1.Request()的参数
import urllib.request
request=urllib.request.Request('https://python.org')
response=urllib.request.urlopen(request)
print(response.read().decode('utf-8'))
通过构造这个数据结构,一方面可以我们可以将请求独立成一个对象,另一方面可以更加丰富和灵活地配置参数。
它的构造方法如下:
class.urllib.request.Request(url,data=None,headers={},origin_rep_host=None,unverifiable=False,method=None)
参数:
1.url必传参数
2.data,必须传bytes类型。如果是字典,先使用urllib.parse里的urlencode()
3.headers,是一个字典,请求头,直接构造或者用add_header()方法添加
4.origin_rep_host,请求方的名称或者ip地址
5.unverifiable,默认为false,表示这个请求是否无法验证。如果没有抓取的权限,此时值就是true。
6.method,用来指示请求使用的方法。
尝试传入多个参数构建请求:
from urllib import request,parse
url='http://httpbin.org/post'
headers={
'Url-Agent':'Mozilla/4.0(compatible;MSIE 5.5;Windows NT)',
'Host':'httpbin.org'
}#也可以使用add_header()方法添加headers:#req=request.Request(url=url,data=data,method='POST')#req.add_header('User-Agent','Mozilla/4.0(compatible;MSIE 5.5;Windows NT)')
dict={
'name':'Germey'
}
data=bytes(parse.urlencode(dict),encoding='utf-8')#用urlencode()将dict转换成bytes类型,传递给data
req=request.Request(url=url,data=data,headers=headers,method='POST')
response=request.urlopen(req)
print(response.read().decode('utf-8'))
运行结果:
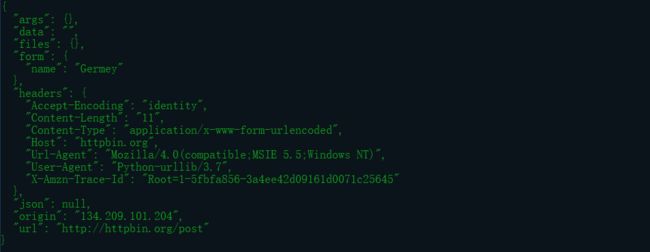
2.Handler与Opener
Handler:
它是各种处理器,几乎可以做到HTTP请求中的所有事情。
urllib.request模块里的BaseHandler类,它是所有其他Headler的父类,它提供了最基本的方法。
Opener:
例如urlopen()就是一个Opener,它是urllib为我们提供的。
它们的关系是:使用Handler来构建Opener。
3.用法
验证:
创建一个需要验证的网站,我这里使用的是IIS
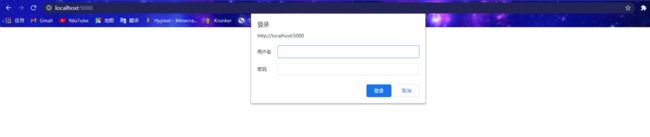
遇到的问题:
IIS怎样安装与配置-百度经验 (baidu.com)
IIS网站如何设置基本身份验证-百度经验 (baidu.com)
window10家庭版解决IIS中万维网服务的安全性中无Windows身份验证 - enjoryWeb - 博客园 (cnblogs.com)
代码:
from urllib.request import HTTPPasswordMgrWithDefaultRealm,HTTPBasicAuthHandler,build_opener
from urllib.error import URLError
username='username'#填上自己的用户名和密码
password='password'
url='http://localhost:5000/'
p=HTTPPasswordMgrWithDefaultRealm()
p.add_password(None,url,username,password)#添加用户名和密码,建立了一个处理验证的Handler
auth_handler=HTTPBasicAuthHandler(p)#基本认证
opener=build_opener(auth_handler)#利用Handler构建一个Opener
try:
result=opener.open(url)#打开链接
html=result.read().decode('utf-8')
print(html)#结果打印html源码内容
except URLError as e:
print(e.reason)
代理:
添加代理,在本地搭建一个代理,运行在9743端口上。
代码:
from urllib.request import ProxyHandler,build_opener
from urllib.error import URLError
proxy_handler=ProxyHandler({
'http':'http://127.0.0.1:9743',
'https':'https://127.0.0.1:9743'
})#构建一个Handler
opener=build_opener(proxy_handler)#构建一个Opener
try:
response=opener.open('https://www.baidu.com')
print(response.read().decode('utf-8'))
except URLError as e:
print(e.reason)
Cookies:
将网站的Cookies获取下来:
代码:
import http.cookiejar,urllib.request
cookie=http.cookiejar.CookieJar()#声明一个CookieJar对象
handler=urllib.request.HTTPCookieProcessor(cookie)#构建一个Handler
opener=urllib.request.build_opener(handler)#构建一个Opener
response=opener.open('http://www.baidu.com')
for item in cookie:
print(item.name+"="+item.value)
运行结果:

将Cookie输出成文件格式:
代码:
import http.cookiejar,urllib.request
filename='cookies.txt'
cookie=http.cookiejar.MozillaCookieJar(filename)
#MozillaCookieJar()生成文件时用到,用来处理Cookie和文件相关的事件
#如果要保存LWP格式的Cookies文件,可以改为:
#cookie=http.cookiejar.LWPCookieJar(filename)handler=urllib.request.HTTPCookieProcessor(cookie)
opener=urllib.request.build_opener(handler)
response=opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True,ignore_expires=True)
运行结果:
# Netscape HTTP Cookie File # http://curl.haxx.se/rfc/cookie_spec.html # This is a generated file! Do not edit. .baidu.com TRUE / FALSE 1638359640 BAIDUID 9BB1BA4FDD840EBD956A3D2EFB6BF883:FG=1 .baidu.com TRUE / FALSE 3754307287 BIDUPSID 9BB1BA4FDD840EBD25D00EE8183D1125 .baidu.com TRUE / FALSE H_PS_PSSID 1445_33119_33059_31660_33099_33101_26350_33199 .baidu.com TRUE / FALSE 3754307287 PSTM 1606823639 www.baidu.com FALSE / FALSE BDSVRTM 7 www.baidu.com FALSE / FALSE BD_HOME 1
LWP格式:
#LWP-Cookies-2.0 Set-Cookie3: BAIDUID="DDF5CB401A1543ED614CE42962D48099:FG=1"; path="/"; domain=".baidu.com"; path_spec; domain_dot; expires="2021-12-01 12:04:18Z"; comment=bd; version=0 Set-Cookie3: BIDUPSID=DDF5CB401A1543ED00860C3997C3282C; path="/"; domain=".baidu.com"; path_spec; domain_dot; expires="2088-12-19 15:18:25Z"; version=0 Set-Cookie3: H_PS_PSSID=1430_33058_31254_33098_33101_33199; path="/"; domain=".baidu.com"; path_spec; domain_dot; discard; version=0 Set-Cookie3: PSTM=1606824257; path="/"; domain=".baidu.com"; path_spec; domain_dot; expires="2088-12-19 15:18:25Z"; version=0 Set-Cookie3: BDSVRTM=0; path="/"; domain="www.baidu.com"; path_spec; discard; version=0 Set-Cookie3: BD_HOME=1; path="/"; domain="www.baidu.com"; path_spec; discard; version=0
以LWP格式的文件为示例,展示读取和利用的方法:
代码:
import http.cookiejar,urllib.request
cookie=http.cookiejar.LWPCookieJar()
#如果文件保存为Mozilla型浏览器格式,可以改为:
#cookie=http.cookiejar.MozillaCookieJar()cookie.load('cookies.txt',ignore_discard=True,ignore_expires=True)
#调用load()方法来读取本地的Cookies文件,获取Cookies的内容handler=urllib.request.HTTPCookieProcessor(cookie)
opener=urllib.request.build_opener(handler)
response=opener.open('http://www.baidu.com')
print(response.read().decode('utf-8'))
运行结果:输出网页源代码。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。