大数据分析之——基于模型的复杂数据多维聚类分析
来自:http://qing.weibo.com/2294942122/
EMC中国研究院大数据实验室senior research scientist 陈弢
(一)引言
随着现实和虚拟世界的数据产生速度越来越迅猛,人们开始关注如何从这些数据中获取信息,知识,以及对于决策的支持。这样的任务通常被称作大数据分析(BigData Analytics)。大数据分析的难点很多,比如,由于海量数据而带来的分析效率瓶颈,使用户不能及时得到分析结果;由于数据源太多而带来的非结构化问题,使传统的数据分析工具不能直接利用。
本文讨论大数据内部关系的复杂性,以及复杂数据所带来的对于聚类分析的挑战。聚类分析的目标是依据数据本身的分布特征(无监督),把整个数据(空间)划分成不同的类。基本的准则是同类的数据应该具有某种的相似性,而异类的数据应该具有某种差异性。现有工作假设在这些数据中存在单一的聚类划分的方法,而聚类目标就是找到这样的一种划分。然而,我们在大数据中所面对的复杂数据是多侧面的,比如在网页数据中既有关于内容的文本属性,也有指向这个网页的链接属性。多侧面数据本身就存在着多种有意义的划分,强制地将数据按照单一的方法聚类,得不到有效的、明确清晰的、可诠释的结果。针对这个问题,多维聚类方法针对数据的不同侧面,得到数据聚类的多种方法,最后让使用者决定需要的聚类划分。
高维复杂数据的聚类分析是本文作者在香港科技大学跟随Nevin Zhang教授攻读博士期间的主要工作。研究论文Model-based multidimensional clustering ofcategorical data发表在今年《ArtificialIntelligence》杂志的第176期。《ArtificialIntelligence》从1970年开始出版,是人工智能领域老牌顶级期刊。因为版权原因,可能网上下载不到免费的全文,感兴趣的同学可以联系[email protected]。关于文中所用的隐树模型的介绍以及免费软件参见隐树模型项目主页。
(二)多维聚类的概念
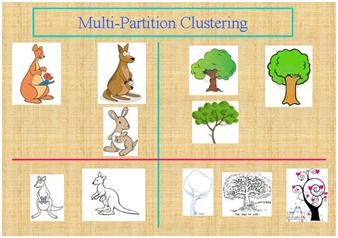
假设我们需要对图中的所有图片进行聚类,可能的聚类方法不止一种:按照图片的内容,我们可以把左边的图片标注成袋鼠,而右边的标注成树;而按照图片风格属性,我们可以把上面的图片称为色彩图,而下面的称为线条图。简而言之,关注数据的不同侧面,有可能得到不同的聚类结果。同时这些聚类结果也都是有意义,可以解释的。
生活中多维聚类的例子很多,比如对于人群的划分,可以按照男女等人口统计学信息划分,也可以按照对于某个事件的看法划分。那么从机器学习的角度如何公式化这样的问题,之后又怎么利用概率统计的方法去解决这样的问题呢?下面我们先给出问题的定义。
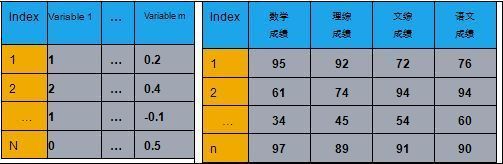
如图所示,在聚类分析这样的无监督学习中,输入是一个数据表。表的每一行表示一个数据点,而每一列表示描述这个点的一维属性。大数据的一个重要特征就是维度很高(包含很多列),从而带来的维度灾难(curseof dimensionality)。在聚类分析中,表现为:这些维度可能自然地分成一些组,每组包含一些属性,反应了数据某一侧面(facet)的特征。用户可以根据其中一个侧面的属性,对这个数据进行聚类。比如在右表的数据中,一个学生的数据包含了数学成绩,理综成绩,文综成绩,和语文成绩这些属性。我们可以关注学生的数学和理综成绩,按照理科成绩(分析能力)对学生进行聚类;同时也可以关注学生的文综和语文成绩,按照文科成绩(语言能力)对学生进行聚类。
所以多维聚类的问题定义为:
如何发现数据中包含的多个侧面,即属性的自然分组,针对这些不同侧面进行聚类,从而得到多种聚类方法。
(三)多维聚类分析的工具和原理
贝叶斯网络是一种表示和处理随机变量之间复杂关系的工具。它是通过在随机变量之间加箭头而得到的有向无圈图。箭头表示直接概率依赖关系,具体依赖情况由条件概率分布所定量刻画。出于对计算复杂度的考虑,人们会对贝叶斯网络进行一些限制,在实际中使用一些特殊的网络结构。隐树模型(latent tree model)是一类特殊的贝叶斯网,也称为多层隐类模型(hierarchical latent class model), 是一种树状贝叶斯网, 其中叶节点代表观察到的变量,也称为显变量,其它节点代表数据中没有观察到的变量,也称为隐变量。
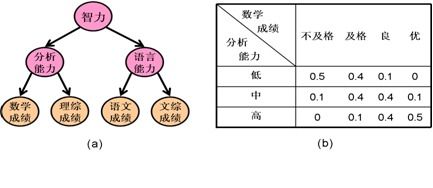
图中给出了隐树模型的一个例子。其中,学生的“数学成绩”、“理综成绩”、“语文成绩”和“文综成绩”是显变量,而“智力”、“分析能力”和“语言能力”则是隐变量。从“分析能力”到“数学成绩”有一个箭头, 表示“数学成绩”直接依赖“分析能力”,具体依赖情况由右图中的条件概率表所定量所刻画。表中的内容是说,分析能力低的学生在数学科有0.5的概率不及格、0.4的概率及格、0.1的概率得良,而得优的概率则是0; 等等。模型中的其它箭头代表其它变量之间直接依赖关系,每个箭头都有相应的条件概率分布。
在隐树模型中,一个隐变量对应一种数据聚类的方法。隐树模型允许模型中有多个隐变量,所以自然地可以多维同时聚类。在例子模型中,可以按照分析能力或者语言能力对学生聚类,也可以按照智力对学生聚类。在隐树模型中,聚类分析可以通过计算给定学生成绩的后验概率进行判断。所以,利用隐树模型进行多维聚类分析的技术重点就在如何通过观测数据学习一个最优的模型。抽象地说,就是找到能够最好地解释数据的一个生成隐树模型(Generative Latent tree model)。
(四)隐树模型的学习
隐树模型的学习是一个对模型逐步优化的过程,优化的目标函数是一个称为贝叶斯信息准则(Bayes information criterion, 简称BIC) 的函数:
BIC(m|D) = max θ log P(D|m, θ) – d(m)logN/2
BIC准则要求模型与数据尽量紧密地拟合,但其复杂不能过高。所以式中第一项表示拟合程度,而第二项是对于模型复杂度的一个惩罚项。我们的优化过程是一个基于搜索的爬山算法(Hill-Climbing)。以只包含一个隐变量的简单的隐树模型作为搜索的起始模型,在搜索的过程中,逐步引入新的隐变量、增加隐变量的取值个数、或者调整变量之间的连接。这是一个逐步修改模型的过程,在这个过程中,模型与数据的拟合程度不断改进,从而BIC分逐步增加。当模型就变得太复杂时,BIC会不升反降,于是搜索过程停止。
隐树模型的学习是一个非常耗时的过程,主要原因在于对于BIC分数的计算。BIC函数的第一项叫做最大似然函数,在模型包含缺失值或者隐变量时,计算最大似然函数需要调用EM(Expectation-Maximization)算法。尽管我们已经对于限制了模型结构为简单的树状结构,但是在这样的模型上进行EM的计算依然是非常困难。围绕隐树模型的很多工作都是在研究如何对模型学习进行加速的,这儿就不赘述了。
(五)基于隐树模型的多维聚类分析实例

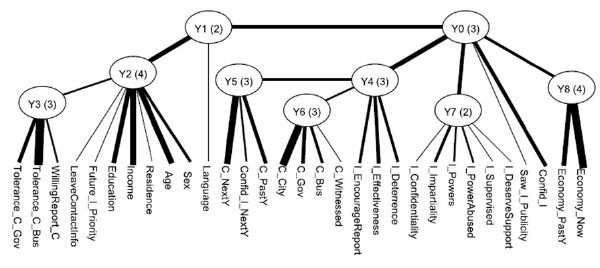
我们以一个真实的数据分析实例来展现多维聚类分析。数据来自某地区的关于贪污的社会调查问卷。通过一些数据预处理,我们的数据(如图所示)包含了1200份的问卷,以及31个问题。比如说C_City表示被访问者对于该地区的贪污普遍性的看法,可以有4个选项,分别是非常普遍,普遍,不普遍,以及非常不普遍。C_Gov和C_Bus分别表示受访者对于该地区政府部门或商业部门的贪污普遍性的看法,同样也有四个选项。Tolerance_C_Gov和Tolerance_C_Bus则分别表示受访者对于该地区的政府部门以及商业部门的贪污的容忍程度,可以选择完全不能容忍,不能容忍,能容忍,完全能容忍。数据表里面的-1表示受访者对该问题的回答缺失。
利用隐树的学习算法,我们从这个数据得到了一个如图所示的模型。叶节点对应问卷问题,即显变量。中间结点,Y0-Y8是从数据中发现的隐变量,括号里面的数字表示这个变量所取的状态个数。我们发现这些隐变量都有一定的意义,比如,Y2和问卷中的Sex,Age,Income,Education这些问题紧密连接,说明Y2应该是表示受访人的人口统计信息。Y3和问卷中的Tolerance_C_Gov和Tolerance_C_Bus紧密联系,说明Y3是反映受访者总体对于贪污的看法。
模型中的每个隐变量表示数据聚类的一种方式。比如,变量Y2有4个值,说明Y2提示数据可以分成四个类。这种聚类主要基于Sex,Age,Income,Education这些人口统计信息相关变量的,所以可以说当我们关注人群的人口统计信息这个侧面时,我们可以根据Y2把人群分成四类。具体地研究这四类的类条件概率(Class-Conditional ProbabilityDistribution)特性,我们进一步发现它们分别代表:低收入的年轻人群,低收入的女性人群,受过高等教育的高收入人群,以及只接受初等教育的一般收入人群。同时,我们看到Y3有3个取值,这说明从人群对于贪污总体看法这个侧面出发,可以把人群分成三类,分别是对于贪污完全不能容忍的人群,对于贪污比较不能容忍的人群,对于贪污可以容忍的人群。同样地,我们的聚类也可以基于其他隐变量所代表的侧面。这样从模型中我们得到了9种聚类的方法,达到了多维同时聚类的效果。
除了聚类,对于这个数据的分析还告诉我们一些隐藏很深的关系。比如在模型中变量Y2和Y3有连线,这表明一个人的背景信息和他对于贪污的容忍程度应该有一定的关联关系。具体地说,在Y2所表示的4类人中,你觉得哪一类是最能容忍贪污,而哪一类是最不能容忍贪污的呢?在模型中,通过对这两个变量的条件概率的分析,我们得到了一个答案,有兴趣的同学可以去论文中验证一下自己的猜测。
(六)相关学术工作
隐树模型在密度估计,近似推理及隐结构发现等方面都有具体的应用。在多维聚类分析的应用上,我们分析过市场学数据(COILChallenge 2000),某地区的社会调查数据(ICAC),NBA篮球运动员比赛统计数据。最近,随着算法的提速,隐树模型开始被尝试用于文本分析,比如对于网页数据,博客数据等的话题分析。隐树模型最开始的提出是为了对中医的证候分析提供统计解释,有兴趣的同学可以参考隐结构模型与中医证研究。
最近两年,多维聚类分析引起了很多机器学习研究人员的兴趣。从2010年开始的MultiClust Workshop已经举办了两届,其中第一届是和KDD2010一起举办,第二届是和ECML/PKDD2011一起举办。而第三届也会与SDM2012一起举办。具体参考文献这儿也不罗列了。
多维聚类分析和基于多视图的学习不应该混淆。多视图学习假设数据的多个视图已知,要求视图之间存在充分性(Sufficiency)和冗余性(Redundancy),通过协同训练等技术,主要提高半监督学习,主动学习的性能。多视图学习中针对聚类这样的无监督任务的研究很少,而且它的目标也是如何提高单一的聚类划分的质量,而不是找到多种划分方法。多视图学习也极少涉及如何发现多个视图,而不是假设他们已知。这方面南京大学周志华教授在今年的中国机器学习及其应用研讨会上提到一些初步研究。实际中,可以考虑先用多维聚类分析找到数据的多个侧面(视图),然后再应用多视图学习的方法。
(七)总结
对于一个复杂数据,比如文本,视频,图像,或者生物实验数据,人们可以从不同的角度去诠释这样的数据。数据分析家们已经有了这样的共识,那就是以前的单维聚类方法不再适合大数据的多样性特征。多维聚类分析通过对单维聚类问题的扩展,为复杂数据提供了一种新的探索性分析的方式。我们通过找到数据的不同侧面,按照这些侧面进行分别聚类,然后把各种聚类结果全部以一种简单的方式呈现给领域专家,由专家决定他认为最合适的聚类方法。这样的工作流程清晰定义数据科学家和领域专家的职能,通过两者的合作,提高数据的聚类结果,并且提升数据的可解释性。
关于作者

陈弢:香港科技大学计算机系博士,本科毕业于北大数学学院。现为EMC中国研究院大数据实验室senior research scientist。专注大规模数据分析,研究数据挖掘和机器学习算法在医疗、推荐、互联网等领域的应用。