详解Redis核心数据结构和高性能原理分析(一)
文章目录
- 一、Redis介绍
-
- 1、Redis是什么
- 2、Redis的优缺点
- 二、Redis的安装(若需要docker版,请看我其他文章)
- 三、Redis 数据类型
-
- 1、string(字符串)
-
- 1.1、定义
- 1.2、常用命令
- 1.3、应用场景
- 2、list(链表)
-
- 2.1、定义
- 2.2、常用命令
- 2.1、应用场景
- 3、 Hash(hash表)
-
- 3.1、定义
- 3.2、常用命令
- 3.3、应用场景
- 3.4、优缺点
- 4、set(集合)
-
- 4.1、定义
- 4.2、常用命令
- 4.3、应用场景
- 5、zset(sorted set->有序集合)
-
- 5.1、定义
- 5.2、常用命令
- 5.3、应用场景
- 6、其他高级命令
- 四、基本数据结构总结
- 五、Redis的单线程和高性能
-
- 1、Redis是单线程吗?
- 2、Redis 单线程为什么还能这么快?
- 3、Redis 单线程如何处理那么多的并发客户端连接?
一、Redis介绍
1、Redis是什么
Remote Dictionary Server(Redis)是一个开源的使用 ANSI C 语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value 数据库,并提供多种语言的 API。
它通常被称为数据结构服务器,因为值(value)可以是 字符串(String), 哈希(Map),列表(list), 集合(sets) 和 有序集合(sorted sets)等类型。
2、Redis的优缺点
- 支持多种数据结构,如 string(字符串)、 list(双向链表)、dict(hash 表)、set(集合)、
zset(排序 set)、hyperloglog(基数估算)- 支持持久化操作,可以进行 aof 及 rdb 数据持久化到磁盘,从而进行数据备份或数
据恢复等操作,较好的防止数据丢失的手段。- 支持通过 Replication 进行数据复制,通过 master-slave 机制,可以实时进行数据的
同步复制,支持多级复制和增量复制,master-slave 机制是 Redis 进行 HA 的重要手段。- 单进程请求,所有命令串行执行,并发情况下不需要考虑数据一致性问题。
二、Redis的安装(若需要docker版,请看我其他文章)
redis安装
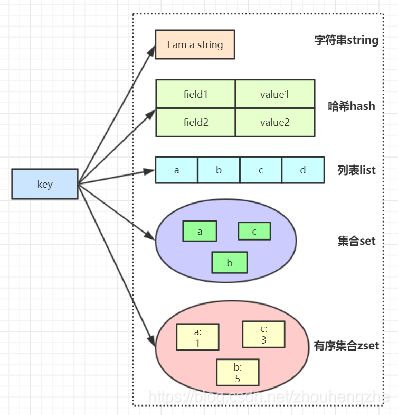
三、Redis 数据类型
总图:
1、string(字符串)
1.1、定义
Redis 字符串是字节序列。Redis 字符串是二进制安全的,这意味着他们有一个已知的
长度没有任何特殊字符终止,所以你可以存储任何东西,512 兆为上限
1.2、常用命令
字符串常用操作
SET key value //存入字符串键值对
MSET key value [key value ...] //批量存储字符串键值对
SETNX key value //存入一个不存在的字符串键值对
GET key //获取一个字符串键值
MGET key [key ...] //批量获取字符串键值
DEL key [key ...] //删除一个键
EXPIRE key seconds //设置一个键的过期时间(秒)
原子加减
INCR key //将key中储存的数字值加1
DECR key //将key中储存的数字值减1
INCRBY key increment //将key所储存的值加上increment
DECRBY key decrement //将key所储存的值减去decrement
1.3、应用场景
1、单值缓存
SET key value
GET key
2、分布式锁
SETNX product:10001 true //返回1代表获取锁成功
SETNX product:10001 true //返回0代表获取锁失败
。。。执行业务操作
DEL product:10001 //执行完业务释放锁
SET product:10001 true ex 10 nx //防止程序意外终止导致死锁
3、计数器
INCR article:readcount:{
文章id}
GET article:readcount:{
文章id}
4、Web集群session共享
spring session + redis实现session共享
5、分布式系统全局序列号
INCRBY orderId 1000 //redis批量生成序列号提升性能
6、对象缓存
1) SET user:1 value(json格式数据)
2) MSET user:1:name zhz user:1:balance 1888
MGET user:1:name user:1:balance
2、list(链表)
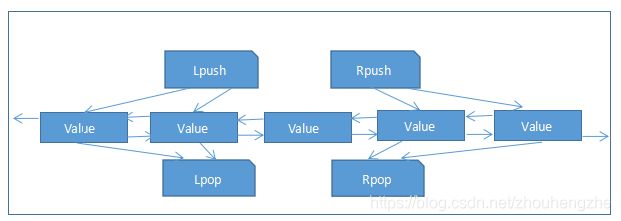
2.1、定义
Redis 的链表是简单的字符串列表,排序插入顺序。您可以添加元素到 Redis 的列表的
头部或尾部。
2.2、常用命令
1、List常用操作
LPUSH key value [value ...] //将一个或多个值value插入到key列表的表头(最左边)
RPUSH key value [value ...] //将一个或多个值value插入到key列表的表尾(最右边)
LPOP key //移除并返回key列表的头元素
RPOP key //移除并返回key列表的尾元素
LRANGE key start stop //返回列表key中指定区间内的元素,区间以偏移量start和stop指定
BLPOP key [key ...] timeout //从key列表表头弹出一个元素,若列表中没有元素,阻塞等待timeout秒,如果timeout=0,一直阻塞等待
BRPOP key [key ...] timeout //从key列表表尾弹出一个元素,若列表中没有元素,阻塞等待timeout秒,如果timeout=0,一直阻塞等待
2.1、应用场景
1、常用数据结构
Stack(栈) = LPUSH + LPOP
Queue(队列)= LPUSH + RPOP
Blocking MQ(阻塞队列)= LPUSH + BRPOP
2、微博和微信公号消息流
3、微博消息和微信公号消息
/**
* 事例
**/
A关注了MacTalk,备胎说车等大V
1)MacTalk发微博,消息ID为10018
LPUSH msg:{
A-ID} 10018
2)备胎说车发微博,消息ID为10086
LPUSH msg:{
A-ID} 10086
3)查看最新微博消息
LRANGE msg:{
A-ID} 0 4
3、 Hash(hash表)
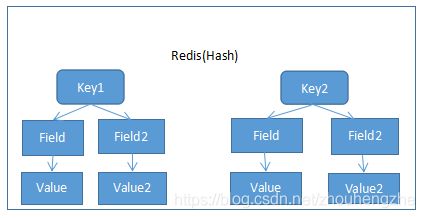
3.1、定义
Redis 的哈希是键值对的集合。 Redis 的哈希值是字符串字段和字符串值之间的映射,
因此它们被用来表示对象。
3.2、常用命令
Hash常用操作
HSET key field value //存储一个哈希表key的键值
HSETNX key field value //存储一个不存在的哈希表key的键值
HMSET key field value [field value ...] //在一个哈希表key中存储多个键值对
HGET key field //获取哈希表key对应的field键值
HMGET key field [field ...] //批量获取哈希表key中多个field键值
HDEL key field [field ...] //删除哈希表key中的field键值
HLEN key //返回哈希表key中field的数量
HGETALL key //返回哈希表key中所有的键值
HINCRBY key field increment //为哈希表key中field键的值加上增量increment
3.3、应用场景
对象缓存
HMSET user {
userId}:name zhz {
userId}:balance 1888
HMSET user 1:name zhz1:balance 1888
HMGET user 1:name 1:balance
电商购物车
1)以用户id为key
2)商品id为field
3)商品数量为value
购物车操作
添加商品->hset cart:1001 10088 1
增加数量->hincrby cart:1001 10088 1
商品总数->hlen cart:1001
删除商品->hdel cart:1001 10088
获取购物车所有商品->hgetall cart:1001
3.4、优缺点
- 优点
1)同类数据归类整合储存,方便数据管理
2)相比string操作消耗内存与cpu更小
3)相比string储存更节省空间- 缺点
过期功能不能使用在field上,只能用在key上
Redis集群架构下不适合大规模使用
4、set(集合)
4.1、定义
Redis 的集合是字符串的无序集合。

4.2、常用命令
1、Set常用操作
SADD key member [member ...] //往集合key中存入元素,元素存在则忽略,若key不存在则新建
SREM key member [member ...] //从集合key中删除元素
SMEMBERS key //获取集合key中所有元素
SCARD key //获取集合key的元素个数
SISMEMBER key member //判断member元素是否存在于集合key中
SRANDMEMBER key [count] //从集合key中选出count个元素,元素不从key中删除
SPOP key [count] //从集合key中选出count个元素,元素从key中删除
2、Set运算操作
SINTER key [key ...] //交集运算
SINTERSTORE destination key [key ..] //将交集结果存入新集合destination中
SUNION key [key ..] //并集运算
SUNIONSTORE destination key [key ...] //将并集结果存入新集合destination中
SDIFF key [key ...] //差集运算
SDIFFSTORE destination key [key ...] //将差集结果存入新集合destination中
4.3、应用场景
1、微信抽奖小程序
1)点击参与抽奖加入集合
SADD key {
userlD}
2)查看参与抽奖所有用户
SMEMBERS key
3)抽取count名中奖者
SRANDMEMBER key [count] / SPOP key [count]
2、微信微博点赞,收藏,标签
1) 点赞
SADD like:{
消息ID} {
用户ID}
2) 取消点赞
SREM like:{
消息ID} {
用户ID}
3) 检查用户是否点过赞
SISMEMBER like:{
消息ID} {
用户ID}
4) 获取点赞的用户列表
SMEMBERS like:{
消息ID}
5) 获取点赞用户数
SCARD like:{
消息ID}
3、集合操作
SINTER set1 set2 set3 -> {
c }
SUNION set1 set2 set3 -> {
a,b,c,d,e }
SDIFF set1 set2 set3 -> {
a }
4、集合操作实现微博微信关注模型
1) A关注的人:
ASet-> {
B, C}
2) D老师关注的人:
DSet--> {
A, E, B, C}
3) B老师关注的人:
BSet-> {
A, D, E, C, F)
4) 我A和D老师共同关注:
SINTER ASet DSet--> {
B, C}
5) 我A关注的人也关注他(D老师):
SISMEMBER BSet D
SISMEMBER CSet D
6) 我可能认识的人:
SDIFF DSet ASet->(A, E}
5、集合操作实现电商商品筛选
SADD brand:huawei P40
SADD brand:xiaomi mi-10
SADD brand:iPhone iphone12
SADD os:android P40 mi-10
SADD cpu:brand:intel P40 mi-10
SADD ram:8G P40 mi-10 iphone12
SINTER os:android cpu:brand:intel ram:8G -> {
P40,mi-10}
5、zset(sorted set->有序集合)
5.1、定义
Redis 的有序集合类似于 Redis 的集合,字符串不重复的集合。
5.2、常用命令
ZSet常用操作
ZADD key score member [[score member]…] //往有序集合key中加入带分值元素
ZREM key member [member …] //从有序集合key中删除元素
ZSCORE key member //返回有序集合key中元素member的分值
ZINCRBY key increment member //为有序集合key中元素member的分值加上increment
ZCARD key //返回有序集合key中元素个数
ZRANGE key start stop [WITHSCORES] //正序获取有序集合key从start下标到stop下标的元素
ZREVRANGE key start stop [WITHSCORES] //倒序获取有序集合key从start下标到stop下标的元素
Zset集合操作
ZUNIONSTORE destkey numkeys key [key ...] //并集计算
ZINTERSTORE destkey numkeys key [key …] //交集计算
5.3、应用场景
Zset集合操作实现排行榜
1)点击新闻
ZINCRBY hotNews:20190819 1 守护香港
2)展示当日排行前十
ZREVRANGE hotNews:20190819 0 9 WITHSCORES
3)七日搜索榜单计算
ZUNIONSTORE hotNews:20190813-20190819 7
hotNews:20190813 hotNews:20190814... hotNews:20190819
4)展示七日排行前十
ZREVRANGE hotNews:20190813-20190819 0 9 WITHSCORES
6、其他高级命令
1、keys:
全量遍历键, 用来列出所有满足特定正则字符串规则的key,当redis数据量比较大时,性能比较差,要避免使用
2、SCAN cursor [MATCH pattern] [COUNT count]
scan 参数提供了三个参数,第一个是 cursor 整数值(hash桶的索引值),第二个是 key 的正则模式,
第三个是一次遍历的key的数量(参考值,底层遍历的数量不一定),并不是符合条件的结果数量。第
一次遍历时,cursor 值为 0,然后将返回结果中第一个整数值作为下一次遍历的 cursor。一直遍历
到返回的 cursor 值为 0 时结束。
注意:但是scan并非完美无瑕, 如果在scan的过程中如果有键的变化(增加、 删除、 修改) ,那
么遍历效果可能会碰到如下问题: 新增的键可能没有遍历到, 遍历出了重复的键等情况, 也就是说
scan并不能保证完整的遍历出来所有的键,开发市需要考虑
3、Info:
查看redis服务运行信息,分为 9 大块,每个块都有非常多的参数,这 9 个块分别是:
4、Server
服务器运行的环境参数
5、Clients
客户端相关信息
6、Memory
服务器运行内存统计数据
7、Persistence
持久化信息
8、Stats
通用统计数据
9、Replication
主从复制相关信息
10、CPU CPU
使用情况
11、Cluster
集群信息
12、KeySpace
键值对统计数量信息
四、基本数据结构总结
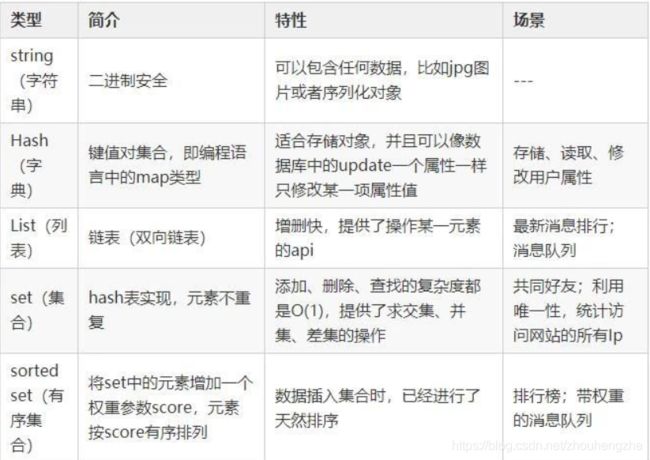
五、Redis的单线程和高性能
1、Redis是单线程吗?
Redis 的单线程主要是指 Redis 的网络 IO 和键值对读写是由一个线程来完成的,这也是 Redis 对外提供键值存储服务的主要流程。但 Redis 的其他功能,比如持久化、异步删除、集群数据同步等,其实是由额外的线程执行的。
2、Redis 单线程为什么还能这么快?
- 它所有的数据都在内存中,所有的运算都是内存级别的运算,而且单线程避免了多线程的切换性能损耗问题。因为 Redis 是单线程,所以要小心使用 Redis 指令,对于那些耗时的指令(比如
keys),一定要谨慎使用,一不小心就可能会导致 Redis 卡顿。- Redis完全基于内存,绝大部分请求是纯粹的内存操作,非常迅速,数据存在内存中。
- 数据结构简单,对数据操作也简单。
- 采用单线程,避免了不必要的上下文切换和竞争条件,不存在多线程导致的CPU切换,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有死锁问题导致的性能消耗。
- 使用多路复用IO模型,非阻塞IO。
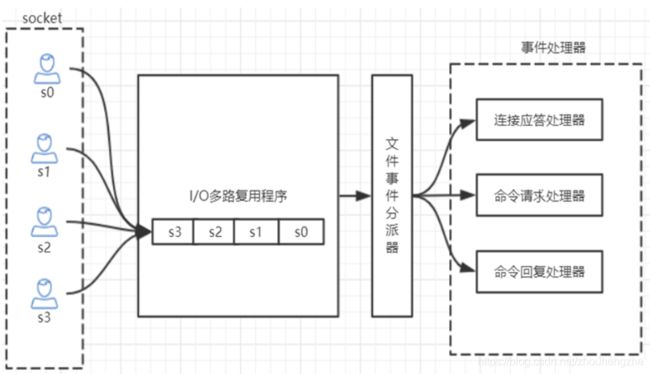
3、Redis 单线程如何处理那么多的并发客户端连接?
Redis的IO多路复用:redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,依次放到
文件事件分派器,事件分派器将事件分发给事件处理器。