前言
很高兴遇见你~
在 深入剖析HashMap 文章中我从散列表的角度解析了HashMap,在 深入解析ConcurrentHashMap:感受并发编程智慧 解析了ConcurrentHashMap的底层实现原理。本文是HashMap系列文章的第三篇,主要内容是讲解与HashMap相关的集合类。
HashMap本身功能已经相对完善,但在某些特殊的情景下,他就显得无能为力,如高并发、需要记住key插入顺序、给key排序等。实现这些功能往往需要付出一定的代价,在没有必然的需求情景下,增添这些功能是没必要的。因而,为了提高性能,Java并没有把这些特性直接集成到HashMap中,拓展了拥有这些特性的其他集合类作为补充:
- 线程安全的ConcurrentHashMap、Hashtable、SynchronizeMap
- 记住插入顺序的LinkedHashMap
- 记录key顺序的TreeMap
这样,我们就可以在特定的需求情景下,选择最适合我们的集合框架,从而来提高性能。那么今天这篇文章,主要就是分析这些其他的集合类的特性、付出的性能代价、与HashMap的区别。
那么,我们开始吧~
Hashtable
Hashtable是属于JDK1.1的第一批集合框架其中之一,其他的还有Vector、Stack等。这些集合框架由于设计上的缺陷,导致了性能的瓶颈,在jdk1.2之后就被新的一套集合框架取代,也就是HashMap、ArrayList这些。HashMap在jdk1.8之后进行了全面的优化,而Hashtable依旧保持着旧版本的设计,在很多方面都落后于HashMap。下面主要分析Hashtable在:接口继承、哈希函数、哈希冲突、扩容方案、线程安全等方面解析他们的不同。
接口继承
Hashtable继承自Dictionary类而不是AbstractMap,类图如下(jdk1.8)
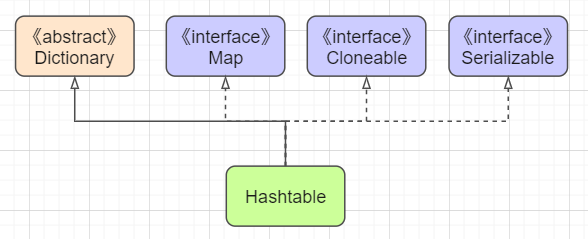
Hashtable诞生的时间是比Map早,但为了兼容新的集合在jdk1.2之后也继承了Map接口。Dictionary在目前已经完全被Map取代了,所以更加建议使用继承自AbstractMap的HashMap。为了兼容新版本接口还有Hashtable的迭代器:Enumerator。他的接口继承结构如下:
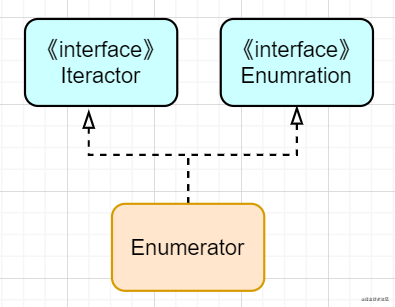
他不仅实现了旧版的Enumeration接口,同时也实现了Iteractor接口,兼容了新的api与使用习惯。这里关于Hashtable还有一个问题:Hashtable是fast-fail的吗 ?
fast-fail指的是在使用迭代器遍历集合过程中,如果集合发生了结构性改变,如添加数据、扩容、删除数据等,迭代器会抛出异常。Enumerator本身的实现是没有fast-fail设计的,但他继承了Iteractor接口之后,就有了fast-fail。看一下源码:
public T next() {
// 这里在Enumerator的基础上,增加了fast-fail
if (Hashtable.this.modCount != expectedModCount)
throw new ConcurrentModificationException();
// nextElement()是Enumeration的接口方法
return nextElement();
}
private void addEntry(int hash, K key, V value, int index) {
...
// 在添加数据之后,会改变modCount的值
modCount++;
}所以,Hashtable本身的设计是有fastfail的,但如果使用的Enumerator,则享受不到这个设计了。
哈希算法
Hashtable的哈希算法非常简单粗暴,如下代码
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;获取key的hashcode,通过直接对数组长度求余来获取下标。这里还有一步是hash & 0x7FFFFFFF,目的是把最高位变成0,把hashcode变成一个非负数。为了使得hash可以分布更加均匀,Hashtable默认控制数组的长度为一个素数:初始值为11,每次扩容为原来的两倍+1 。
冲突解决
Hashtable使用的是链表法,也称为拉链法。发生冲突之后会转换为链表。HashMap在jdk1.8之后增加了红黑树,所以在剧烈冲突的情况下,Hashtable的性能下降会比HashMap明显非常多。
Hashtable的装载因子与HashMap一致,默认都是0.75,且建议非特殊情况不要进行修改。
扩容方案
Hashtable的扩容方案也非常简单粗暴,新建一个长度为原来的两倍+1长度的数组,遍历所有的旧数组的数据,重新hash插入新的数组。他的源码非常简单,有兴趣可以看一下:
protected void rehash() {
int oldCapacity = table.length;
Entry[] oldMap = table;
// 设置数组长度为原来的2倍+1
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
// 如果长度达到最大值,则直接返回
return;
// 超过最大值设置长度为最大
newCapacity = MAX_ARRAY_SIZE;
}
// 新建数组
Entry[] newMap = new Entry[newCapacity];
// modcount++,表示发生结构性改变
modCount++;
// 初始化装载因子,改变table引用
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap;
// 遍历所有的数据,重新hash后插入新的数组,这里使用的是头插法
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry old = (Entry)oldMap[i] ; old != null ; ) {
Entry e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry)newMap[index];
newMap[index] = e;
}
}
} 线程安全
Hashtable和HashMap最大的不同就是线程安全了。jdk1.1的第一批集合框架都被设计为线程安全,但手段都非常粗暴:直接给所有方法上锁 。但我们知道,锁是一个非常重量级的操作,会严重影响性能。Hashtable直接对整个对象上锁的缺点有:
- 同一时间只能有一个线程在读或者写,并发效率极低
- 频繁上锁进行系统调用,严重影响性能
所以虽然Hashtable实现了一定程度上的线程安全,但是却付出了非常大的性能代价。这也是为什么在jdk1.2他们马上就被淘汰了。
不允许空键值
允许空键值这个设计有利也有弊,在ConcurrentHashMap中也禁止插入空键值,但HashMap是允许的。允许value空值会导致get方法返回null时有两种情况:
- 找不到对应的key
- 找到了但是value为null;
当get方法返回null时无法判断是哪种情况,在并发环境下containsKey方法已不再可靠,需要返回null来表示查询不到数据。允许key空值需要额外的逻辑处理,占用了数组空间,且并没有多大的实用价值。HashMap支持键和值为null,但基于以上原因,ConcurrentHashMap是不支持空键值。
小结
总体来说,Hashtable属于旧版本的集合框架,他的设计已经落后了,官方更加推荐使用HashMap;而Hashtable线程安全的特性的同时,也带来了极大的性能代价,更加推荐使用ConcurrentHashMap来代替Hashtable。
SynchronizeMap
SynchronizeMap这个集合类可能并不太熟悉,他是Collections.synchronizeMap()方法返回的对象,如下:
public static Map synchronizedMap(Map m) {
return new SynchronizedMap<>(m);
} SynchronizeMap的作用是保证了线程安全,但是他的方法和Hashtable一致,也是简单粗暴,直接加锁,如下图:

这里的mutex是什么呢?直接看到构造器:
final Object mutex; // Object on which to synchronize
SynchronizedMap(Map m) {
this.m = Objects.requireNonNull(m);
// 默认为本对象
mutex = this;
}
SynchronizedMap(Map m, Object mutex) {
this.m = m;
this.mutex = mutex;
} 可以看到默认锁的就是对象本身,效果和Hashtable其实是一样的。所以,一般情况下也是不推荐使用这个方法来保证线程安全。
ConcurrentHashMap
前面讲到的两个线程安全的Map集合框架,由于性能低下而不被推荐使用。ConcurrentHashMap就是来解决这个问题的。关于ConcurrentHashMap的详细内容,在深入解析ConcurrentHashMap:感受并发编程智慧 一文中已经有了具体的介绍,这里简单介绍一下ConcurrentHashMap的思路。
ConcurrentHashMap并不是和Hashtable一样采用直接对整个数组进行上锁,而是对数组上的一个节点上锁,这样如果并发访问的不是同个节点,那么就无需等待释放锁。如下图:

不同线程之间的访问不同的节点不互相干扰,提高了并发访问的性能。ConcurrentHashMap读取内容是不需要加锁的,所以实现了可以边写边读,多线程共读,提高了性能。
这是jdk1.8优化之后的设计结构,jdk1.7之前是分为多个小数组,锁的粒度比Hashtable稍小了一些。如下:
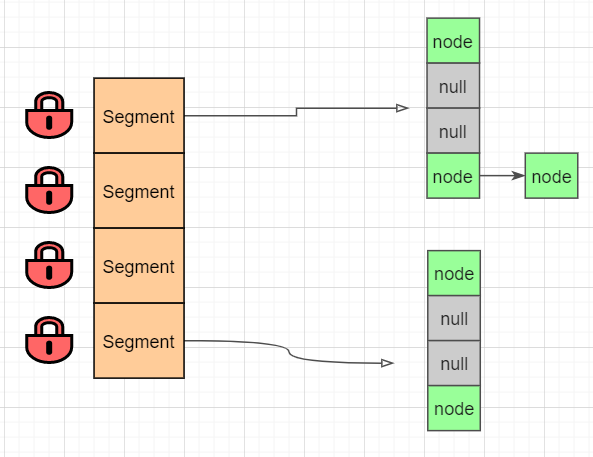
锁的是Segment,每个Segment对应一个数组。而jdk1.8之后锁的粒度进一步降低,性能也进一步提高了。
LinkedHashMap
HashMap是无法记住插入顺序的,在一些需要记住插入顺序的场景下,HashMap就显得无能为力,所以LinkHashMap就应运而生。LinkedHashMap内部新建一个内部节点类LinkedHashMapEntry继承自HashMap的Node,增加了前后指针。每个插入的节点,都会使用前后指针联系起来,形成一个链表,这样就可以记住插入的顺序,如下图:
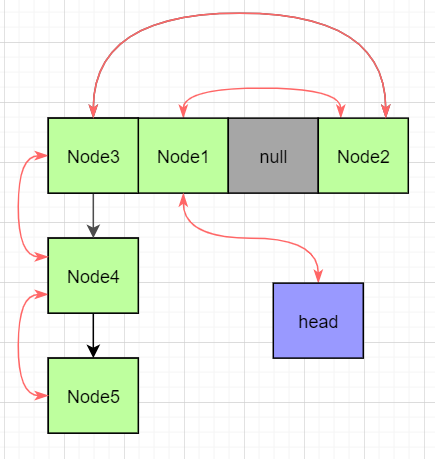
图中的红色线表示双向链表的引用。遍历时从head出发可以按照插入顺序遍历所有节点。
LinkedHashMap继承于HashMap,完全是基于HashMap进行改造的,在HashMap中就能看到LinkedMap的身影,如下:
HashMap.java
// Callbacks to allow LinkedHashMap post-actions
void afterNodeAccess(Node p) { }
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval(Node p) { } HashMap本身已经预留了接口给LinkedHashMap重写。LinkedHashMap本身的put、remove、get等等方法都是直接使用HashMap的方法。
LinkedHashMap的好处就是记住Node的插入顺序,当使用Iteractor遍历LinkedHashMap时,会按照Node的插入顺序遍历,HashMap则是按照数组的前后顺序进行遍历。
TreeMap
有没有发现前面两个集合框架的命名都是 xxHashMap,而TreeMap并不是,原因就在于TreeMap并不是散列表,只是实现了散列表的功能。
HashMap的key排列是无序的,hash函数把每个key都随机散列到数组中,而如果想要保持key有序,则可以使用TreeMap。TreeMap的继承结构如下:
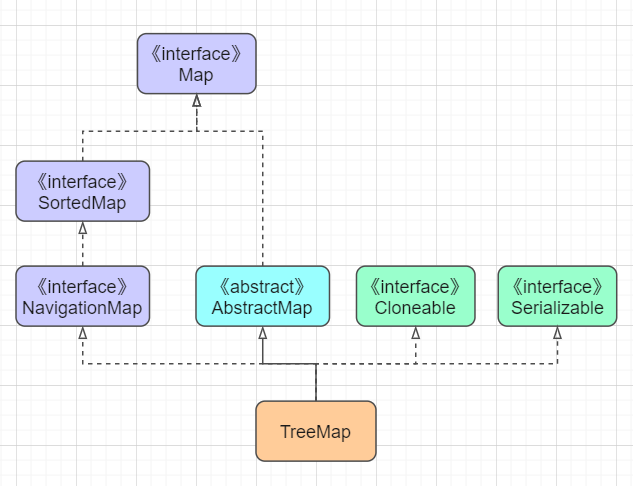
他继承自Map体系,实现了Map的接口,同时还实现了NavigationMap接口,该接口拓展了非常多的方便查找key的接口,如最大的key、最小的key等。
TreeMap虽然拥有映射表的功能,但是他底层并不是一个映射表,而是一个红黑树。他可以将key进行排序,但同时也失去了HashMap在常数时间复杂度下找到数据的优点,平均时间复杂度是O(logN)。所以若不是有排序的需求,常规情况下还是使用HashMap。
需要注意的是,TreeMap中的元素必须实现Comparable接口或者在TreeMap的构造函数中传入一个Comparator对象,他们之间才可以进行比较大小。
TreeMap本身的使用和特性是比较简单的,核心的重点在于他的底层数据结构:红黑树。这是一个比较复杂的数据结构,限于篇幅,笔者会在另外的文章中详解红黑树。
最后
文章详解了Hashtable这个旧版的集合框架,同时简单介绍了SynchronizeMap、ConcurrentHashMap、LinkedHashMap、TreeMap。这个类都在HashMap的基础功能上,拓展了一些新的特性,同时也带来一些性能上的代价。HashMap并没有称为功能的集大成者,而是把具体的特性分发到其他的Map实现类中,这样做得好处是,我们不需要在单线程的环境下却要付出线程安全的代价。所以了解这些相关Map实现类的特性以及付出的性能代价,则是我们学习的重点。
希望文章对你有帮助~
全文到此,原创不易,觉得有帮助可以点赞收藏评论关注转发。
笔者才疏学浅,有任何想法欢迎评论区交流指正。
如需转载请评论区或私信交流。另外欢迎光临笔者的个人博客:传送门