云原生技术公开课学习笔记:Kubernetes核心概念、理解Pod和容器设计模式
一、Kubernetes核心概念
1、Kubernetes的核心功能
-
服务的发现与负载的均衡
-
容器的自动装箱,我们也会把它叫做scheduling,就是调度,把一个容器放到一个集群的某一个机器上,Kubernetes会帮助我们去做存储的编排,让存储的声明周期与容器的生命周期能有一个连接
-
Kubernetes会帮助我们去做自动化的容器的恢复。在一个集群中,经常会出现宿主机的问题或者说是OS的问题,导致容器本身的不可用,Kubernetes会自动地对这些不可用的容器进行恢复
-
Kubernetes会帮助我们去做应用的自动发布与应用的回滚,以及与应用相关的配置密文的管理
-
对于job类型任务,Kubernetes可以去做批量的执行
-
为了让这个集群、这个应用更富有弹性,Kubernetes也支持水平的伸缩
2、Kubernetes的架构
Kubernetes架构是一个比较典型的二层架构和server-client架构。Master作为中央的管控节点,会去与Node进行一个连接
所有UI的、clients这些user侧的组件,只会和Master进行连接,把希望的状态或者想执行的命令下发给Master,Master会把这些命令或者状态下发给相应的节点,进行最终的执行
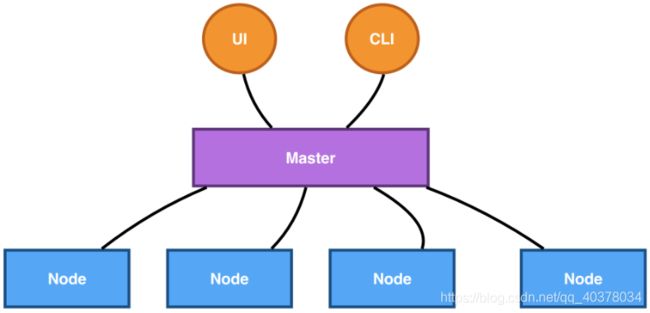
1)、Master
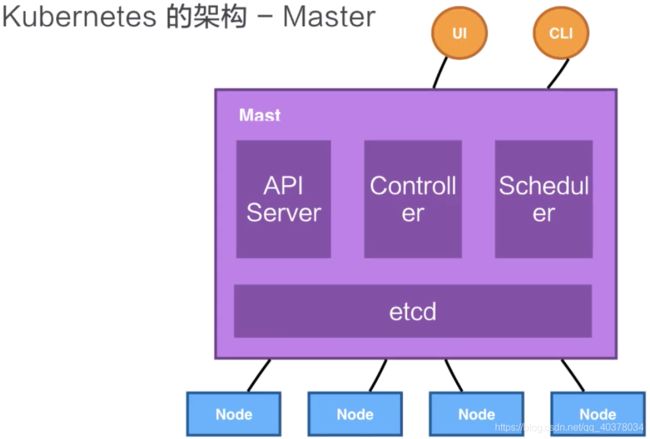
Kubernetes的Master包含四个主要的组件:API Server、Controller、Scheduler以及etcd
-
API Server:是用来处理API操作的,Kubernetes中所有的组件都会和API Server进行连接,组件与组件之间一般不进行独立的连接,都依赖于API Server进行消息的传送
-
Controller:是控制器,它用来完成对集群状态的一些管理。比如自动对容器进行修复、自动进行水平扩张,都是由Kubernetes中的Controller来进行完成的
-
Scheduler:是调度器,来完成调度的操作,比如一个用户提交的Container,依据它对CPU、对memory请求大小,找一台合适的节点,进行放置
-
etcd:是一个分布式的一个存储系统,API Server中所需要的这些原信息都被放置在etcd中,etcd本身是一个高可用系统,通过etcd保证整个Kubernetes的Master组件的高可用性
API Server本身在部署结构上是一个可以水平扩展的一个部署组件;Controller是一个可以进行热备的一个部署组件,它只有一个active,它的调度器也是相应的,虽然只有一个active,但是可以进行热备
2)、Node
Kubernetes的Node是真正运行业务负载的,每个业务负载会以Pod的形式运行。一个Pod中运行的一个或者多个容器,真正去运行这些Pod的组件的是叫做kubelet,也就是Node上最为关键的组件,它通过API Server接收到所需要Pod运行的状态,然后提交到Container Runtime组件中
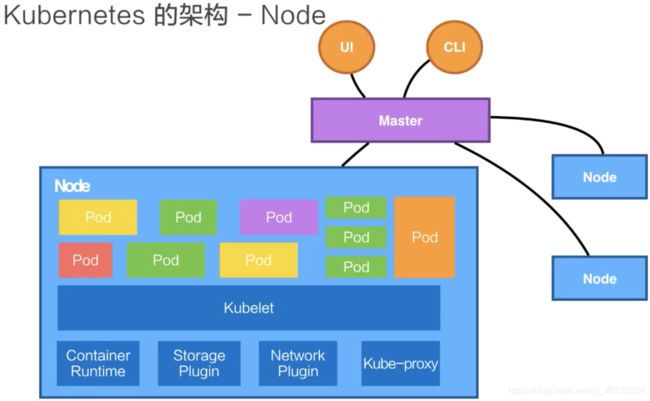
在OS上去创建容器所需要运行的环境,最终把容器或者Pod运行起来,也需要对存储和网络进行管理。Kubernetes并不会直接进行网络存储的操作,会靠Storage Plugin或者是Network Plugin来进行操作
在Kubernetes自己的环境中,也会有Kubernetes的Network,它是为了提供Service Network来进行搭网组网的。真正完成Service组网的组件的是Kube-proxy,它是利用了iptable的能力来进行组建Kubernetes的Network,就是Cluster Network
Kubernetes的Node并不会直接和user进行interaction,它的interaction只会通过Master。而User是通过Master向节点下发这些信息的。Kubernetes每个Node上,都会运行我们刚才提到的这几个组件
3)、Kubernetes的架构案例

用户通过UI或者CLI提交一个Pod给Kubernetes进行部署,这个Pod请求首先会通过CLI或者UI提交给Kubernetes API Server,下一步API Server会把这个信息写入到它的存储系统etcd,之后Scheduler会通过API Server的watch或者叫做notification 机制得到这个信息:有一个Pod需要被调度
这个时候Scheduler会根据它的内存状态进行一次调度决策,在完成这次调度之后,它会向API Server Report说:“OK!这个Pod需要被调度到某一个节点上。”
这个时候API Server接收到这次操作之后,会把这次的结果再次写到etcd中,然后API Server会通知相应的节点进行这次Pod真正的执行启动。相应节点的kubelet会得到这个通知,kubelet就会去调Container Runtime来真正去启动配置这个容器和这个容器的运行环境,去调度Storage Plugin来去配置存储,Network Plugin去配置网络
3、Kubernetes的核心概念
1)、Pod
Pod是Kubernetes的一个最小调度以及资源单元。用户可以通过Kubernetes的Pod API生产一个Pod,让Kubernetes对这个Pod进行调度,也就是把它放在某一个Kubernetes管理的节点上运行起来。一个Pod简单来说是对一组容器的抽象,它里面会包含一个或多个容器

比如上图中的Pod包含了两个容器,每个容器可以指定它所需要资源大小。比如说,一个核一个G,或者说0.5个核,0.5G
在这个Pod中也可以包含一些其他所需要的资源:比如Volume卷这个存储资源;比如说需要100个GB的存储或者20GB的另外一个存储
在Pod里面,也可以去定义容器所需要运行的方式。比如说运行容器的Command,以及运行容器的环境变量等等。Pod这个抽象也给这些容器提供了一个共享的运行环境,同一个Pod里的容器会共享同一个网络环境,这些容器可以用localhost来进行直接的连接。而Pod与Pod之间,是互相隔离的
2)、Volume
Volume就是卷的概念,它是用来管理Kubernetes存储的,是用来声明在Pod中的容器可以访问文件目录的,一个卷可以被挂载在Pod中一个或者多个容器的指定路径下面
而Volume本身是一个抽象的概念,一个Volume可以去支持多种的后端的存储。比如说Kubernetes的Volume就支持了很多存储插件,它可以支持本地的存储,可以支持分布式的存储

3)、Deployment
Deployment是在Pod这个抽象上更为上层的一个抽象,它可以定义一组Pod的副本数目、以及这个Pod的版本。一般用Deployment这个抽象来做应用的真正的管理,而Pod是组成Deployment最小的单元
Kubernetes是通过Controller,也就是控制器去维护Deployment中Pod的数目,它也会去帮助Deployment自动恢复失败的Pod
比如说可以定义一个Deployment,这个Deployment里面需要两个Pod,当一个Pod失败的时候,控制器就会监测到,它重新把Deployment中的Pod数目从一个恢复到两个,通过再去新生成一个Pod。通过控制器,也会帮助完成发布的策略。比如说进行滚动升级,进行重新生成的升级,或者进行版本的回滚

4)、Service
Service提供了一个或者多个Pod实例的稳定访问地址
比如一个Deployment可能有两个甚至更多个完全相同的Pod。对于一个外部的用户来讲,访问哪个Pod其实都是一样的,所以它希望做一次负载均衡,在做负载均衡的同时,我只想访问某一个固定的VIP,也就是Virtual IP地址,而不希望得知每一个具体的Pod的IP地址
而且这个Pod本身可能终止,如果一个Pod失败了,可能会换成另外一个新的。对一个外部用户来讲,提供了多个具体的Pod地址,这个用户要不停地去更新Pod地址,当这个Pod再失败重启之后,我们希望有一个抽象,把所有Pod的访问能力抽象成一个第三方的一个IP地址,实现这个的Kubernetes的抽象就叫Service
实现Service有多种方式,Kubernetes支持Cluster IP,上面也说到过Kuber-proxy的组网,它也支持nodePort、LoadBalancer等其他的一些访问的能力

5)、Namespace
Namespace是用来做一个集群内部的逻辑隔离的,它包括鉴权、资源管理等。Kubernetes的每个资源,比如Pod、Deployment、Service都属于一个Namespace,同一个Namespace中的资源需要命名的唯一性,不同的Namespace中的资源可以重名

6)、Kubernetes的API
Kubernetes API是由HTTP+JSON组成的:用户访问的方式是HTTP,访问的API中content的内容是JSON格式的
Kubernetes的kubectl也就是command tool,Kubernetes UI,或者有时候用curl,直接与Kubernetes进行沟通,都是使用HTTP+JSON这种形式
下面有个例子:比如说,对于这个Pod类型的资源,它的HTTP访问的路径,就是API,然后是apiVesion:V1,之后是相应的Namespaces,以及Pods资源,最终是Pod的名字

如果提交一个Pod,或者get一个Pod的时候,它的content内容都是用JSON或者是YAML表达的。上图中有个yaml的例子,在这个yaml file中,对Pod资源的描述也分为几个部分
第一个部分,一般来讲会是API的version。比如在这个例子中是V1,它也会描述我在操作哪个资源;比如说我的kind如果是pod,在Metadata中,就写上这个Pod的名字;比如nginx,我们也会给它打一些label。在Metadata中,有时候也会去写annotation,也就是对资源的额外的一些用户层次的描述
比较重要的一个部分叫做Spec,Spec也就是我们希望Pod达到的一个预期的状态。比如说它内部需要有哪些container被运行;比如说这里面有一个nginx的container,它的image是什么?它暴露的port是什么?
当我们从Kubernetes API中去获取这个资源的时候,一般来讲在Spec下面会有一个项目叫status,它表达了这个资源当前的状态;比如说一个Pod的状态可能是正在被调度、或者是已经running、或者是已经被terminates,就是被执行完毕了

刚刚在API之中,提到了一个metadata叫做label,这个label可以是一组键值对
比如上图的第一个pod中,label就可能是一个color等于red,即它的颜色是红颜色。当然也可以加其他label,比如说size:big就是大小,定义为大的,它可以是一组label
这些label是可以被selector,也就是选择器所查询的。类似于SQL中的select语句,比如上图中的三个Pod资源中,我们就可以进行select。select color等于red,就是它的颜色是红色的,可以看到,只有两个被选中了,因为只有他们的label是红色的,另外一个label中写的color等于yellow,也就是它的颜色是黄色,是不会被选中的
通过label,Kubernetes的API层就可以对这些资源进行一个筛选,那这些筛选也是Kubernetes对资源的集合所表达默认的一种方式
例如说,刚刚介绍的Deployment,它可能是代表一组的Pod,它是一组Pod的抽象,一组Pod就是通过label selector来表达的。当然我们刚才讲到说service对应的一组Pod,就是一个service要对应一个或者多个的Pod,来对它们进行统一的访问,这个描述也是通过label selector来进行select选取的一组Pod
4、demo
我使用的Kubernetes环境是Docker Desktop的Kubernetes,安装教程可以参考:https://github.com/AliyunContainerService/k8s-for-docker-desktop
这个demo主要包含三件事:
1)提交一个nginx-deployment
2)升级nginx-deployment
3)扩容nginx-deployment
利用kubectl来看一下这个集群中节选的状态,可以看到这个master的节点已经是running状态
hanxiantaodeMBP:yamls hanxiantao$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
docker-desktop Ready master 13d v1.19.3
看一下现在集群中Deployment这个资源
hanxiantaodeMBP:yamls hanxiantao$ kubectl get deployments
No resources found in default namespace.
可以看到集群中没有任何的Deployment,利用watch这个语义去看集群中Deployment这个资源的变化情况
hanxiantaodeMBP:~ hanxiantao$ kubectl get --watch deployments
首先先创建一个Deployment,Deployment的name是nginx-deployment,replicas数目是2,它的镜像版本是1.7.9
deployment.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name : nginx
image: nginx:1.7.9
ports:
- containerPort: 80
hanxiantaodeMBP:yamls hanxiantao$ kubectl apply -f deployment.yaml
deployment.apps/nginx-deployment created
hanxiantaodeMBP:~ hanxiantao$ kubectl get --watch deployments
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 0/2 0 0 0s
nginx-deployment 0/2 0 0 0s
nginx-deployment 0/2 0 0 0s
nginx-deployment 0/2 2 0 1s
nginx-deployment 1/2 2 1 40s
nginx-deployment 2/2 2 2 47s
describe一下现在的Deployment的状态,有一个nginx-deployment已经被生成了,它的replicas数目也是我们想要的、selector也是我们想要的、它的image的版本也是1.7.9
hanxiantaodeMBP:yamls hanxiantao$ kubectl describe deployment nginx-deployment
Name: nginx-deployment
Namespace: default
CreationTimestamp: Sun, 20 Dec 2020 14:42:17 +0800
Labels:
Annotations: deployment.kubernetes.io/revision: 1
Selector: app=nginx
Replicas: 2 desired | 2 updated | 2 total | 2 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx:1.7.9
Port: 80/TCP
Host Port: 0/TCP
Environment:
Mounts:
Volumes:
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets:
NewReplicaSet: nginx-deployment-5d59d67564 (2/2 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 2m48s deployment-controller Scaled up replica set nginx-deployment-5d59d67564 to 2
下面去升级这个Deployment版本,image的版本从1.7.9升级到1.8
deployment-update.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name : nginx
image: nginx:1.8
ports:
- containerPort: 80
hanxiantaodeMBP:yamls hanxiantao$ kubectl apply -f deployment-update.yaml
deployment.apps/nginx-deployment configured
hanxiantaodeMBP:~ hanxiantao$ kubectl get --watch deployments
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 0/2 0 0 0s
nginx-deployment 0/2 0 0 0s
nginx-deployment 0/2 0 0 0s
nginx-deployment 0/2 2 0 1s
nginx-deployment 1/2 2 1 40s
nginx-deployment 2/2 2 2 47s
nginx-deployment 2/2 2 2 5m24s
nginx-deployment 2/2 2 2 5m24s
nginx-deployment 2/2 0 2 5m24s
nginx-deployment 2/2 1 2 5m24s
nginx-deployment 3/2 1 3 5m58s
nginx-deployment 2/2 1 2 5m59s
nginx-deployment 2/2 2 2 5m59s
nginx-deployment 3/2 2 3 6m2s
nginx-deployment 2/2 2 2 6m2s
通过discribe看到所有Pod的版本都被更新了,可以看到这个image的版本由1.7.9真正更新到了1.8
hanxiantaodeMBP:yamls hanxiantao$ kubectl describe deployment nginx-deployment
Name: nginx-deployment
Namespace: default
CreationTimestamp: Sun, 20 Dec 2020 14:42:17 +0800
Labels:
Annotations: deployment.kubernetes.io/revision: 2
Selector: app=nginx
Replicas: 2 desired | 2 updated | 2 total | 2 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx:1.8
Port: 80/TCP
Host Port: 0/TCP
Environment:
Mounts:
Volumes:
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets:
NewReplicaSet: nginx-deployment-64c9d67564 (2/2 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 7m deployment-controller Scaled up replica set nginx-deployment-5d59d67564 to 2
Normal ScalingReplicaSet 96s deployment-controller Scaled up replica set nginx-deployment-64c9d67564 to 1
Normal ScalingReplicaSet 62s deployment-controller Scaled down replica set nginx-deployment-5d59d67564 to 1
Normal ScalingReplicaSet 61s deployment-controller Scaled up replica set nginx-deployment-64c9d67564 to 2
Normal ScalingReplicaSet 58s deployment-controller Scaled down replica set nginx-deployment-5d59d67564 to 0
最后给Deployment做水平扩张,replicas数目从2改成了4
deployment-scale.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 4
template:
metadata:
labels:
app: nginx
spec:
containers:
- name : nginx
image: nginx:1.8
ports:
- containerPort: 80
hanxiantaodeMBP:yamls hanxiantao$ kubectl apply -f deployment-scale.yaml
deployment.apps/nginx-deployment configured
hanxiantaodeMBP:~ hanxiantao$ kubectl get --watch deployments
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 0/2 0 0 0s
nginx-deployment 0/2 0 0 0s
nginx-deployment 0/2 0 0 0s
nginx-deployment 0/2 2 0 1s
nginx-deployment 1/2 2 1 40s
nginx-deployment 2/2 2 2 47s
nginx-deployment 2/2 2 2 5m24s
nginx-deployment 2/2 2 2 5m24s
nginx-deployment 2/2 0 2 5m24s
nginx-deployment 2/2 1 2 5m24s
nginx-deployment 3/2 1 3 5m58s
nginx-deployment 2/2 1 2 5m59s
nginx-deployment 2/2 2 2 5m59s
nginx-deployment 3/2 2 3 6m2s
nginx-deployment 2/2 2 2 6m2s
nginx-deployment 2/4 2 2 8m38s
nginx-deployment 2/4 2 2 8m38s
nginx-deployment 2/4 2 2 8m38s
nginx-deployment 2/4 4 2 8m38s
nginx-deployment 3/4 4 3 8m40s
nginx-deployment 4/4 4 4 8m40s
再一次describe一下当前集群中的deployment的情况,可以看到它的replicas的数目从2变到了4
hanxiantaodeMBP:yamls hanxiantao$ kubectl apply -f deployment-scale.yaml
deployment.apps/nginx-deployment configured
hanxiantaodeMBP:yamls hanxiantao$ kubectl describe deployment nginx-deployment
Name: nginx-deployment
Namespace: default
CreationTimestamp: Sun, 20 Dec 2020 14:42:17 +0800
Labels:
Annotations: deployment.kubernetes.io/revision: 2
Selector: app=nginx
Replicas: 4 desired | 4 updated | 4 total | 4 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx:1.8
Port: 80/TCP
Host Port: 0/TCP
Environment:
Mounts:
Volumes:
Conditions:
Type Status Reason
---- ------ ------
Progressing True NewReplicaSetAvailable
Available True MinimumReplicasAvailable
OldReplicaSets:
NewReplicaSet: nginx-deployment-64c9d67564 (4/4 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 8m51s deployment-controller Scaled up replica set nginx-deployment-5d59d67564 to 2
Normal ScalingReplicaSet 3m27s deployment-controller Scaled up replica set nginx-deployment-64c9d67564 to 1
Normal ScalingReplicaSet 2m53s deployment-controller Scaled down replica set nginx-deployment-5d59d67564 to 1
Normal ScalingReplicaSet 2m52s deployment-controller Scaled up replica set nginx-deployment-64c9d67564 to 2
Normal ScalingReplicaSet 2m49s deployment-controller Scaled down replica set nginx-deployment-5d59d67564 to 0
Normal ScalingReplicaSet 13s deployment-controller Scaled up replica set nginx-deployment-64c9d67564 to 4
最后,利用delete操作把刚才生成的Deployment给删除掉
hanxiantaodeMBP:yamls hanxiantao$ kubectl delete deployment nginx-deployment
deployment.apps "nginx-deployment" deleted
hanxiantaodeMBP:yamls hanxiantao$ kubectl get deployments
No resources found in default namespace.
二、理解Pod和容器设计模式
1、为什么需要Pod
1)、容器的基本概念

容器的本质实际上是一个进程,是一个视图被隔离,资源受限的进程
容器里面PID=1的进程就是应用本身,这意味着管理虚拟机等于管理基础设施,因为我们是在管理机器,但管理容器却等于直接管理应用本身。这也是之前说过的不可变基础设施的一个最佳体现,这个时候,你的应用就等于你的基础设施,它一定是不可变的
如果说Kubernetes是云时代的操作系统,以此类推,容器镜像就是这个操作系统的软件安装包
2)、真实操作系统里的例子

有一个程序叫做Helloworld,这个Helloworld程序实际上是由一组进程组成的,需要注意一下,这里说的进程实际上等同于Linux中的线程
因为Linux中的线程是轻量级进程,所以如果从Linux系统中去查看Helloworld中的pstree,将会看到这个Helloworld实际上是由四个线程组成的,分别是{ api、main、log、compute}。也就是说,四个这样的线程共同协作,共享Helloworld程序的资源,组成了Helloworld程序的真实工作情况
在真实的操作系统里面,一个程序往往是根据进程组来进行管理的。Kubernetes把它类比为一个操作系统,比如说Linux。针对于容器我们前面提到可以类比为进程,就是前面的Linux线程。那么Pod又是什么呢?实际上Pod就是我们刚刚提到的进程组,也就是Linux里的线程组
3)、进程组概念

Helloworld程序由四个进程组成,这些进程之间会共享一些资源和文件。那么现在有一个问题:假如说现在把Helloworld程序用容器跑起来,你会怎么去做?
解法一:
启动一个Docker容器,里面运行4个进程。那么这种情况下容器里面PID=1的进程是谁?比如说是main进程,那么谁又负责去管理剩余的3个进程呢?
这个问题的核心在于容器的设计本身是一种单进程模型,由于容器的应用等于进程,所以只能去管理PID=1的这个进程,其他再起来的进程其实是处于托管状态的。所以说服务应用进程本身就具有进程管理的能力
解法二:
直接把容器里PID=1的进程直接改成systemd,否则这个容器是没有办法去管理很多个进程的。因为PID=1进程是应用本身,如果现在把这个PID=1的进程给kill了,或者它自己运行过程中死掉了,那么剩下三个进程的资源就没有人回收了
而反过来真的把这个应用本身改成了systemd,或者在容器里面运行了一个systemd,将会导致另外一个问题:使得管理容器,不再是管理应用本身了,而等于是管理systemd,这里的问题就非常明显了。比如说我这个容器里面run的程序或者进程是systemd,那么接下来,这个应用是不是退出了?是不是fail了?是不是出现异常失败了?实际上是没办法直接知道的,因为容器管理的是systemd
Linux容器的单进程模型,指的是容器的生命周期等同于PID=1的进程(容器应用进程)的生命周期,而不是说容器里不能创建多进程。当然,一般情况下,容器应用进程并不具备进程管理能力,所以你通过exec或者ssh在容器里创建的其他进程,一旦异常退出(比如ssh终止)是很容易变成孤儿进程的
4)、Pod=进程组

在Kubernetes里面,Pod实际上正是Kubernetes抽象出来的一个可以类比为进程组的概念
由四个进程共同组成的一个应用Helloworld,在Kubernetes里面,实际上会被定义为一个拥有四个容器的Pod
就是说现在有四个职责不同、相互协作的进程,需要放在容器里去运行,在Kubernetes里面并不会把它们放到一个容器里,Kubernetes会把四个独立的进程分别用四个独立的容器启动起来,然后把它们定义在一个Pod里面
所以当Kubernetes把Helloworld给拉起来的时候,实际上会看到四个容器,它们共享了某些资源,这些资源都属于Pod,所以我们说Pod 在Kubernetes里面只有一个逻辑单位,没有一个真实的东西对应说这个就是Pod。真正起来在物理上存在的东西,就是四个容器。这四个容器,或者说是多个容器的组合就叫做Pod
Pod是Kubernetes分配资源的一个单位,因为里面的容器要共享某些资源,所以Pod也是Kubernetes的原子调度单位
5)、为什么Pod必须是原子调度单位?

假如现在有两个容器,它们是紧密协作的,所以它们应该被部署在一个Pod里面。具体来说,第一个容器叫做App,就是业务容器,它会写日志文件;第二个容器叫做LogCollector,它会把刚刚App容器写的日志文件转发到后端的ElasticSearch中
两个容器的资源需求是这样的:App容器需要1G内存,LogCollector需要0.5G内存,而当前集群环境的可用内存是这样一个情况:Node_A:1.25G内存、Node_B:2G内存
假如说现在没有Pod概念,就只有两个容器,这两个容器要紧密协作、运行在一台机器上。可是,如果调度器先把App调度到了Node_A上面,接下来会怎么样呢?这时会发现:LogCollector实际上是没办法调度到Node_A上的,因为资源不够。其实此时整个应用本身就已经出问题了,调度已经失败了,必须去重新调度
在Kubernetes里,就直接通过Pod这样一个概念去解决了。因为在Kubernetes里,这样的一个App容器和LogCollector容器一定是属于一个Pod的,它们在调度时必然是以一个Pod为单位进行调度,所以这个问题是根本不存在的
6)、再次理解Pod

Pod里面的容器是超亲密关系,大概分为以下几类:
- 比如说两个进程之间会发生文件交换,前面提到的例子就是这样,一个写日志,一个读日志
- 两个进程之间需要通过localhost或者说是本地的Socket去进行通信,这种本地通信也是超亲密关系
- 这两个容器或者是微服务之间,需要发生非常频繁的RPC调用,出于性能的考虑,也希望它们是超亲密关系
- 两个容器或者是应用,它们需要共享某些Linux Namespace。最简单常见的一个例子,就是我有一个容器需要加入另一个容器的Network Namespace。这样我就能看到另一个容器的网络设备,和它的网络信息
2、Pod的实现机制
1)、共享网络

比如说现在有一个Pod,其中包含了一个容器A和一个容器B,它们两个就要共享Network Namespace。在Kubernetes里的解法是这样的:它会在每个Pod里,额外起一个Infra container小容器来共享整个Pod的Network Namespace
Infra container是一个非常小的镜像,大概100~200KB左右,是一个汇编语言写的、永远处于暂停状态的容器。由于有了这样一个Infra container之后,其他所有容器都会通过Join Namespace的方式加入到Infra container的Network Namespace中
所以说一个Pod里面的所有容器,它们看到的网络视图是完全一样的。即:它们看到的网络设备、IP地址、Mac地址等等,跟网络相关的信息,其实全是一份,这一份都来自于Pod第一次创建的这个Infra container。这就是Pod解决网络共享的一个解法
在Pod里面,一定有一个IP地址,是这个Pod的Network Namespace对应的地址,也是这个Infra container的IP地址。所以大家看到的都是一份,而其他所有网络资源,都是一个Pod一份,并且被Pod中的所有容器共享。这就是Pod的网络实现方式
由于需要有一个相当于说中间的容器存在,所以整个Pod里面,必然是Infra container第一个启动。并且整个Pod的生命周期是等同于Infra container的生命周期的,与容器A和B是无关的。这也是为什么在Kubernetes里面,它是允许去单独更新Pod里的某一个镜像的,即:做这个操作,整个Pod不会重建,也不会重启
2)、共享存储

比如说现在有两个容器,一个是Nginx,另外一个是非常普通的容器,在Nginx里放一些文件,让我能通过Nginx访问到。所以它需要去share这个目录。我share文件或者是share目录在Pod里面是非常简单的,实际上就是把volume变成了Pod level。然后所有容器,就是所有同属于一个Pod的容器,他们共享所有的volume
比如说上图的例子,这个volume叫做shared-data,它是属于Pod level的,所以在每一个容器里可以直接声明:要挂载shared-data这个volume,只要你声明了你挂载这个volume,你在容器里去看这个目录,实际上大家看到的就是同一份。这个就是Kubernetes通过Pod来给容器共享存储的一个做法
所以在之前的例子中,应用容器App写了日志,只要这个日志是写在一个volume中,只要声明挂载了同样的volume,这个volume就可以立刻被另外一个LogCollector容器给看到。以上就是Pod实现存储的方式
3、详解容器设计模式
1)、举例
比如,现在要发布一个应用,这个应用是Java写的,有一个war包需要把它放到Tomcat的web APP目录下面,这样就可以把它启动起来了。可是像这样一个war包或Tomcat这样一个容器的话,怎么去做,怎么去发布?

-
方法一:可以把war包和Tomcat打包放进一个镜像里面。但是这样带来一个问题,无论是要更新war包还是要更新Tomcat,都要重新做一个新的镜像,这是比较麻烦的
-
第二种方式:就是镜像里面只打包Tomcat。它就是一个Tomcat,但是需要使用数据卷的方式,比如说hostPath,从宿主机上把war包挂载进Tomcat容器中,挂到web APP目录下面,这样把这个容器启用起来之后,里面就能用了。这样做的问题是需要维护一套分布式存储系统。因为这个容器可能第一次启动是在宿主机A上面,第二次重新启动就可能跑到B上去了,容器它是一个可迁移的东西,它的状态是不保持的。所以必须维护一套分布式存储系统,使容器不管是在A还是在B上,都可以找到这个war包,找到这个数据
2)、InitContainer

在上图的yaml里,首先定义一个Init Container,它只做一件事情,就是把war包从镜像里拷贝到一个Volume里面,它做完这个操作就退出了,所以Init Container会比用户容器先启动,并且严格按照定义顺序来依次执行
然后,这个关键在于刚刚拷贝到的这样一个目的目录:APP目录,实际上是一个Volume。而一个Pod里面的多个容器,它们是可以共享Volume的,所以现在这个Tomcat容器,只是打包了一个Tomcat镜像。但在启动的时候,要声明使用APP目录作为我的Volume,并且要把它们挂载在web APP目录下面
而这个时候,由于前面已经运行过了一个Init Container,已经执行完拷贝操作了,所以这个Volume里面已经存在了应用的war包:就是sample.war。等到第二步执行启动这个Tomcat容器的时候,去挂这个Volume,一定能在里面找到前面拷贝来的sample.war
所以可以这样去描述:这个Pod就是一个自包含的,可以把这一个Pod在全世界任何一个Kubernetes上面都顺利启用起来。不用担心没有分布式存储、Volume不是持久化的,它一定是可以公布的
所以这是一个通过组合两个不同角色的容器,并且按照这样一些像Init Container这样一种编排方式,统一的去打包这样一个应用,把它用Pod来去做的非常典型的一个例子。像这样的一个概念,在Kubernetes里面就是一个非常经典的容器设计模式,叫做Sidecar
3)、容器设计模式:Sidecar
什么是Sidecar?就是说其实在Pod里面,可以定义一些专门的容器,来执行主业务容器所需要的一些辅助工作
这种做法一个非常明显的优势就是在于其实将辅助功能从我的业务容器解耦了,所以能够独立发布Sidecar容器,并且更重要的是这个能力是可以重用的,即同样的一个监控Sidecar或者日志Sidecar,可以被全公司的人共用的
1)Sidecar:应用与日志收集

应用日志收集,业务容器将日志写在一个Volume里面,而由于Volume在Pod里面是被共享的,所以日志容器——即Sidecar容器一定可以通过共享该Volume,直接把日志文件读出来,然后存到远程存储里面,或者转发到另外一个例子。现在业界常用的Fluentd日志进程或日志组件,基本上都是这样的工作方式
2)Sidecar:代理容器

假如现在有个Pod需要访问一个外部系统,或者一些外部服务,但是这些外部系统是一个集群,那么这个时候如何通过一个统一的、简单的方式,用一个IP地址,就把这些集群都访问到?有一种方法就是:修改代码。因为代码里记录了这些集群的地址;另外还有一种解耦的方法,即通过Sidecar代理容器
简单说,单独写一个这么小的Proxy,用来处理对接外部的服务集群,它对外暴露出来只有一个IP地址就可以了。所以接下来,业务容器主要访问Proxy,然后由Proxy去连接这些服务集群,这里的关键在于Pod里面多个容器是通过localhost直接通信的,因为它们同属于一个network Namespace,网络视图都一样,所以它们俩通信localhost,并没有性能损耗
所以说代理容器除了做了解耦之外,并不会降低性能,更重要的是,像这样一个代理容器的代码就又可以被全公司重用了
3)Sidecar:适配器容器

比如,现在业务容器暴露出来的监控接口是/metrics,访问这个这个容器的metrics的这个URL就可以拿到了。可是现在,这个监控系统升级了,它访问的URL是/health,我只认得暴露出health健康检查的URL,才能去做监控,metrics不认识。那这个怎么办?那就需要改代码了,但可以不去改代码,而是额外写一个Adapter,用来把所有对health的这个请求转发给metrics就可以了,所以这个Adapter对外暴露的是health这样一个监控的URL,这就可以了
这样的关键还在于Pod之中的容器是通过localhost直接通信的,所以没有性能损耗,并且这样一个Adapter容器可以被全公司重用起来
课程地址:https://edu.aliyun.com/roadmap/cloudnative?spm=5176.11399608.aliyun-edu-index-014.4.dc2c4679O3eIId#suit