
前言:
最近在看MongoDB相关知识,刚开始听到MongoDB时,一脸懵圈,这是个啥子数据库呀 。

但是通过学习后,发现这个数据库挺牛掰的呀;嘿嘿 。。。。下面就带大家一起聊聊这个数据库 ,看看它到底有什么牛掰之处 。
本文主线:
①、MongoDB 简介
②、MongoDB支持的功能有哪些?
③、MongoDB的存储引擎简述
④、MongoDB知识扩展
MongoDB 简介:
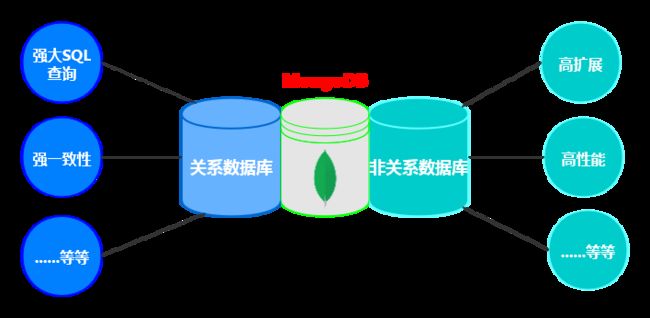
MongnDB是一个 分布式文件存储数据库 (或叫文档数据库);MongoDB是一个介于 关系数据库和非关系数据库 之间的产品,是非关系数据库当中功能最丰富,最像关系数据库,最接近关系型数据库的。
MongoDB的数据逻辑结构:
首先说下 MongoDB 的数据逻辑层次: 数据库(database)、集合(collection)、文档(document) 。
MongoDB数据逻辑层次的关系如下图:

MongoDB与关系数据库的数据逻辑结构比较:

通过上图可以知道MongoDB和关系数据库之间的数据逻辑结构对应关系了吧,再来将关系对应一下子:数据库 ------ 数据库 、 Table表 ------ Collection集合 、 Row 行记录 ------ Document 文档
下面咱来聊聊上图Document文档中 { "name" : "lyl", "age" : 25} 看起来跟 JSON 格式一样的数据到底是个什么东东?
MongoDB中文档的数据存储结构:
MongoDB的文件数据存储结构是 BSON ;Bson是 Binary JSON 缩写,是类似于JSON的文档的二进制编码序列化。
Bson的特点:
- 轻量性
- 可遍历性
- 高效性
来再具体看看MongoDB的Bson格式文档数据到底长神魔样呢?

通过上图我们对MongoDB整体有了一个基本的了解,接下来我们在简单聊聊它到底有哪些功能呢?看看它到底支持了什么 牛掰 的功能让它一直这么火。
MongoDB支持的功能:
咱先贴一张摘抄自网上的大图:描述MongoDB的主要特性;

除了支持上文的特性外,MongoDB还支持很多强大的功能:
BSON文档模型:
- 动态的数据模式
- 使用高效的二进制数据存储,包括大型对象(如视频等)。
- 动态查询
- 全文搜索
聚合操作:
- 聚合管道
- Map - Reduce
- 单一目的聚合方法
水平扩展(高扩展):
- 主从复制(搭建主从复制集群)
- 数据分片(搭建数据分片集群)
- 数据分片 + 主从复制 = 更加强大的集群系统
- 高可用、支持故障恢复
- 支持大文件存储GridFS
- 企业级安全
支持强大的索引:
- 单字段索引
- 复核索引
- 多键索引
- 文本索引
- 通配符索引
- 地理位置索引
- 哈希索引
索引特性:
- TTL索引
- 唯一索引
- 部分索引
- 稀疏索引
- 索引交集
- 4.0版本支持多文档事务,4.2版本支持分布式事务
支持多种存储引擎
- MMAP 存储引擎
- MMAPV1 存储引擎
- WiredTiger存储引擎
- In-Memory 存储引擎
注:上面只是列出的MongoDB主要支持的功能,想要了解具体的每项功能,可以自行去查阅资料昂。下面来聊聊MongoDB中十分重要的存储引擎,因为存储引擎是MongoDB负责管理数据的主要组件,并且像 事务、并发锁、存储数据的操作等 都是由存储引擎支持的。
MongoDB的存储引擎:
MongoDB支持多种存储引擎,下面咱们就简单聊聊MongoDB的这几种存储引擎;
原生存储引擎MMAP:
MMAP 全称为 Memory Mapped Storage Engine,即 内存映射存储引擎 ,在 3.0版本之前 使用的 。
MMAP可以把磁盘文件的一部分或全部内容直接映射到内存,这样文件中的信息位置就会在内存中有对应的地址空间,这时对文件的读写可以直接用指针来做,而不需要read/write函数了,但这并不代表将文件map到物理内存,只有访问到这块数据时才会被操作系统以Page的方式换到物理内存。
在MongoDB的写操作时,先将数据放在内存中,然后再通过顺序IO将数据刷新保存到磁盘上,这样会大大提升写操作性能;并且MongoDB将内存管理工作交给操作系统的虚拟内存管理器来完成,这样也大大简化了MongoDB的工作 。
原生升级 MMAPV1 存储引擎:
在 MongoDB3.0版本时 ,推出了 MMAPV1 存储引擎,这是在原生存储引擎基础上更新升级的新存储引擎 。
在 MMAPV1 存储引擎中有一个很重要的日志文件: journal预写事务日志 ,使用这个日志文件保证数据的持久化,并保证在数据库硬关闭时帮助数据库恢复。
插入式 WiredTiger 存储引擎:
WiredTiger是在 MongoDB3.0版本 引入的,并且在 MongoDB3.2版本 开始成为MongoDB默认的存储引擎。
相比较MMAPv1,WiredTiger存储引擎功能更强大,而且具有更高的性能。
WiredTiger存储引擎中也有 journal预写事务日志 ,用来保证数据持久化及数据库故障时数据恢复 。
In-Memory 存储引擎:
In-Memory存储引擎将数据库数据都存储在 内存 中,只将少量的元数据和诊断日志、临时数据存储到硬盘文件中,避免了磁盘I/O操作,查询速度很快。
如果MongoDB使用 In-Memory 存储引擎的话,是不是很类似于 Redis 内存数据库呢。
存储引擎之间的比较:
下面将通过在各方面比较下 MMAPV1 、WiredTiger 、In-Memory 这三种存储引擎,更加清晰的明确多种存储引擎之间的区别。
点击看大图:

注意:当各位大大阅读本文时,请一定要结合自己使用的 MongoDB的版本 ,因为不同版本支持的功能可能是不同的,确认好自己使用的版本是否支持想要的功能。
MongoDB 知识扩展:
为什么很吃内存?
在使用MongoDB数据库的时候,发现安装了MongoDB的服务器可用内存一直在减少,通过查找发现MongoDB在使用时一直在不断的吃内存,MongoDB占用的内存的越来越多。
为什么MongoDB这么占用内存呢?
下面简单从两方面说下:
- 通过上面的存储引擎的描述可以知道,例如 : WiredTiger存储引擎的写操作会先写入Cache中,将数据保存在内存中,然后再通过机制将内存中的数据落盘,但是最终内存中的数据还是会保留下来的,只是会将已经落盘的数据坐下标记。
- 当大量并发请求MongoDB数据库时,它使用的内存也会上涨;因为在并发连接比较多时,会大量创建处理连接的线程,这些线程也会占用内存的;除此之外,建立好连接后,处理连接中传输的数据包,这些数据包的存储也需要占用内存的;但是这种占用的内存会在请求下降后,慢慢的将内存释放的。
如何控制内存的使用:
下面简单在两方面聊下怎么控制MongoDB对内存的使用,希望别再触发服务器内存耗尽的告警了。
合理配置 WiredTiger cacheSizeGB 参数:
- 如果一台机器上只部署 MongoDB,MongoDB可以使用所有可用内存,则是用默认配置即可。
- 如果一台机器上不止部署了MongoDB,还运行一些其他的进程服务,则需要根据分给MongoDB的内存配额来配置 cacheSizeGB ,也可按配额的60%左右配置。
- 控制对MongoDB的并发请求数,进行合理的TCP连接数;
MongoDB的应用场景:
根据MongoDB的特性和支持的功能,简单聊聊它适用的应用场景:
应用服务器日志存储。
- MongoDB的高性能足够支撑关系型数据库2-3倍以上的TPS/QPS;
- 磁盘数据压缩存储,在进行数据读取时降低磁盘IO的次数,提升数据读取性能;
- 支持功能强大的索引
- 动态的数据模式,不受表结构的限制;
- 地理位置信息存储,通过地理位置索引,可以方便、快速的查询出具体的位置信息。
- 当作缓存数据库,使用其In-Memory 存储引擎;
- 网站实时数据处理;它非常适合实时的插入、更新与查询,并具备网站实时数据存储所需的复制及高度伸缩性。
------end到此本文就结束了,本文只是和大家聊了聊MongoDB的基础知识,细节部分都没有具体描述,大家如果感兴趣的可以自行去查阅资料。
最后了,再和大家唠叨下, 打算最近写下MongoDB系列文章,系列文章题目都已经想好了,如下:
①、初闻MongoDB(一)、从零带你了解MongoDB的前世今生
②、初识MongoDB(二)、数据库安装及可视化工具的安装使用
③、相识MongoDB(三)、MongoDB常用的SQL语句和索引知识
④、相知MongoDB(四)、使用java连接和操作MongoDB数据库
⑤、相爱MongoDB(五)、一文带你了解MongoDB的实战操作使用
❤ 点赞 + 评论 + 转发 哟
如果本文对您有帮助的话,请挥动下您爱发财的小手点下赞呀,您的支持就是我不断创作的动力,谢谢!
您可以VX搜索【木子雷】公众号,坚持高质量原创java技术文章,福利多多哟!
还有大家如果想看系列后续的文章话,请多多点赞评论呀,你们的支持就是我不断创作的动力!
