flv.js是一款优秀的开源web端flv文件播放器,flv格式目前广泛应用在直播及音视频录制领域。今天我们首先讲解flv.js播放文件的整体流程及数据获取部分的知识点,我会在之后的文章中继续讲解flv.js中解析flv数据格式的部分。
一 flv.js的使用示例
二 flv.js的整体运行流程
我认为flv关键的整体流程就是如何触发数据的获取,到数据的处理,再到数据的播放三个阶段。下面就分析示例中的代码,它们就是flv.js整体运行流程的入口,首先是调用了
createPlayer方法。
参数type传的是flv,该方法返回了FVLPlayer的实例,createPlayer源码如下:
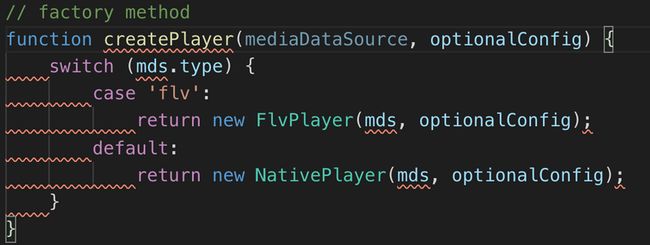
接下来调用的三个方法:
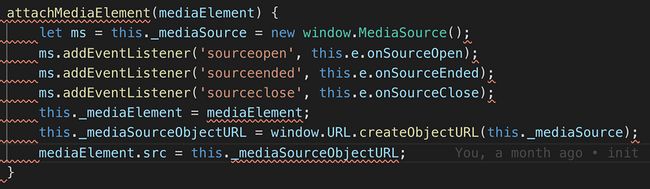
attachMediaElement()
是内部创建MediaSource对象,利用window.URL.createObjectURL创建URL赋值给video标签的src,关键代码如下:
load()
该方法必须要手动调一下,把里面的_hasPendingLoad置为true,关键代码如下:

play()
最后是play方法,如果不手动调用该方法 直接调用video标签的play方法和设置autoplay也可以。源码如下:
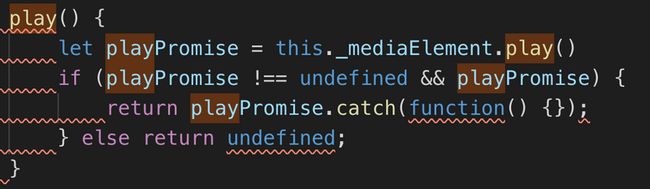
play之后关键就是触发了mediasource的sourceopen事件,将_mseSourceOpened置为true,_hasPendingLoad置为false,再次执行了load方法(这里如果在这之前不手动执行一次load方法,_hasPendingLoad则为false,也不会再次触发load)。

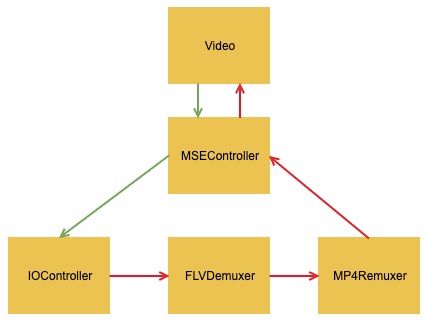
以上四个方法就是我们调用的API,之后内部的整体调用流程请参考下图,其中
- 蓝色的线表示MediaSourse绑定到video元素的过程。
- 绿色的线表示video的play方法触发到发起数据请求的过程。
- 红色的线代表获取到数据后进行flv格式的音视频分离,到mp4文件格式的封装格式转换,再到将转换后的数据添加到mediasource中供播放器播放的过程。
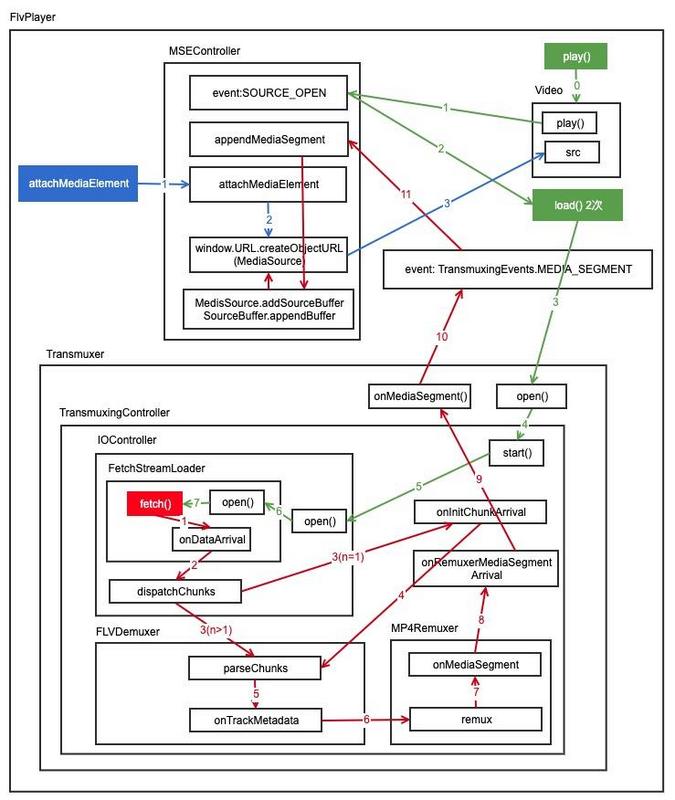
简化的流程如下:
三 MSE 概念及关键API
Media Source Extensions是一种标准,定义了我们可以通过JavaScript创建媒体流,并使用和<video>元素进行播放。
MediaSource 对象作为媒体源附着在Video标签的src上进行播放。
SourceBuffer 是MediaSource中真实的存放媒体流数据的容器。
URL.createObjectURL 方法的参数和返回值定义如下:
参数
object
用于创建 URL 的 File 对象、Blob 对象或者 MediaSource 对象。
返回值
一个DOMString包含了一个对象URL,该URL可用于指定源 object的内容。
生成的URL表示指定的 File 对象或 Blob 对象,在当前页面的生命周期有效,生成结果例如blob:http://localhost:5000/61832725-30dc-4923-94e6-3e536d5a41aa。所以这里我们用它将MediaSource对象生成URL传给Video的src。
最后它们的组合使用示例如下:
var video = document.getElementById('mse');
var ms = new MediaSource();
var audiobuffer = ms.addSourceBuffer('audio/mp4;codecs=mp4a.40.5');
var videobuffer = ms.addSourceBuffer('video/mp4;codecs=avc1.64001e');
video.src = URL.createObjectURL(ms);
ms.addEventListener('sourceopen', ()=>{
//fetchData加载数据
var {audiodata, videodata} = fetchData();
audiobuffer.appendBuffer(audiodata);
videobuffer.appendBuffer(videodata);
});
四 数据获取
flv.js的数据获取是在io-controller.js中控制,其中内部的_selectLoader方法用于判断选择哪种loader进行数据的加载。
这里讲其中三种有知识点的Loader

4.1 WebSocketLoader
这个loader中的代码是最简单的,要讲的原因是onmessage的MessageEvent中data的类型,通常我们都是使用string类型,但还可以是Blob或者ArrayBuffer类型,其读取方式如下:
var ws = new WebSocket(url);
ws.onmessage = function(e) {
if(e.data instanceof ArrayBuffer) {
this.dispatchData(e.data);
} else if(e.data instanceof Blob) {
let reader = new FileReader();
reader.onload = function() {
this.dispatchData(reader.result);
}
reader.readAsArrayBuffer(e.data);
}
}
4.2 FetchStreamLoader
这里的知识点是Fetch的body是ReadableStream类型。

一般常见的Fetch 返回的处理是转成某种格式并通过Promise进行返回,例如res.json()`res.arrayBuffer()`,这就意味着要返回的body整体结束才能够触发,而直播场景中的flv数据是流的形式,直播不结束返回也不会结束。
ReadableStream类型的对象就可以递归的调用read方法进行获取当前读到的数据。 使用示例如下:
let receiveLength = 0;
fetch(url, config).then(res=>{
readData(res.body.getReader());
function readData(reader) {
reader.read().then(result=>{
if(result.done) {
} else {
let chunk = result.value.buffer;
receiveLength += chunk.byteLength;
dispatchData(chunk);
readData(reader);
}
})
}
})
如果node作为后端的返回示例代码如下:
const fs = require('fs');
http.createServer((req, res)=>{
let stream = fs.createReadStream(fileAbsolutePath);
stream.pipe(res);
}).listen(9090);
4.3 XHRRangeLoader
这里的知识点是利用了http的范围请求,可用于flv录播,不可用于直播,我们可用于大文件的获取。Http协议中规定Header中的Range字段可以指定获取资源的字节范围,同时http server需要根据该字段获取到对应返回的数据进行返回,同时返回数据的字节范围及总字节数。 示例如下:
- Request
Range: bytes=0-393216
- Response
HTTP/1.1 206 Partial Content
Accept-Ranges: bytes
Content-Range: bytes 0-393216/5512723
具体的实现如下,js端的思路是先发送一个不带Range的请求 在onprogress阶段获取到Header中的总长度 然后中止请求,之后根据设置的范围大小进行分批获取。示例代码如下:
let contentLength = null;
let receivedLength = 0;
let originfrom = 0; // 数据的起点 默认一直示0
let to = 0;
let chunkSize = 384 * 1024;
getData();
function getData() {
let xhr = newXMLHttpRequest();
xhr.open('GET', url);
xhr.resposeType = 'arrayBuffer';
if(contentLength) {
from = originfrom + receivedLength;
to = from + chunkSize;
if(to - originfrom > contentLength) {
to = originfrom + contentLength - 1;
}
xhr.setRequestHeader('Range', `bytes=${from}-${to}`)
}
xhr.onpregress = function(e) {
if(!contentLength) {
contentLength = e.total;
xhr.abort();
getData();
}
}
xhr.onload = function() {
let chunk = e.target.response;
receivedLength += chunk.byteLength;
dispatchData(chunk, byteStart, receivedLength);
if(contentLength != null && receivedLength < contentLength) {
getData();
}
}
xhr.send();
}
如果用node作为服务端的实现思路还是利用createReadStream方法,从Header中获取返回,然后也获取对应的字节。
fs.createReadStream(path[, options])
options.start 和 optionsend 值,用于从文件中读取一定范围的字节,而不是读取整个文件。
示例代码如下:
const fs = require('fs');
http.createServer((req, res)=>{
let streamOpt = {};
if (req.headers.range) {
let {start, end} = getHeaderRange();
streamOpt.start = start;
streamOpt.end = end;
}
let stream = fs.createReadStream(fileAbsolutePath, streamOpt);
stream.pipe(res);
}).listen(9090);
总结:后续会继续发表其中的 网速计算、数据缓存、flv数据的音视频分离与mp4的封装格式转换实现 和 其中的知识点。
如果觉得有收获请关注微信公众号 前端良文 每周都会分享前端开发中的干货知识点。
