
- 涉及到众多的框架,如流处理框架就有早期的Apache Storm,到后面的Apache Spark Streaming,再到Apache Flink,学习门槛较高
- 不同计算框架对与数据源的定义不统一,造成输入输出较难管理
- 数据开发人员新开发一个业务指标,不同开发人员写出的代码风格不统一,开发效率低,很难进行工程化,后期维护也必将困难
为了解决上面的几个问题,团队选择基于Apache Spark开发了QStreaming这套简单轻量级ETL开发框架
QStreaming特性
数据源支持
- Apache Kafka
- Apache Hbase
- Hadoop HDFS/S3
- Jdbc
- MongoDB
- Apache Hudi
主要特性
- DDL定义输入源
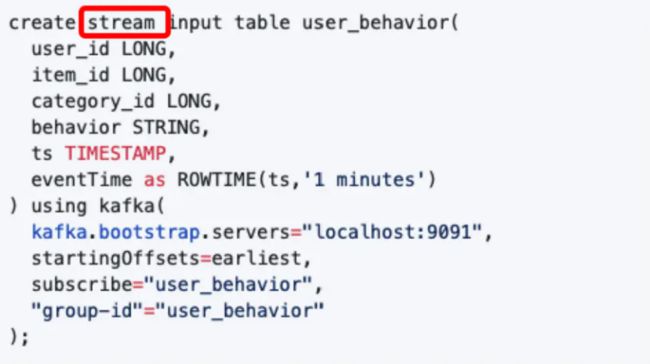
这里面stream关键字代表定义了一个流表,并且是连接到kafka消息中间件
- 流处理watermark的DSL支持
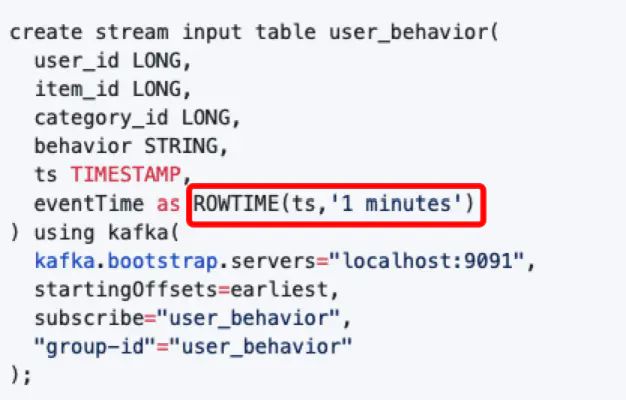
在DSL中添加watermark,主要有2种方式:
- 在DDL中指定,
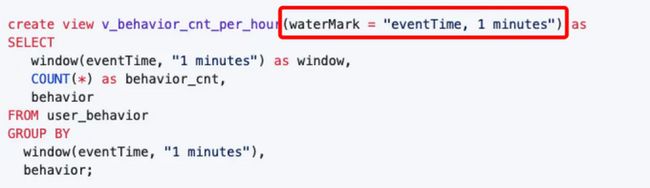
- 在create view 语句中指定
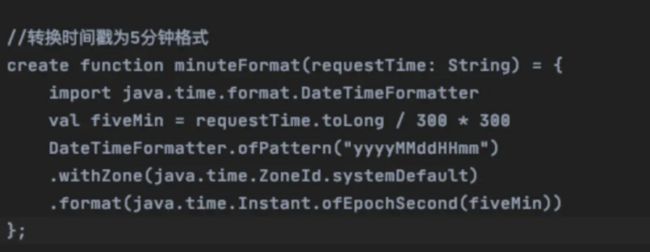
- 动态UDF
比如下面这个转换一个日期字符串为时间戳格式
- 流处理的多输出

这个特性主要是通过spark structed streaming的forEachBatch实现的
- 变量渲染
变量渲染经常在一些定时调度批处理中非常有用,如下根据小时读取一个HDFS上的parquet文件

- 监控,如kafka lag监控
由于Apache spark消费kafka是使用的低阶API,默认我们没有办法知道消费的topic有没有延迟, 我们通过指定group-id属性,模拟kafka consumer的subscribe模式,这样就和普通的kafka consumer 高级API一样了
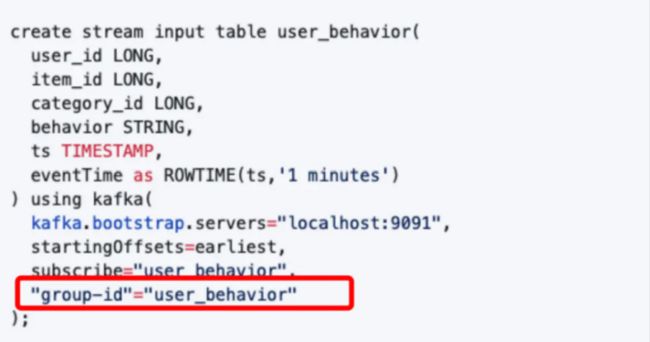
- 数据质量
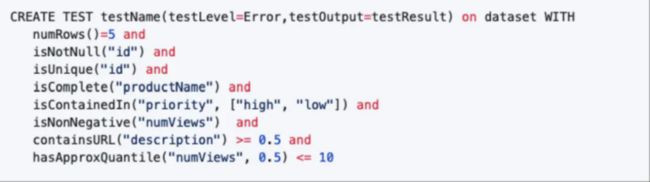
这个特性主要是用来对数据做单元测试的,比如校验我们ETL结果表的准确性
QStreaming完整的语法特性参考这里
QStreaming架构
架构图
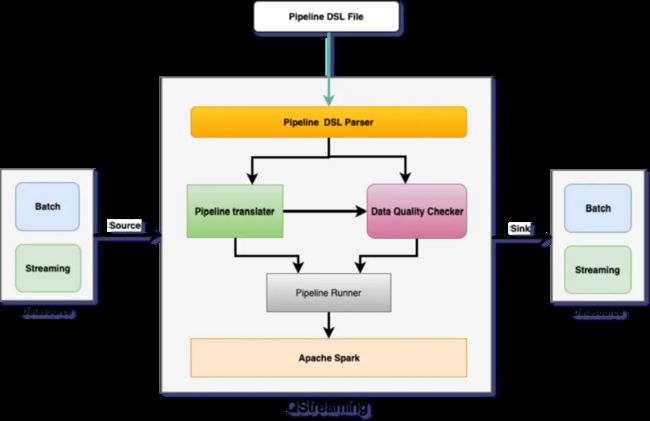
核心组件
从上面的架构图中可以看出QStreaming主要有以下几个组件组成
- Pipeline DSL
Pipeline DSL是一个定义时的Job任务描述文件,类似于SQL语法,对Spark SQL完全兼容,比如下面这个

- Pipeline DSL Parser
Pipeline DSL Parser组件负责解析Pipeline DSL并且转换ANTLR AST为Pipeline Domain Models
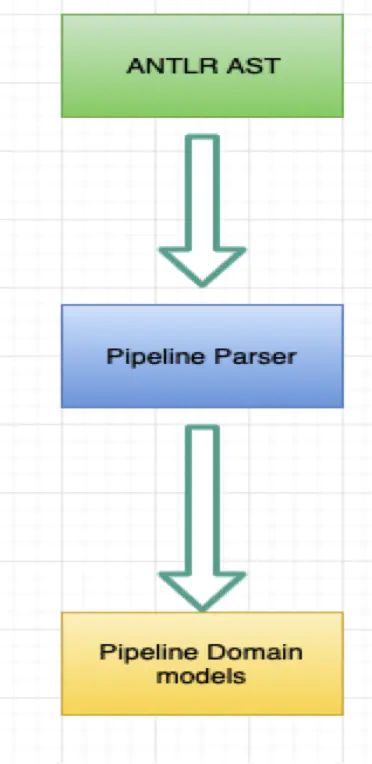
Pipeline Domain models
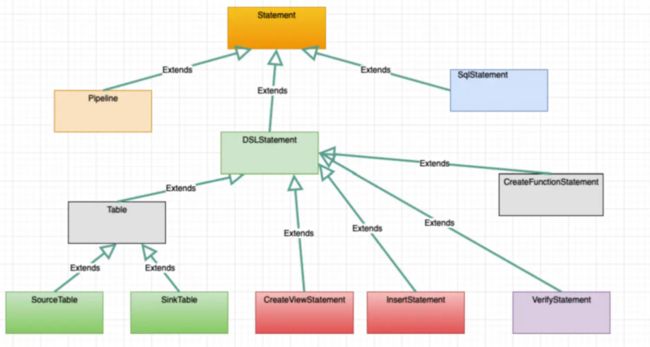
- Pipleine Translator
Pipeline Translator进一步将Pipeline domain model转换为spark transformations和actions

- Data Quality Checker
Data Quality Check负责解析单元测试语句,使用Amazon Deequ库并且翻译为Deequ的VerificationSuite

- Pipeline Runner
这个组件负责构建Pipeline启动上下文,协同PipelineParser和Pipeline Translator一起工作,根据配置启动流或者批处理Application
QStreaming使用场景
- 场景一
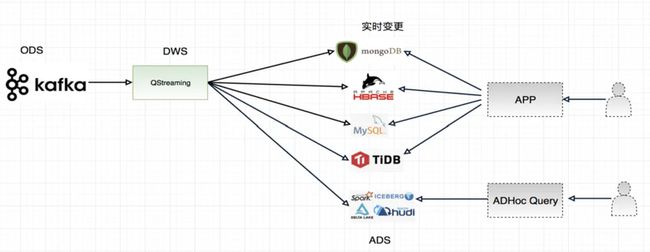
在这一个场景中,QStreaming主要通过消费kafka,然后进行预聚合,预聚合可以进行开窗口计算,比如1分钟的窗口,然后在把窗口聚合的结果写入下游数据存储中,这里面很重要的一个特性就是数据订正功能,所以可以选择的ETL架构如下:
- lambda架构
- kappa架构
- 混合架构
- 场景二
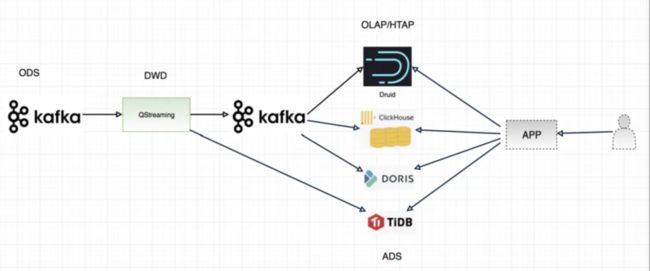
在这个场景中,QStreaming扮演了一层很薄的角色,比如对数据进行加工,但是不对数据进行聚合,保留了明显,预聚合的功能交给了下游支持OLAP引擎,比如支持RollUp功能的Apache Druid,Apache Doris,Clickhouse等,另外Apache Doris还可以保留明细功能
- 场景三
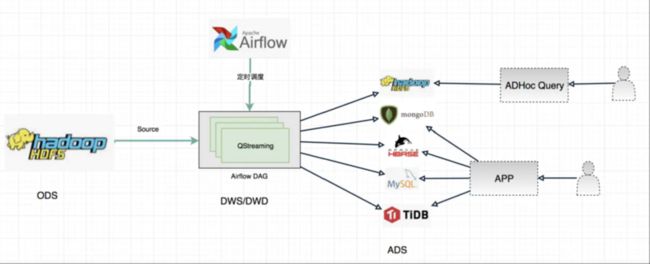
在这个场景中,QStreaming主要是通过Apache Airflow进行调度的,ODS对接Apache Hive数据仓库,然后可以做DWS或者是DWD操作,再把结果写入Hive数据仓库中,提供离线即席查询,或者是聚合的结果写入RDS,NOSQL等数据库,上层对其结果封装为API,供用户使用
- 场景四
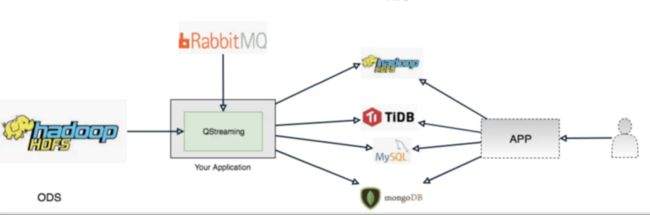
这个场景主要是消息驱动的,通过上游业务方发送消息到消息中间件,然后消费消息驱动QStreaming ETL任务
QStreaming总结
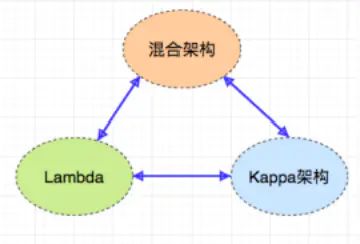
整体上QStreaming可以从下面3个图简单概况:
- 架构层面
可用于下面三种架构中,灵活切换
- 开发层面

- 运维层面

QStreaming RoadMap
QStreaming还非常年轻,后期还会有进一步的规划,规划的特性如下:
完善数据源支持(如Delta lake,Apache Hudi等)
添加数据血缘功能
机器学习Pipeline