MySQL 数据库集群-PXC 方案(二)
集群状态信息
PXC 集群信息可以分为队列信息、复制信息、流控信息、事务信息、状态信息。这些信息可以通过 SQL 查询到。每种信息的详细意义可以在官网查看。
show status like '%wsrep%';复制信息

举例说明几个重要的信息:
| 状态 | 描述 |
|---|---|
| wsrep_replicated | 被其他节点复制的次数 |
| wsrep_replicated_bytes | 被其他节点复制的数据次数 |
| wsrep_received | 从其他节点处收到的写入请求总数 |
| wsrep_received_bytes | 从其他节点处收到的写入数据总数 |
| wsrep_last_applied | 同步应用次数 |
| wsrep_last_committed | 事务提交次数 |
队列信息
队列是一种很好的缓存机制,如果 PXC 正在满负荷工作,没有线程去执行数据的同步,同步请求会缓存到队列中,然后空闲线程从队列中取出任务,执行同步的请求,有了队列 PXC 就能用少量的线程应对瞬时大量的同步请求。

| 状态 | 描述 |
|---|---|
| wsrep_local_send_queue | 发送队列的长度(瞬时同步的请求数量) |
| wsrep_local_send_queue_max | 发送队列的最大长度 |
| wsrep_local_send_queue_min | 发送队列的最小长度 |
| wsrep_local_send_queue_avg | 发送队列的平均长度 |
| wsrep_local_recv_queue | 接收队列的长度 |
| wsrep_local_recv_queue_max | 接收队列的最大长度 |
| wsrep_local_recv_queue_min | 接收队列的最小长度 |
| wsrep_local_recv_queue_avg | 接收队列的平均长度 |
当发送队列的平均长度(wsrep_local_send_queue_avg)值很大,发送队列的长度(wsrep_local_send_queue)也很大的时候,说明 PXC 集群同步数据的速度已经很慢了,队列里边积压了大量的同步请求,这个时候就要检查一下网速是不是正常,或者同步的线程数量是不是太少。
当接收队列的平均长度(wsrep_local_recv_queue_avg)值很大,接收队列的长度(wsrep_local_recv_queue)也很大的时候,这说明本地没有足够的线程去执行持久化的操作,增加线程就可以解决这个问题。
流量控制信息
流量控制就是 PXC 集群在同步速度较慢的情况下,为了避免同步速度跟不上写入速度而推出的一种限速机制,就是限制数据的写入,直到同步队列的长度变小,同步速度变快为止,才会解除流量控制。流量控制的后果很严重,而且一个很小的操作就会引发流量控制。

| 状态 | 说明 |
|---|---|
| wsrep_flow_control_paused_ns | 流控暂停状态下花费的总时间(纳秒) |
| wsrep_flow_control_paused | 流量控制暂停时间的占比(0~1) |
| wsrep_flow_control_sent | 发送的流控暂停事件的数量 |
| wsrep_flow_control_recv | 接收的流控暂停事件的数量 |
| wsrep_flow_control_interval | 流量控制的下限和上限。上限是队列中允许的最大请求数。如果队列达到上限,则拒绝新的请求。当处理现有请求时,队列会减少,一旦到达下限,将再次允许新的请求 |
| wsrep_flow_control_status | 流量控制状态 OFF:关闭 0N: 开启 |
流控的主要原因节点之间同步的速度慢,队列积压了大量的请求,这才是流控的主要原因。
流控解决办法:
- 改善网速,提高带宽,更换交换机,千兆网卡更换成万兆网卡
- 增加线程,线程多了执行的速度也就快了。队列里边就不会积压大量的请求
- 提升硬件性能,比如升级 CPU,内存以及更换光纤硬盘等等都可以提高写入速度
第一项和第三项属于更换硬件的方法,主要说一下第二个方法增加线程数提升同步速度。在 PXC 的配置文件加上wsrep_slave_threads参数。代表的是本地执行队列的线程数量,一般这个数是 CPU 线程数的 1-1.5 倍。比如服务器 CPU 是 8 核 16 线程的,这里就可以写 16-24 就可以。
wsrep_slave_threads=16节点与集群的状态信息

| 状态 | 说明 |
|---|---|
| wsrep_local_state_comment | 节点状态 |
| wsrep_cluster_status | 集群状态(Primary:正常状态、Non-Primary:出现了脑裂请求、Disconnected:不能提供服务,出现宕机) |
| wsrep_connected | 节点是否连接到集群 |
| wsrep_ready | 集群是否正常工作 |
| wsrep_cluster_size | 节点数量 |
| wsrep_desync_count | 延时节点数量 |
| wsrep_incoming_addresses | 集群节点 IP 地址 |
事务相关信息
| 状态 | 说明 |
|---|---|
| wsrep_cert_deps_distance | 事务执行并发数 |
| wsrep_apply_oooe | 接收队列中事务的占比 |
| wsrep_apply_oool | 接收队列中事务乱序执行的频率 |
| wsrep_apply_window | 接收队列中事务的平均数量 |
| wsrep_commit_oooe | 发送队列中事务的占比 |
| wsrep_commit_oool | 无任何意义,不存在本地的乱序提交 |
| wsrep_commit_window | 发送队列中事务的平均数量 |
PXC 节点的安全下线操作
节点用什么命令启动,就用对应的关闭命令去关闭。
- 主节点的管理命令(第一个启动的 PXC 节点)
systemctl start [email protected]
systemctl stop [email protected]
systemctl restart [email protected]- 非主节点的管理命令(非第一个启动的 PXC 节点)
service mysql start
service mysql stop
service mysql restart- 如果最后关闭的 PXC 节点是安全退出的,那么下次启动要最先启动这个节点,而且要以主节点启动。
- 如果最后关闭的 PXC 节点不是安全退出的,那么要先修改
/var/lib/mysql/grastate.dat文件,把其中的safe_to_bootstrap属性值设置为 1,再按照主节点启动。
意外下线部分节点
安全下线节点不会让剩下的节点宕机,如果节点意外退出,集群的规模不会缩小,意外退出的节点超过半数,比如三个节点意外退出了 2 个节点,那么剩下的节点就不能够读写了。其他节点按照普通节点启动上线即可恢复 pxc 集群。
意外下线全部节点,不同时退出
如果三个节点都意外退出,那么查看/var/lib/mysql/grastate.dat文件,看看哪个文件的safe_to_bootstarp的值是 1,那么那个节点是最后意外关闭的,再按照safe_to_bootstarp的值启动 pxc 集群。
意外下线全部节点,同时退出
如果三个节点同时意外退出,我们需要修改配置文件,挑选一个节点作为主节点,修改safe_to_bootstarp的值设置为 1,那么这个节点可以以主节点启动。
配置 MyCat 负载均衡
准备工作(一)
我们需要创建两个 PXC 集群,充当两个分片。
上文中已经创建出来了一个分片,参考步骤然后创建出来第二个分片。
最后会有 6 个 centos 虚拟机。
我的第一个如下:
- 主:192.168.3.137
- 从:192.168.3.138
- 从:192.168.3.139
我的第二个如下:
- 主:192.168.3.141
- 从:192.168.3.143
- 从:192.168.3.144
MyCat : 192.168.3.146
准备工作(二)
在 192.168.3.146 Centos 服务器上进行如下操作:
由于 MyCat 是依赖 jdk 的所以我们先安装 jdk 环境。
yum install -y java-1.8.0-openjdk-devel.x86_64配置 JAVA_HOME 环境变量
ls -lrt /etc/alternatives/java
vim /etc/profile
source /etc/profile![]()
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.272.b10-1.el7_9.x86_64/
输入 java -version 如下图就完成配置。

准备工作(三)
下载 mycat
上传 MyCat 压缩包到虚拟机,并解压。
开放防火墙 8066 和 9066 端口:
firewall-cmd --zone=public --add-port=8066/tcp --permanent
firewall-cmd --zone=public --add-port=9066/tcp --permanent
firewall-cmd --reload关闭 SELINUX
vim /etc/selinux/config把 SELINUX 属性值设置成 disabled,之后保存。重启。
reboot修改 MyCat 的 bin 目录中所有.sh 文件的权限:
chmod -R 777 ./*.shMyCat 启动与关闭
启动MyCat:
./mycat start
查看启动状态:
./mycat status
停止:
./mycat stop
重启:
./mycat restart准备工作(四)
修改配置文件:
修改 server.xml 文件,设置 MyCat 帐户和虚拟逻辑库
0
1
0
0
2
false
0
0
1
64k
1k
0
384m
false
Abc_123456
test
修改 schema.xml 文件,设置数据库连接和虚拟数据表
select user()
select user()
修改 rule.xml 文件,把 mod-long 的 count 值修改成 2
2
重启 MyCat。
测试
在两个分片中都创建 t_user 表:
CREATE TABLE t_user(
id INT UNSIGNED PRIMARY KEY,
username VARCHAR(200) NOT NULL,
password VARCHAR(2000) NOT NULL,
tel CHAR(11) NOT NULL,
locked TINYINT(1) UNSIGNED NOT NULL DEFAULT 0,
INDEX idx_username(username) USING BTREE,
UNIQUE INDEX unq_username(username) USING BTREE
);远程连接 mycat。
向 t_user 表写入数据,感受数据的切分。
USE test;
select * from t_user;
#第一条记录被切分到第二个分片
INSERT INTO t_user(id,username,password,tel,locked) VALUES(1,"Jack",HEX(AES_ENCRYPT('123456','HelloWorld')),'1333222111',false);
#第二条记录被切分到第一个分片
INSERT INTO t_user(id,username,password,tel,locked) VALUES(2,"Rose",HEX(AES_ENCRYPT('123456','HelloWorld')),'1335555111',false);可以查看对应的库中都是没有问题的。


数据切分
| 切分算法 | 适用场合 | 备注 |
|---|---|---|
| 主键求模切分 | 数据增长缓慢,难于增加分片 | 有明确主键值 |
| 枚举值切分 | 归类存储数据,适用于大多数业务 | |
| 主键范围切分 | 数据快速增长,容易增加分片 | 有明确主键值 |
| 日期切分 | 数据快速增长,容易增加分片 |
主键求模切分
上面的示例中,使用的就是主键求模切分,其特点如下:
- 主键求模切分适合用在初始数据很大,但是数据增长不快的场景。例如,地图产品、行政数据、企业数据等。
- 主键求模切分的弊端在于扩展新分片难度大,迁移的数据太多。
- 如果需要扩展分片数量,建议扩展后的分片数量是原有分片的 2n 倍。例如,原本是两个分片,扩展后是四个分片。
主键范围切分
- 主键范围切分适合用在数据快速增长的场景。
- 容易增加分片,需要有明确的主键列。
日期切分
- 日期切分适合用在数据快速增长的场景。
- 容易增加分片,需要有明确的日期列。
枚举值切分
- 枚举值切分适合用在归类存储数据的场景,适合大多数业务。
- 枚举值切分按照某个字段的值(数字)与
mapFile配置的映射关系来切分数据。 - 枚举值切分的弊端在于分片存储的数据不够均匀。
在rule.xml中增加配置如下:
sharding_id
customer-hash-int
customer-hash-int.txt
在conf目录下创建customer-hash-int.txt文件,定义区号与分片索引的对应关系:0 代表第一个分片,1 代表第二个分片。
101=0
102=0
103=0
104=1
105=1
106=1配置schema.xml,增加一个逻辑表,并将其分片规则设置为sharding-customer:
进入 MyCat 中执行热加载语句,该语句的作用可以使 Mycat 不用重启就能应用新的配置:
reload @@config_all;在两个分片中分别执行如下建表语句:
USE test;
CREATE TABLE t_customer(
id INT UNSIGNED PRIMARY KEY,
username VARCHAR(200) NOT NULL,
sharding_id INT NOT NULL
);之后我们在 MyCat 中进行查询看看:
也是 ok 的。
接着我们增加一条数据:
insert into t_customer(id,username,sharding_id) values (1,'Michelle',101);
insert into t_customer(id,username,sharding_id) values (2,'Jack',102);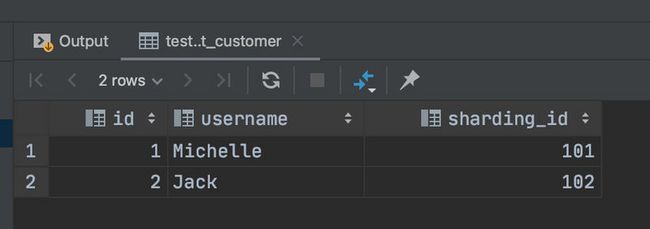
查看第一个分片可以看到数据已经切分过来了
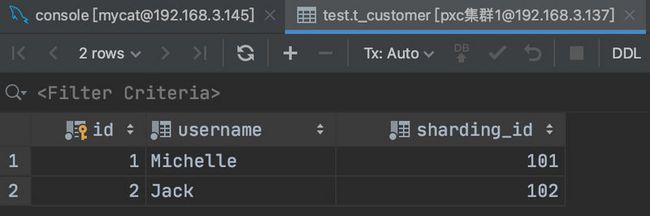
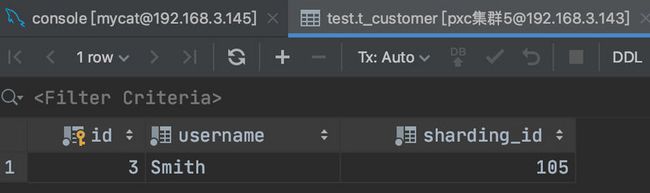
如果我们再增加一条 SQL:
insert into t_customer(id,username,sharding_id) values (3,'Smith',105);很显然,数据被分到了第二个分片中。
父子表
当有关联的数据存储在不同的分片时,就会遇到表连接的问题,在 MyCat 中是不允许跨分片做表连接查询的。为了解决跨分片表连接的问题,MyCat 提出了父子表这种解决方案。
父子表规定父表可以有任意的切分算法,但与之关联的子表不允许有切分算法,即子表的数据总是与父表的数据存储在一个分片中。父表不管使用什么切分算法,子表总是跟随着父表存储。
例如,用户表与订单表是有关联关系的,我们可以将用户表作为父表,订单表作为子表。当 A 用户被存储至分片 1 中,那么 A 用户产生的订单数据也会跟随着存储在分片 1 中,这样在查询 A 用户的订单数据时就不需要跨分片了。如下图所示:

配置父子表
在t_customer中增加 childTable。需要注意的是一个 table 可以有多个 childTable。
进入 MyCat 中执行热加载语句,该语句的作用可以使 Mycat 不用重启就能应用新的配置:
reload @@config_all;在两个分片中执行建表 SQL:
USE test;
CREATE TABLE t_orders(
id INT UNSIGNED PRIMARY KEY,
customer_id INT NOT NULL,
datetime TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);执行成功后,我们插入些数据测试:
USE test;
insert into t_orders(id,customer_id) values (1,1);
insert into t_orders(id,customer_id) values (2,1);
insert into t_orders(id,customer_id) values (3,1);
insert into t_orders(id,customer_id) values (4,2);
insert into t_orders(id,customer_id) values (5,3);我们在第一个分片中增加了两个用户 id 为 1 、2 的,在第二个分片中增加了一个用户 id 为 3 的。
所以第一个分片会有 4 条记录,而第二个分片中有一条。
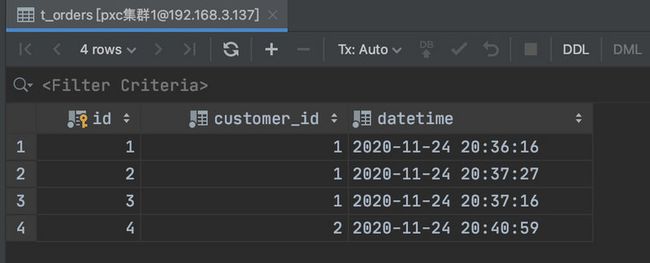
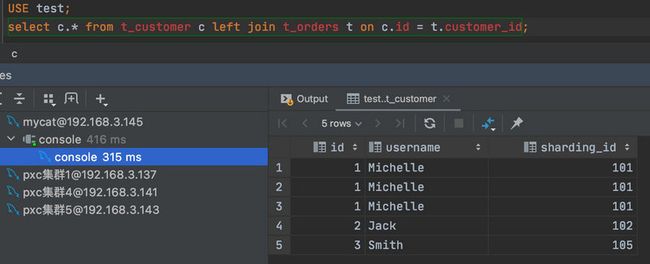
由于父子表的数据都是存储在同一个分片,所以在 MyCat 上进行关联查询也是没有问题的:
组建双机热备的高可用 MyCat 集群
在之前的示例中,我们可以看到对后端数据库集群的读写操作都是在 MyCat 上进行的。MyCat 作为一个负责接收客户端请求,并将请求转发到后端数据库集群的中间件,不可避免的需要具备高可用性。否则,如果 MyCat 出现单点故障,那么整个数据库集群也就无法使用了,这对整个系统的影响是十分巨大的。
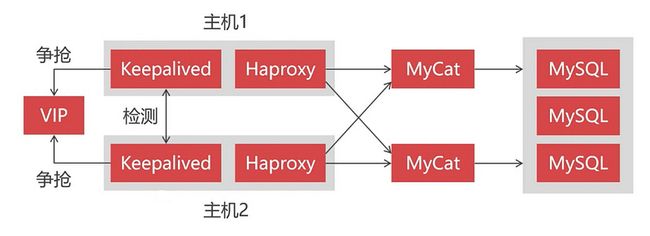
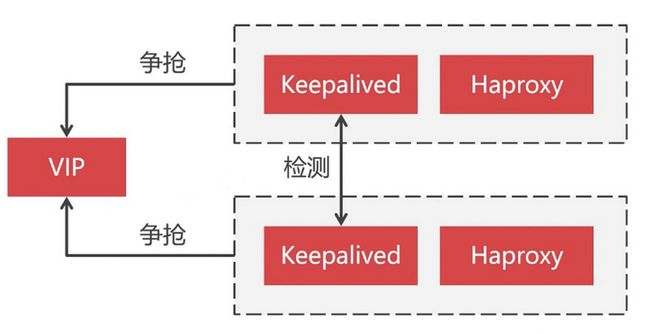
所以我们现在将要演示如何去构建一个高可用的 MyCat 集群,为了搭建 MyCat 高可用集群,除了要有两个以上的 MyCat 节点外,还需要引入 Haproxy 和 Keepalived 组件。
其中 Haproxy 作为负载均衡组件,位于最前端接收客户端的请求并将请求分发到各个 MyCat 节点上,用于保证 MyCat 的高可用。而 Keepalived 则用于实现双机热备,因为 Haproxy 也需要高可用,当一个 Haproxy 宕机时,另一个备用的 Haproxy 能够马上接替。也就说同一时间下只会有一个 Haproxy 在运行,另一个 Haproxy 作为备用处于等待状态。当正在运行中的 Haproxy 因意外宕机时,Keepalived 能够马上将备用的 Haproxy 切换到运行状态。
Keepalived 是让主机之间争抢同一个虚拟 IP(VIP)来实现高可用的,这些主机分为 Master 和 Backup 两种角色,并且 Master 只有一个,而 Backup 可以有多个。最开始 Master 先获取到 VIP 处于运行状态,当 Master 宕机后,Backup 检测不到 Master 的情况下就会自动获取到这个 VIP,此时发送到该 VIP 的请求就会被 Backup 接收到。这样 Backup 就能无缝接替 Master 的工作,以实现高可用。
引入这些组件后,最终我们的集群架构将演变成这样子:
Haproxy包括以下一些特征:
- 根据静态分配的cookie分配HTTP请求。
- 分配负载到各个服务器,同时保证服务器通过使用HTTP Cookie实现连接保持。
- 当主服务器宕机时切换到备服务器,允许特殊端口的服务监控。
- 做维护时通过配置可以保证业务的连续性,更加人性化。
- 添加修改删除HTTP Request和Respone头。
- 通过特定表达式Block HTTP请求。
- 根据应用的cookie做连接保持。
- 常有用户验证的详细的HTML监控报告。
Haproxy的负载均衡算法现在具体有如下8种:
- roundrobin:简单的轮询。
- static-rr:权重轮询。
- leastconn:最少连接者优先。
- source:根据请求源IP,这个跟Nginx的ip_hash机制类似。
- ri:根据请求的URI。
- rl_param:表示根据请求的URI参数。
- hdr(name):根据HTTP请求头来锁定每一次HTTP请求。
- rdp-cookie(name):根据cookie来锁定并哈希每一次TCP请求。
这里就不再演示如何搭建第二台 Mycat 环境了。
这里再说一下目前我的集群:
第一个 PXC 分片:
- 主:192.168.3.137
- 从:192.168.3.138
- 从:192.168.3.139
第二个 PXC 分片:
- 主:192.168.3.141
- 从:192.168.3.143
- 从:192.168.3.144
第一台 MyCat : 192.168.3.146
第二台 MyCat: 192.168.3.147
安装 Haproxy
由于我电脑只有 8G 内存,有点吃不消所以我的 Haproxy 都在 Mycat 服务器上。
开放防火墙 3306 和 4001 端口:
| 端口 | 作用 |
|---|---|
| 3306 | TCP/IP 转发端口 |
| 4001 | 监控界面端口 |
firewall-cmd --zone=public --add-port=3306/tcp --permanent
firewall-cmd --zone=public --add-port=4001/tcp --permanent
firewall-cmd --reload关闭 SELINUX
vim /etc/selinux/config把 SELINUX 属性值设置成 disabled,之后保存。重启。
reboot接着我们安装 haproxy
yum install -y haproxy安装完成后我们修改对应的配置文件
vim /etc/haproxy/haproxy.cfg记得修改为自己的 MyCat 的 IP。
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
listen admin_stats
# 绑定的ip及监听的端口
bind 0.0.0.0:4001
# 访问协议
mode http
# URI 相对地址
stats uri /dbs
# 统计报告格式
stats realm Global\ statistics
# 用于登录监控界面的账户密码
stats auth admin:abc123456
listen proxy-mysql
# 绑定的ip及监听的端口
bind 0.0.0.0:3306
# 访问协议
mode tcp
# 负载均衡算法
balance roundrobin
#日志格式
option tcplog
# 需要被负载均衡的主机
server mycat_1 192.168.3.146:8066 check port 8066 weight 1 maxconn 2000
server mycat_2 192.168.3.147:8066 check port 8066 weight 1 maxconn 2000
#使用keepalive检测死链
option tcpka配置完成之后我们进行启动
service haproxy start我们在浏览器输入 IP 测试:
http://192.168.3.146:4001/dbs输入我们配置的账号密码后就可以看到如下图:

Haproxy 的监控界面提供的监控信息也比较全面,在该界面下,我们可以看到每个主机的连接信息及其自身状态。当主机无法连接时,Status一栏会显示DOWN,并且背景色也会变为红色。正常状态下的值则为UP,背景色为绿色。
另一个 Haproxy 节点也是使用以上的步骤进行安装和配置,这里就不再重复了。
测试 Haproxy
我们远程连接一下试试:
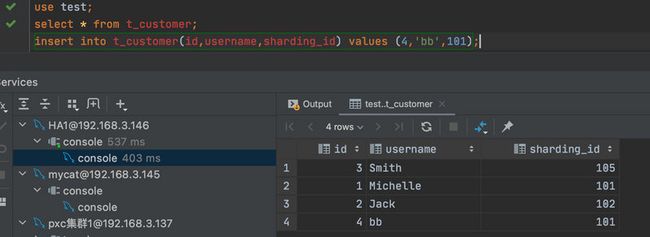
可以发现新增都是没有问题的。
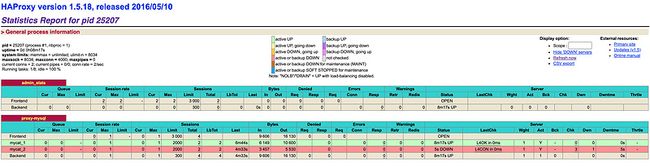
我们搭建 Haproxy 是为了让 MyCat 具备高可用的,所以最后测试一下 MyCat 是否已具备有高可用性,我们将 147 的 MyCat 停掉。
此时,从 Haproxy 的监控界面中,可以看到mycat_2这个节点已经处于下线状态了:
接着我们再去增加一条数据试试。
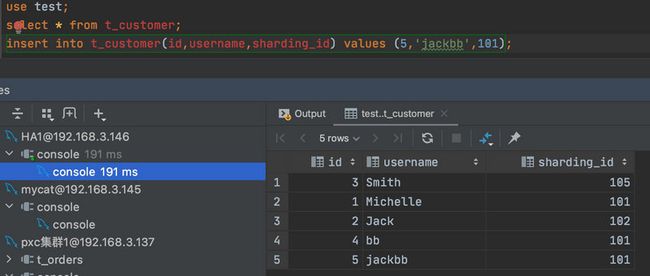
从测试结果可以看到,插入和查询语句依旧是能正常执行的。也就是说即便此时关掉一个 MyCat 节点整个数据库集群还能够正常使用,说明现在 MyCat 集群是具有高可用性了。
利用 Keepalived 实现 Haproxy 的高可用
实现了 MyCat 集群的高可用之后,我们还得实现 Haproxy 的高可用,因为现在的架构已经从最开始的 MyCat 面向客户端变为了 Haproxy 面向客户端。
而同一时间只需要存在一个可用的 Haproxy,否则客户端就不知道该连哪个 Haproxy 了。这也是为什么要采用 VIP 的原因,这种机制能让多个节点互相接替时依旧使用同一个 IP,客户端至始至终只需要连接这个 VIP。所以实现 Haproxy 的高可用就要轮到 Keepalived 出场了。
先开启防火墙的 VRRP 协议:
#开启VRRP
firewall-cmd --direct --permanent --add-rule ipv4 filter INPUT 0 --protocol vrrp -j ACCEPT
#应用设置
firewall-cmd --reload安装 Keepalived
yum install -y keepalived编辑配置文件
vim /etc/keepalived/keepalived.confvrrp_instance VI_1 {
state MASTER
interface enp0s3
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 123456
}
virtual_ipaddress {
192.168.3.177
}
}配置说明:
state MASTER:定义节点角色为 master,当角色为 master 时,该节点无需争抢就能获取到 VIP。集群内允许有多个 master,当存在多个 master 时,master 之间就需要争抢 VIP。为其他角色时,只有 master 下线才能获取到 VIPinterface ens32:定义可用于外部通信的网卡名称,网卡名称可以通过ip addr命令查看virtual_router_id 51:定义虚拟路由的 id,取值在 0-255,每个节点的值需要唯一,也就是不能配置成一样的priority 100:定义权重,权重越高就越优先获取到 VIPadvert_int 1:定义检测间隔时间为 1 秒authentication:定义心跳检查时所使用的认证信息auth_type PASS:定义认证类型为密码auth_pass 123456:定义具体的密码
virtual_ipaddress:定义虚拟 IP(VIP),需要为同一网段下的 IP,并且每个节点需要一致
完成以上配置后,启动 keepalived 服务:
service keepalived start我们 ping 一下我们的虚拟地址试试,也是 OK 的!

另外一台步骤一模一样,这里就不演示了!
测试 Keepalived
以上我们完成了 Keepalived 的安装与配置,最后我们来测试 Haproxy 是否已具有高可用性。

连接成功后,执行一些语句测试能否正常插入、查询数据:

最后测试一下 Haproxy 的高可用性,将其中一个 Haproxy 节点上的 keepalived 服务给关掉。
service keepalived stop然后再次执行执行一些语句测试能否正常插入、查询数据,如下能正常执行代表 Haproxy 节点已具有高可用性:

大功告成!