
前言
最近朋友小王正在找工作,然后有一个面试官问他知不知道 “查询sql具体的执行流程” 。小王说不知道呀,然后面试官直接对小王说:小伙子 耗子尾汁(好自为之) ,怎么连这么简单的都不知道呢?
小王听后脱口而出:哼!面试官你 不讲武德 ,不按套路出牌呀,你应该问问索引相关的知识呀,这个我倍清楚。

在听完小王描述后,自己也在脑海中搜了搜这个知识点,可怜的是我的知识库里也没找到相关内容,然后就去面壁思过了,随后本文就诞生了。
注意 :本文主要以 MySql 为例;说到了MySql了,然后再唠叨下现在使用十分普遍的MySql的姊妹数据库 MariaDB 。
MariaDB 是个什么东东呢?
MySql被Oracle收购后,MySql的创始人担心MySql数据库发展的未来(开发缓慢、封闭、可能会被闭源),于是创建了一个分支MariaDB,默认使用全新的Maria存储引擎,它是原来Mysql中的 MyISAM 存储引擎的升级版。
本文主线:
①、MySql的整体架构描述;
②、Server层各节点描述;
③、InnoDB存储引擎描述;
MySql架构描述
咱啥也先不说,先贴上一张摘抄自网上的大图:

上面这张图描述的清不清晰呢?不清晰,那别着急,咱再贴一张:
Server服务层描述:
通过上面的架构图可以得知,Server层中主要由 连接器、查询缓存、解析器/分析器、优化器、执行器 几部分组成的,下面将主要描述下这几部分。
连接器
客户端想要对数据库进行操作时,前提是与数据库建立好连接;而连接器就是用来负责跟客户端建立连接、获取权限、维持和管理连接的。
连接方式:
MySQL既支持短连接,也支持长连接。短连接就是操作完毕后,马上close关掉。
长连接可以保持打开,减少服务端创建和释放连接的消耗,后面的程序访问的时候还可以使用这个连接。 一般我们会在连接池中使用长连接。
长连接使用时的注意事项:
客户端与服务器建立长连接,默认有效时间是 8小时 ,超过8小时MySql服务器就会将连接断开了,那么客户端再次请求的话,就会报 连接已断开的问题 ;
并且保持长连接会消耗内存。长时间不活动的连接,MySQL服务器会断开。那这个8小时的超时时间怎么查看呢?
-- 非交互式超时时间,如 JDBC 程序
show global variables like 'wait_timeout';
-- 交互式超时时间,如数据库工具
show global variables like' interactive_timeout';
复制代码执行后得到下图结果:默认都是28800秒,8小时 。
一般项目中使用的连接池中的连接都是长连接的;(例如:druid、c3p0、dbcp等)
举个例子,说明下长连接超时断开导致的实际问题:
某个朋友的公司有个管理系统,这个系统使用的时Mysql,但是他最近遇到了一个问题:就是系统明明前天是好用的,但是第二天去到公司后就打不开了,只要将系统重启就好了,一时间不知道什么原因,什么鬼嘛,苦恼?
最后通过查看日志才发现是连接池中的连接都断开了,因为从前天到第二天上班这之间隔得时间超过了8小时了。 唉,这么个小知识点导致好几天的困惑,实在不该呀,还是知识掌握的不全面呀。
好了,现在也找到问题原因了,但是它该怎么解决呢?
长连接超时断开的解决方案:
①、定期断开长连接。使用一段时间,或者程序里面判断执行过一个占用内存的大查询后,断开连接,之后要查询再重连。
②、如果你用的是 MySQL 5.7 或更新版本,可以在每次执行一个比较大的操作后,通过执行 mysql_reset_connection 来重新初始化连接资源。这个过程不需要重连和重新做权限验证,但是会将连接恢复到刚刚创建完时的状态。
查询缓存
MySQL缓存是默认关闭的,也就是说不推荐使用缓存,为什么呢?
MySql为什么默认不开启缓存呢?
主要是由于它的使用场景限制的:
①、先说下缓存中数据存储格式:key(sql语句)-value(数据值);所以如果SQL语句(key)只要存在一点不同之处就会直接进行数据库查询了;
②、由于表中的数据不是一成不变的,大多数是经常变化的,而当数据库中的数据变化了,那么相应的与此表相关的缓存数据就需要移除掉;
需要注意的是, MySQL 8.0 版本直接将查询缓存的整块功能删掉了,也就是说8.0开始彻底没有这个功能了。
分析器
分析器的工作主要是对要执行的SQL语句进行解析,最终得到抽象语法书,然后再使用预处理器判断抽象语法树中的表是否存在,如果存在的话,在接着判断select投影列字段是否在表中存在等。
词法分析
词法分析用于将SQL拆解为不可再分的原子符号,称为Token。并根据不同数据库方言所提供的字典,将其归类为关键字,表达式,字面量和操作符。
语法分析
语法分析就是根据词法分析拆解出来的Token(原子符号)将SQL语句转换为抽象语法树。下面就直接举例说明,看一个SQL它的抽象语法书到底长神魔样:
SQL语句:
SELECT id, name FROM t_user WHERE status = 'ACTIVE' AND age > 18
复制代码然后上面的SQL语句经过词法分析、语法分析后得到的抽象语法书如下:
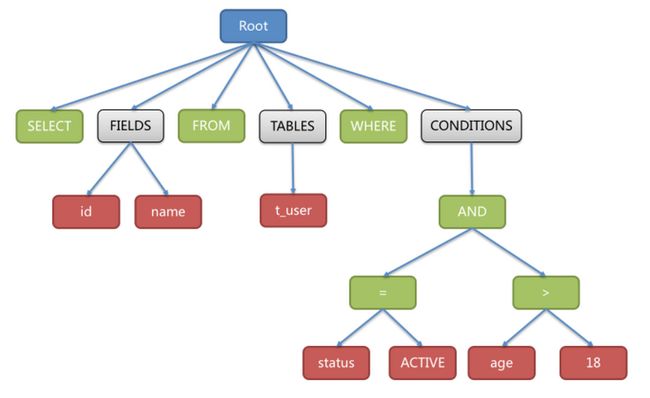
图片摘自:https://shardingsphere.apache...
注意,为了便于理解,抽象语法树中的关键字的Token用绿色表示,变量的Token用红色表示,灰色表示需要进一步拆分。
预处理器
预处理是用来对生成的 抽象语法树 进行语义校验,语义校验就是对查询的表、select投影列字段进行校验,判断表、字段是否存在等;
优化器
优化器的作用: 主要是将SQL经过词法解析/语法解析后得到的语法树,通过MySQL的数据字典和统计信息的内容,经过 一系列运算 ,从而得出一个 执行计划 。
在优化过程中,经过的一系列运算是什么呢?下面简单说下:
①、逻辑变换:例如SQL的where条件中存在 8>9,那逻辑转换就是将语法树中存在的这种常量表达式直接进行化简,化简为 false;除了化简还有常量表达式计算等。
②、代价优化:就是通过付出一些数据统计分析的代价,来得到这个SQL执行是否可以走索引,以及走哪些索引;除此之外,在多表关联查询中,确定最终表join的顺序等;
在分析是否走索引查询时,是通过进行 动态数据采样统计分析出来;只要是统计分析出来的,那就可能会存在分析错误的情况,所以在SQL执行不走索引时,也要考虑到这方面的因素。
MySql执行计划怎么查看呢?
在执行的SQL语句前添加上 explain 关键字即可;
扩展: Oracle怎么查看执行计划? 参考此文章 Oracle通过执行计划查看查询语句是否使用索引
执行器
MySQL 通过分析器知道了你要做什么,通过优化器知道了该怎么做,于是就进入了执行器阶段,开始执行语句。 开始执行的时候,要先判断一下建立连接的对象对这个表有没有执行操作的权限,如果没有,就会返回没有权限的错误;如果有,就按照生成的执行计划进行执行。
通过文章最开始的架构图可知,执行器下面连接的就是存储引擎了,执行器就是通过调用存储引擎提供的API接口进行调用操作数据的。
存储引擎描述
存储引擎是对底层物理数据执行实际操作的组件,为Server服务器层提供各种操作数据的 API。MySQL 支持插件式的存储引擎,包括 InnoDB 、MyISAM、Memory 等。一般情况下,MySQL默认使用的存储引擎是 InnoDB 。
InnoDB 存储引擎支持的功能总览
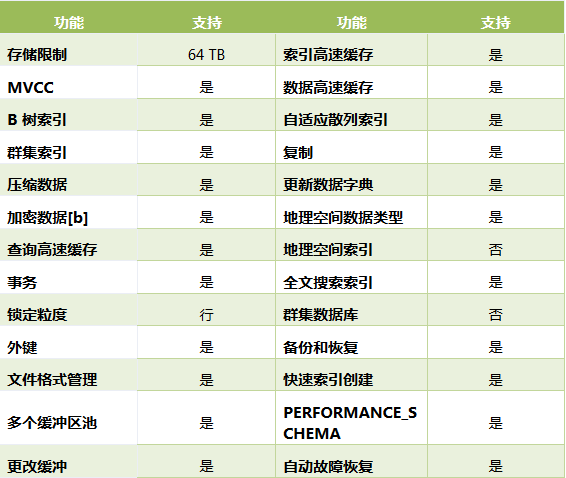
扩展
InnoDB存储引擎深入学习,啥也不说了,先贴上其整体架构图:如下图所示,InnoDB存储引擎整体分为内存架构(Memory Structures)和磁盘架构(Disk Structures)。
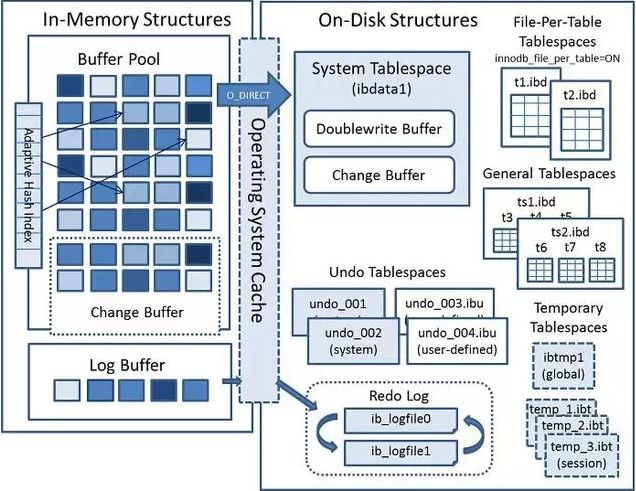
如果想深入学习,请参考此文章 你居然还不知道Mysql存储引擎InnoDB分为内存架构、磁盘架构? 《2020最新Java基础精讲视频教程和学习路线!》