SQL经典短小代码收集
-SQL Server:
Select TOP N * From TABLE Order By NewID()
--开头到N条记录
Select Top N * From 表
--N到M条记录(要有主索引ID)
Select Top M-N * From 表Where ID in (Select Top M ID From 表) Order by ID Desc
--选择10从到15的记录
select top 5 * from (select top 15 * from table order by id asc) A order by id desc
--N到结尾记录
Select Top N * From 表Order by ID Desc
--显示最后5条记录,但是显示的顺序必须为5,6,7,8,9,10,而不是10,9,8,7,6,5 如下解决方法:
select top 5 from test where id in(select top 5 from test order by id desc) order by id asc
--通过这个问题也能总结出4-10条,5-100条这种限定一定范围内的sql语句的写法:
select top <末端ID-顶端ID+1> * from <表名> where ID not in(select top <顶端ID-1>) ID from <表名>)
--例如:4-10条就应该写成
select top 10-4+1 * from test where id not in(select top 4-1 id from test)
上一篇: select top 1 * from [news_table] where [新闻标识列]<当前id号 where ......
下一篇: select top 1 * from [news_table] where [新闻标识列]>当前id号 where ...... order by [新闻标识列] desc
create table t(name varchar(20))
-- DELETE t
INSERT INTO t
SELECT ' 1 ' UNION ALL
SELECT ' 2 ' UNION ALL
SELECT ' 3 ' UNION ALL
SELECT ' 5 ' UNION ALL
SELECT ' 5 ' UNION ALL
SELECT ' 5 ' UNION ALL
SELECT ' 6 ' UNION ALL
SELECT ' 3 ' UNION ALL
SELECT ' 4 '
/* 找出相同的 */
3
5
5
5
3
-- 1. in
SELECT *
FROM t
WHERE NAME IN ( SELECT name
FROM t
GROUP BY name
HAVING COUNT (name) > 1 )
-- 2. join
SELECT t. *
FROM t
JOIN ( SELECT name
FROM t
GROUP BY name
HAVING COUNT (name) > 1
) a ON T.NAME = a.name
-- 3 . EXISTS
SELECT *
FROM t
WHERE EXISTS ( SELECT *
FROM ( SELECT name
FROM t
GROUP BY name
HAVING COUNT (name) > 1
) a
WHERE a.NAME = t.name )
-- 4. 2005 ROW_NUMBER()
SELECT t. *
FROM t
JOIN ( SELECT *
FROM ( SELECT ROW_NUMBER() OVER ( PARTITION BY NAME ORDER BY name ) AS id ,
name
FROM t
) a
WHERE id = 2
) b ON t.NAME = b.name
清理日志:
select * from sysfiles
dump transaction CTC315 with no_log
DBCC SHRINKFILE ( ' CTC315_Log ' )
set ANSI_NULLS ON
set QUOTED_IDENTIFIER ON
go
create procedure [ dbo ] . [ p清除日志 ]
@databasename varchar ( 100 ) -- 数据库名称
as
begin
declare @execsql nvarchar ( max ), -- 执行语句
@logfilename varchar ( 100 ) -- 日志逻辑文件
select @execsql = ' select @filename=name from ' + @databasename
+ ' .dbo.[sysfiles] where fileid=2 ' -- 查询文件名
-- select 1,@execsql,@logfilename
exec sp_executesql @execsql ,N ' @filename varchar(100) output ' , @logfilename output
-- select 1,@logfilename
select @execsql = ' use ' + @databasename
+ ' dump transaction ' + @databasename + ' with no_log '
+ ' DBCC SHRINKFILE ( ' + @logfilename + ' ) ' -- 清除脚本
-- select @execsql
exec sp_executesql @execsql -- 清除
end
/*
exec [p清除日志] 'master'
*/
BACKUP TRANSACTION DBName WITH TRUNCATE_ONLY DBCC SHRINKFILE( 2 , 200 )
SQL 2005 :
在 SQL 2005 中備份 Transaction Log 語法改為 Backup LOG
BACKUP LOG DBName WITH NO_LOG
DBCC SHRINKFILE( 2 , 200 )
SQL 2008 :
必須先將復原模式改為 "簡單" 才能清除,完成之後再將模式改回 "完整"
USE DBName
Alter Database DBName Set Recovery Simple DBCC SHRINKFILE( 2 , 100 ) Alter Database DBName Set Recovery Full
SQL 2008 R2:
USE DBName;
GO
-- Truncate the log by changing the database recovery model to SIMPLE.
ALTER DATABASE DBName
SET RECOVERY SIMPLE;
GO
-- Shrink the truncated log file to 10 MB.
DBCC SHRINKFILE ( 2 , 10 );
GO
-- Reset the database recovery model.
ALTER DATABASE DBName
SET RECOVERY FULL ;
GO
* 上述 DBCC SHRINKFILE ( 2 , 10 ),2指的是LOG File , 10指的是壓到10MB哦!
一个表中的Id有多个记录,把所有这个id的记录查出来,并显示共有多少条记录数。
------------------------------------------
select id, Count(*) from tb group by id having count(*)>1
--两条记录完全相同,如何删除其中一条
set rowcount=1
delete from thetablename where id=@duplicate_id--@duplicate_id为重复值的id
--模糊查询
select * from product where detail like '%123.jpg%'
--替换字段里面部分内容
update product set detail=replace(cast(detail as varchar(8000)),'abc.jpg','efg.jpg')
( 1 ) FROM ( 1 - J) < left_table > < join_type > JOIN < right_table > ON < on_predicate >
| ( 1 - A) < left_table > < apply_type > APPLY < right_table_expression > AS < alias >
| ( 1 - P) < left_table > PIVOT( < pivot_specification > ) AS < alias >
| ( 1 - U) < left_table > UNPIVOT( < unpivot_specification > ) AS < alias >
( 2 ) WHERE < where_predicate >
( 3 ) GROUP BY < group_by_specification >
( 4 ) HAVING < having_predicate >
( 6 ) ORDER BY < order_by_list >
Select Convert (Numeric( 20 , 2 ), IsNull ( 50.01634 , 0 ))
-- 50.02
Select Convert (Numeric( 20 , 2 ), IsNull ( 9 , 0 ))
-- 9.00
--日期转换参数,值得收藏
select CONVERT(varchar, getdate(), 120 )
2004-09-12 11:06:08
select replace(replace(replace(CONVERT(varchar, getdate(), 120 ),'-',''),' ',''),':','')
20040912110608
select CONVERT(varchar(12) , getdate(), 111 )
2004/09/12
select CONVERT(varchar(12) , getdate(), 112 )
20040912
select CONVERT(varchar(12) , getdate(), 102 )
2004.09.12
--一个月第一天
SELECT DATEADD(mm, DATEDIFF(mm,0,getdate()), 0) -- 2009-06-01 00:00:00.000
--当天
select * from product where DateDiff(day,modiDate,GetDate())>1
--如何查询本日、本月、本年的记录SQL
本年:
select * from loanInfo where year(date)=year(getdate())
本月:
select * from loanInfo where year(date)=year(getDate()) And month(date)=month(getdate())
本日:
select * from loanInfo where year(date)=year(getDate()) And month(date)=month(getdate()) and Day(date)=Day(getDate())
昨天的记录:
datediff(day,[Datetime],getdate())=1 把Datetime换为你的相应字段,getdate()-Datetime即为时间差。
本月记录:
SELECT * FROM 表 WHERE datediff(month,[dateadd],getdate())=0
本周记录:
SELECT * FROM 表 WHERE datediff(week,[dateadd],getdate())=0
本日记录:
SELECT * FROM 表 WHERE datediff(day,[dateadd],getdate())=0
本周的星期一 SELECT DATEADD(wk, DATEDIFF(wk,0,getdate()), 0)
一年的第一天 SELECT DATEADD(yy, DATEDIFF(yy,0,getdate()), 0)
季度的第一天 SELECT DATEADD(qq, DATEDIFF(qq,0,getdate()), 0)
当天的半夜 SELECT DATEADD(dd, DATEDIFF(dd,0,getdate()), 0)
上个月的最后一天
这是一个计算上个月最后一天的例子。它通过从一个月的最后一天这个例子上减去毫秒来获得。有一点要记住,在Sql Server中时间是精确到毫秒。这就是为什么我需要减去毫秒来获得我要的日期和时间。
SELECT dateadd(ms,-3,DATEADD(mm, DATEDIFF(mm,0,getdate()), 0))
计算出来的日期的时间部分包含了一个Sql Server可以记录的一天的最后时刻(“:59:59:997”)的时间。
去年的最后一天
连接上面的例子,为了要得到去年的最后一天,你需要在今年的第一天上减去毫秒。
SELECT dateadd(ms,-3,DATEADD(yy, DATEDIFF(yy,0,getdate()), 0))
本月的最后一天
现在,为了获得本月的最后一天,我需要稍微修改一下获得上个月的最后一天的语句。修改需要给用DATEDIFF比较当前日期和“-01-01”返回的时间间隔上加。通过加个月,我计算出下个月的第一天,然后减去毫秒,这样就计算出了这个月的最后一天。这是计算本月最后一天的SQL脚本。
SELECT dateadd(ms,-3,DATEADD(mm, DATEDIFF(m,0,getdate())+1, 0))
本年的最后一天
你现在应该掌握这个的做法,这是计算本年最后一天脚本
SELECT dateadd(ms,-3,DATEADD(yy, DATEDIFF(yy,0,getdate())+1, 0))。
本月的第一个星期一
好了,现在是最后一个例子。这里我要计算这个月的第一个星期一。这是计算的脚本。
select DATEADD(wk, DATEDIFF(wk,0,
dateadd(dd,6-datepart(day,getdate()),getdate())
), 0)
在这个例子里,我使用了“本周的星期一”的脚本,并作了一点点修改。修改的部分是把原来脚本中“getdate()”部分替换成计算本月的第天,在计算中用本月的第天来替换当前日期使得计算可以获得这个月的第一个星期一。
--删除一个月前,三个月前, 6个月前,一年前的数据
DELETE FROM 表名WHERE datediff(MM, AddTime,GETDATE()) > 1
DELETE FROM 表名WHERE datediff(MM, AddTime,GETDATE()) > 3
DELETE FROM 表名WHERE datediff(MM, AddTime,GETDATE()) > 6
DELETE FROM 表名WHERE datediff(YY, AddTime,GETDATE()) > 1
---------------------------------------------------------------
附录,其他日期处理方法
1)去掉时分秒
declare @ datetime
set @ = getdate() --'2003-7-1 10:00:00'
SELECT @,DATEADD(day, DATEDIFF(day,0,@), 0)
2)显示星期几
select datename(weekday,getdate())
3)如何取得某个月的天数
declare @m int
set @m=2 --月份
select datediff(day,'2003-'+cast(@m as varchar)+'-15' ,'2003-'+cast(@m+1 as varchar)+'-15')
另外,取得本月天数
select datediff(day,cast(month(GetDate()) as varchar)+'-'+cast(month(GetDate()) as varchar)+'-15' ,cast(month(GetDate()) as varchar)+'-'+cast(month(GetDate())+1 as varchar)+'-15')
任意月份的最大天数
select day(dateadd(dd,-1,dateadd(mm,1,Dateadd(mm,datediff(mm,0,getdate()),0))))
或者使用计算本月的最后一天的脚本,然后用DAY函数区最后一天
SELECT Day(dateadd(ms,-3,DATEADD(mm, DATEDIFF(m,0,getdate())+1, 0)))
4)判断是否闰年:
SELECT case day(dateadd(mm, 2, dateadd(ms,-3,DATEADD(yy, DATEDIFF(yy,0,getdate()), 0)))) when 28 then '平年' else '闰年' end
或者
select case datediff(day,datename(year,getdate())+'-02-01',dateadd(mm,1,datename(year,getdate())+'-02-01'))
when 28 then '平年' else '闰年' end
5)一个季度多少天
declare @m tinyint,@time smalldatetime
select @m=month(getdate())
select @m=case when @m between 1 and 3 then 1
when @m between 4 and 6 then 4
when @m between 7 and 9 then 7
else 10 end
select @time=datename(year,getdate())+'-'+convert(varchar(10),@m)+'-01'
select datediff(day,@time,dateadd(mm,3,@time))
1、确定某年某月有多少天
实现原理:先利用DATEDIFF取得当前月的第一天,再将月份加一取得下月第一天,然后减去分钟,再取日期的天数部分,即为当月最大日期,也即当月天数
CREATE FUNCTION DaysInMonth ( @date datetime ) Returns int
AS
BEGIN
RETURN Day(dateadd(mi,-3,DATEADD(m, DATEDIFF(m,0,@date)+1,0)))
END
调用示例:
select dbo.DaysInMonth ('2006-02-03')
(2)计算哪一天是本周的星期一
SELECT DATEADD(week, DATEDIFF(week,'1900-01-01',getdate()), '1900-01-01') --返回-11-06 00:00:00.000
或
SELECT DATEADD(week, DATEDIFF(week,0,getdate()),0)
(3)当前季度的第一天
SELECT DATEADD(quarter, DATEDIFF(quarter,0,getdate()), 0)—返回-10-01 00:00:00.000
(4)一个季度多少天
declare @m tinyint,@time smalldatetime
select @m=month(getdate())
select @m=case when @m between 1 and 3 then 1
when @m between 4 and 6 then 4
when @m between 7 and 9 then 7
else 10 end
select @time=datename(year,getdate())+'-'+convert(varchar(10),@m)+'-01'
select datediff(day,@time,dateadd(mm,3,@time)) —返回
1.按姓氏笔画排序:
Select * From TableName Order By CustomerName Collate Chinese_PRC_Stroke_ci_as
2.分页SQL语句
select * from(select (row_number() OVER (ORDER BY tab.ID Desc)) as rownum,tab.* from 表名As tab) As t where rownum between 起始位置And 结束位置
8.如何修改数据库的名称:
sp_renamedb 'old_name', 'new_name'
3.获取当前数据库中的所有用户表
select * from sysobjects where xtype='U' and category=0
4.获取某一个表的所有字段
select name from syscolumns where id=object_id('表名')
5.查看与某一个表相关的视图、存储过程、函数
select a.* from sysobjects a, syscomments b where a.id = b.id and b.text like '%表名%'
6.查看当前数据库中所有存储过程
select name as 存储过程名称from sysobjects where xtype='P'
7.查询用户创建的所有数据库
select * from master..sysdatabases D where sid not in(select sid from master..syslogins where name='sa')
或者
select dbid, name AS DB_NAME from master..sysdatabases where sid <> 0x01
8.查询某一个表的字段和数据类型
select column_name,data_type from information_schema.columns where table_name = '表名'
9.使用事务
在使用一些对数据库表的临时的SQL语句操作时,可以采用SQL SERVER事务处理,防止对数据操作后发现误操作问题
开始事务
Begin tran
Insert Into TableName Values(…)
SQL语句操作不正常,则回滚事务。
回滚事务
Rollback tran
SQL语句操作正常,则提交事务,数据提交至数据库。
提交事务
Commit tran
计算执行SQL语句查询时间
declare @d datetime
set @d=getdate()
select * from SYS_ColumnProperties select [语句执行花费时间(毫秒)]=datediff(ms,@d,getdate())
【关闭SQL Server 数据库所有使用连接】
use master
go
create proc KillSpByDbName(@dbname varchar(20))
as
begin
declare @sql nvarchar(500),@temp varchar(1000)
declare @spid int
set @sql='declare getspid cursor for
select spid from sysprocesses where dbid=db_id('''+@dbname+''')'
exec (@sql)
open getspid
fetch next from getspid into @spid
while @@fetch_status <>-1
begin
set @temp='kill '+rtrim(@spid)
exec(@temp)
fetch next from getspid into @spid
end
close getspid
deallocate getspid
end
--举例使用,关闭数据库下的所有连接操作
Use master
Exec KillSpByDbName '数据库名称'
(一)挂起操作
在安装Sql或sp补丁的时候系统提示之前有挂起的安装操作,要求重启,这里往往重启无用,解决办法:
到HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlSession Manager
删除PendingFileRenameOperations
(二)收缩数据库
--重建索引
DBCC REINDEX
DBCC INDEXDEFRAG
--收缩数据和日志
DBCC SHRINKDB
DBCC SHRINKFILE
(三)压缩数据库
dbcc shrinkdatabase(dbname)
(四)转移数据库给新用户以已存在用户权限
exec sp_change_users_login update_one,newname,oldname
go
(五)检查备份集
RESTORE VERIFYONLY from disk=Evbbs.bak
(六)修复数据库
ALTER DATABASE [dvbbs] SET SINGLE_USER
GO
DBCC CHECKDB(dvbbs,repair_allow_data_loss) WITH TABLOCK
GO
ALTER DATABASE [dvbbs] SET MULTI_USER
GO
select top m * from tablename where id not in (select top n id from tablename)
select top m * into 临时表(或表变量) from tablename order by columnname -- 将top m笔插入
set rowcount n
select * from 表变量order by columnname desc
select top n * from
(select top m * from tablename order by columnname) a
order by columnname desc
-- 10- 换行, 13 - 回车, 32 - 空格 ,160 - 空格
SELECT
LTRIM ( RTRIM ( REPLACE ( REPLACE ( REPLACE ( [ YourColumn ] , CHAR ( 10 ), CHAR ( 32 )),
CHAR ( 13 ), CHAR ( 32 )), CHAR ( 160 ),
CHAR ( 32 )))) AS [ YourColumn ]
FROM [ YourTable ]
复制表(只复制结构,源表名:a 新表名:b) (Access可用)
法一:select * into b from a where 1 <>1
法二:select top 0 * into b from a
拷贝表(拷贝数据,源表名:a 目标表名:b) (Access可用)
insert into b(a, b, c) select d,e,f from b;
跨数据库之间表的拷贝(具体数据使用绝对路径) (Access可用)
insert into b(a, b, c) select d,e,f from b in ‘具体数据库’where 条件
例子:..from b in '"&Server.MapPath(".")&"\data.mdb" &"' where..
子查询(表名:a 表名:b)
select a,b,c from a where a IN (select d from b ) 或者: select a,b,c from a where a IN (1,2,3)
显示文章、提交人和最后回复时间
select a.title,a.username,b.adddate from table a,(select max(adddate) adddate from table where table.title=a.title) b
外连接查询(表名:a 表名:b)
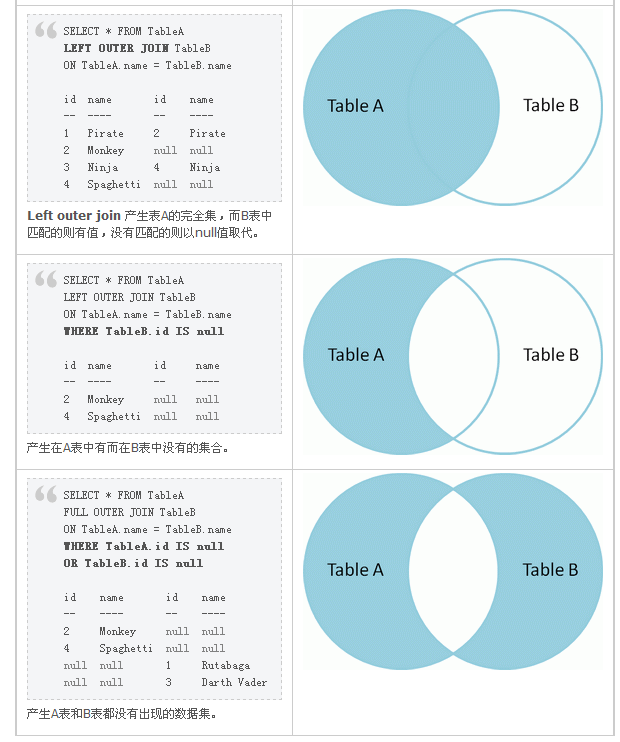
select a.a, a.b, a.c, b.c, b.d, b.f from a LEFT OUT JOIN b ON a.a = b.c
在线视图查询(表名:a )
select * from (SELECT a,b,c FROM a) T where t.a > 1;
between的用法,between限制查询数据范围时包括了边界值,not between不包括
select * from table1 where time between time1 and time2
select a,b,c, from table1 where a not between 数值and 数值
in 的使用方法
select * from table1 where a [not] in (‘值’,’值’,’值’,’值’)
两张关联表,删除主表中已经在副表中没有的信息
delete from table1 where not exists ( select * from table2 where table1.field1=table2.field1 )
四表联查问题:
select * from a left inner join b on a.a=b.b right inner join c on a.a=c.c inner join d on a.a=d.d where ..
日程安排提前五分钟提醒
SQL: select * from 日程安排where datediff('minute',f开始时间,getdate())>5
一条sql 语句搞定数据库分页
select top 10 b.* from (select top 20 主键字段,排序字段from 表名order by 排序字段desc) a,表名b where b.主键字段= a.主键字段order by a.排序字段
选择在每一组b值相同的数据中对应的a最大的记录的所有信息(类似这样的用法可以用于论坛每月排行榜,每月热销产品分析,按科目成绩排名,等等.)
select a,b,c from tablename ta where a=(select max(a) from tablename tb where tb.b=ta.b)
包括所有在TableA 中但不在TableB和TableC 中的行并消除所有重复行而派生出一个结果表
(select a from tableA ) except (select a from tableB) except (select a from tableC)
随机取出条数据
select top 10 * from tablename order by newid()
随机选择记录
select newid()
SET Result3 = 0
FROM SEND b
JOIN (
SELECT TOP 10 *
FROM SEND
WHERE Result3 IS NULL
AND BatchID = ' 20101004093814 '
ORDER BY
NEWID ()
) a
ON a.sendid = b.sendid
Delete from tablename where id not in (select max(id) from tablename group by col1,col2,)
select distinct * into #Tmp from TB
drop table TB
select * into TB from #Tmp
drop table #Tmp
在几千条记录里,存在着些相同的记录,如何能用SQL语句,删除掉重复的呢?
1、查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断
select * from people
where peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)
2、删除表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断,只留有rowid最小的记录
delete from people
where peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)
and rowid not in (select min(rowid) from people group by peopleId having count(peopleId )>1)
3、查找表中多余的重复记录(多个字段)
select * from vitae a
where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)
4、删除表中多余的重复记录(多个字段),只留有rowid最小的记录
delete from vitae a
where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)
and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)
5、查找表中多余的重复记录(多个字段),不包含rowid最小的记录
select * from vitae a
where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)
and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)
经典尝试 删除重复值
declare @table table (id int,name nvarchar(10))
insert into @table select 1,'aa'
union all select 1,'aa'
union all select 2,'bb'
union all select 3,'bb'
union all select 4,'cc'
union all select 1,'aa'
union all select 4,'cc'
delete a
from (
select id,name,rn = row_number() over (partition by id,name order by id) from @table
) a where rn > 1
select * from @table
id name
----------- ----------
1 aa
2 bb
3 bb
4 cc
(4 row(s) affected)
--float字段保留一位小数,四舍五入
SELECT CONVERT(DECIMAL(18,1),1024.791454) ------- 1024.8 (所影响的行数为1 行)
<%# Eval("字段")==null?"":Eval("字段").toString("0.0") %>