kafka
kafka基本概念
一、名词解释
1.1 消息队列(Message Queue)
Message Queue消息传送系统提供传送服务。消息传送依赖于大量支持组件,这些组件负责处理连接服务、消息的路由和传送、持久性、安全性以及日志记录。消息服务器可以使用一个或多个代理实例。
JMS(Java Messaging Service)是Java平台上有关面向消息中间件(MOM)的技术规范,它便于消息系统中的Java应用程序进行消息交换,并且通过提供标准的产生、发送、接收消息的接口简化企业应用的开发,翻译为Java消息服务。
1.2 MQ消息模型

1.3 MQ消息队列分类
消息队列分类:点对点和发布/订阅两种:
1、点对点:
消息生产者生产消息发送到queue中,然后消息消费者从queue中取出并且消费消息。
消息被消费以后,queue中不再有存储,所以消息消费者不可能消费到已经被消费的消息。Queue支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
2、发布/订阅:
消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到topic的消息会被所有订阅者消费。
1.4 MQ消息队列对比
1、RabbitMQ:支持的协议多,非常重量级消息队列,对路由(Routing),负载均衡(Loadbalance)或者数据持久化都有很好的支持。
2、ZeroMQ:号称最快的消息队列系统,尤其针对大吞吐量的需求场景,擅长的高级/复杂的队列,但是技术也复杂,并且只提供非持久性的队列。
3、ActiveMQ:Apache下的一个子项,类似ZeroMQ,能够以代理人和点对点的技术实现队列。
4、Redis:是一个key-Value的NOSql数据库,但也支持MQ功能,数据量较小,性能优于RabbitMQ,数据超过10K就慢的无法忍受。
1.5 Kafka简介
Kafka是分布式发布-订阅消息系统,它最初由 LinkedIn 公司开发,使用 Scala语言编写,之后成为 Apache 项目的一部分。在Kafka集群中,没有“中心主节点”的概念,集群中所有的服务器都是对等的,因此,可以在不做任何配置的更改的情况下实现服务器的的添加与删除,同样的消息的生产者和消费者也能够做到随意重启和机器的上下线。
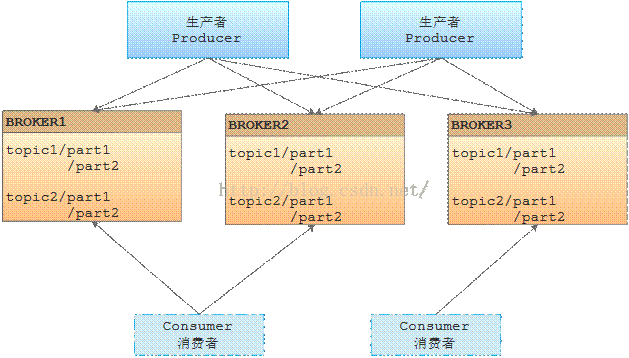
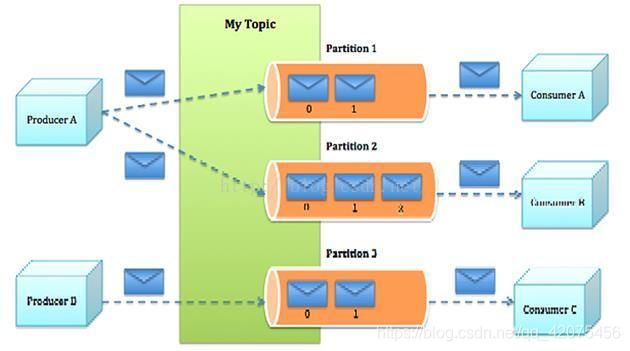
1.6 Kafka术语介绍
1、消息生产者:即:Producer,是消息的产生的源头,负责生成消息并发送到Kafka服务器上。
2、消息消费者:即:Consumer,是消息的使用方,负责消费Kafka服务器上的消息。
3、主题:即:Topic,由用户定义并配置在Kafka服务器,用于建立生产者和消息者之间的订阅关系:生产者发送消息到指定的Topic下,消息者从这个Topic下消费消息。
4、消息分区:即:Partition,一个Topic下面会分为很多分区,例如:“kafka-test”这个Topic下可以分为6个分区,分别由两台服务器提供,那么通常可以配置为让每台服务器提供3个分区,假如服务器ID分别为0、1,则所有的分区为0-0、0-1、0-2和1-0、1-1、1-2。Topic物理上的分组,一个 topic可以分为多个 partition,每个 partition 是一个有序的队列。partition中的每条消息都会被分配一个有序的 id(offset)。
5、Broker:即Kafka的服务器,用户存储消息,Kafa集群中的一台或多台服务器统称为 broker。
6、消费者分组:Group,用于归组同类消费者,在Kafka中,多个消费者可以共同消息一个Topic下的消息,每个消费者消费其中的部分消息,这些消费者就组成了一个分组,拥有同一个分组名称,通常也被称为消费者集群。
7、Offset:消息存储在Kafka的Broker上,消费者拉取消息数据的过程中需要知道消息在文件中的偏移量,这个偏移量就是所谓的Offset。
1.7 Kafka中Broker
1、Broker:即Kafka的服务器,用户存储消息,Kafa集群中的一台或多台服务器统称为 broker。
2、Message在Broker中通Log追加的方式进行持久化存储。并进行分区(patitions)。
3、为了减少磁盘写入的次数,broker会将消息暂时buffer起来,当消息的个数(或尺寸)达到一定阀值时,再flush到磁盘,这样减少了磁盘IO调用的次数。
4、Broker没有副本机制,一旦broker宕机,该broker的消息将都不可用。Message消息是有多份的。
5、Broker不保存订阅者的状态,由订阅者自己保存。
6、无状态导致消息的删除成为难题(可能删除的消息正在被订阅),kafka采用基于时间的SLA(服务水平保证),消息保存一定时间(通常为7天)后会被删除。
7、消息订阅者可以rewind back到任意位置重新进行消费,当订阅者故障时,可以选择最小的offset(id)进行重新读取消费消息。
1.8 Kafka的Message组成
1、Message消息:是通信的基本单位,每个 producer 可以向一个 topic(主题)发布一些消息。
2、Kafka中的Message是以topic为基本单位组织的,不同的topic之间是相互独立的。每个topic又可以分成几个不同的partition(每个topic有几个partition是在创建topic时指定的),每个partition存储一部分Message。
3、partition中的每条Message包含了以下三个属性:
offset 即:消息唯一标识:对应类型:long
MessageSize 对应类型:int32
data 是message的具体内容。
1.9 Kafka的Partitions分区
1、Kafka基于文件存储.通过分区,可以将日志内容分散到多个server上,来避免文件尺寸达到单机磁盘的上限,每个partiton都会被当前server(kafka实例)保存。
2、可以将一个topic切分多任意多个partitions,来消息保存/消费的效率。
3、越多的partitions意味着可以容纳更多的consumer,有效提升并发消费的能力。
1.10 Kafka的Consumers
1、消息和数据消费者,订阅 topics并处理其发布的消息的过程叫做 consumers。
2、在 kafka中,我们可以认为一个group是一个“订阅者”,一个Topic中的每个partions,只会被一个“订阅者”中的一个consumer消费,不过一个 consumer可以消费多个partitions中的消息(消费者数据小于Partions的数量时)。注意:kafka的设计原理决定,对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,否则将意味着某些consumer将无法得到消息。
3、一个partition中的消息只会被group中的一个consumer消费。每个group中consumer消息消费互相独立。
1.11 Kafka的持久化
1、一个Topic可以认为是一类消息,每个topic将被分成多partition(区),每个partition在存储层面是append log文件。任何发布到此partition的消息都会被直接追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),partition是以文件的形式存储在文件系统中。
2、Logs文件根据broker中的配置要求,保留一定时间后删除来释放磁盘空间。
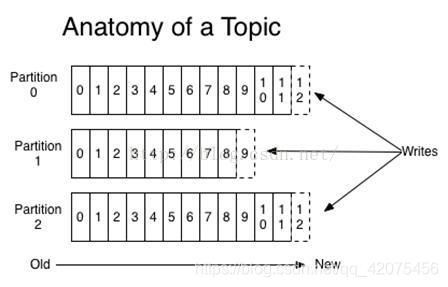
Partition:
Topic物理上的分组,一个 topic可以分为多个 partition,每个 partition 是一个有序的队列。partition中的每条消息都会被分配一个有序的 id(offset)。
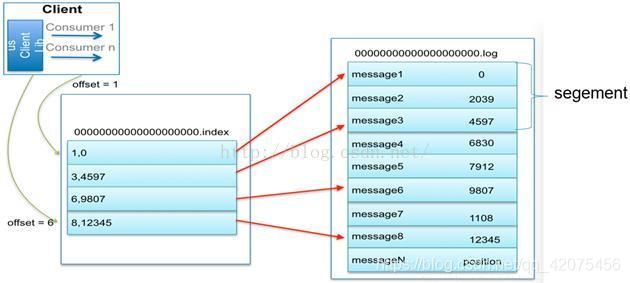
3、为数据文件建索引:稀疏存储,每隔一定字节的数据建立一条索引。下图为一个partition的索引示意图:
二、kafka拓扑结构
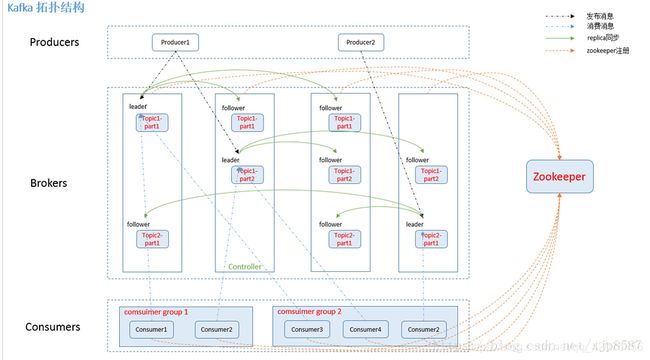
如图所示,kafka主要由三部分组成,producer、broker和consumer。由于kafka需要将状态存放于zookeeper中,故kafka集群由kafka broker和zookeeper集群构成。
以topic和partition维度来看,broker有两种角色:leader和follower。对于每一个topic+partition,都有一个leader和多个follower,leader负责主要数据读写操作,而follower则是不断从leader同步数据。
而对于整个kafka集群来看,有一个broker会成为controller,controller会和zk进行通信,获取整个集群的情况。kafka集群上任何的变化,如topic的增删、broker的增删等,会由zk来发现,并通知集群的controller,由controller来通知集群上的其他节点。且当kafka集群新来一个节点时,首先先与zk进行通信,查看kafka集群是否存在controller,如果存在,则将该节点成为broker,如果无,则会抢占式去成为controller。
三、消息的生产和消费
消息的生产:消息的生产者,等消息满足一个批次时(例如1000条消息),将消息一起推入kafka集群,会去找对应的topic下每个partition的leader,将数据写入。这里在写入时,还会传一个参数(ack)过去,标明什么情况下返回成功。
当ack=0时,只要生产者向kafka集群写入数据,就会返回成功,不管数据是否真的写入成功。
ack=1时,当partition的leader写入成功,则集群向生产者返回写入成功。
ack=-1时,生产者先向partition的leader写入数据,当leader写入成功,由leader向follower写入数据,当follower数据都写入完成后,则返回数据写入成功。该模式下,数据的可靠性最高。
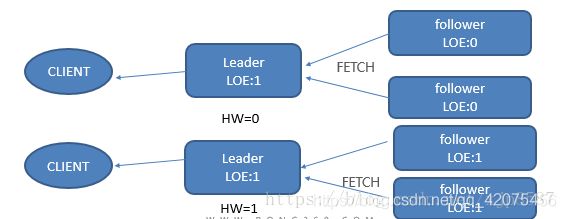
消息在broker的存储:
kafka本质上是以磁盘作为介质存储数据,每个broker存储数据时,是以在磁盘上顺序写入的方式,所以其写入数据较快。由于数据存储在磁盘上,会造成磁盘不断变大情况,这里我们可以设定(log.retention.hours)数据删除日期,例如设定7天前的数据删除。
消息的消费:
消费者采取pull的方式去partition的leader上拿取数据,并自己维护一个offset值(一个连续的用于定位被追加到分区的每一个消息的序列号,最大值为64位的long大小)。不会同步到zookeeper上。但是为了kafka manager能够方便的监控,一般也会手动的同步到zookeeper上。这样的好处是一旦读取某个message的consumer失败了,这条message的offsite我们自己维护,我们不会+1。下次再启动的时候,还会从这个offsite开始读。这样可以做到exactly once对于数据的准确性有保证。
broker宕机情况:
Kafka之所以称之为分布式的高可用消息队列,是因为它的每个topic+partition都有多个副本,正常情况,client只从leader读写消息,但当leader宕机时,kafka会自动切换leader到新的机器上。
Broker停止时,zk会自动删除/brokers/ids/n,controller会检测到节点的删除。
如果宕机的broker只属于任何topic+partition的follower,controller的操作比较简单,只更新当前集群的存活broker列表,并发送给所有机器( UPDATE_METADATA )。
如果宕机的broker属于某个topic+partition的leader,controller会有一个重新选举的过程,从当前isr列表中重新选举一个leader,发送LEADER_AND_ISR给新的leader和follower,并且发送UPDATE_METADATA 给所有机器。
可见,如果某一topic在建立时设置的副本数为1的话,leader宕机就不可用了。
生产消息时如果ack!=-1,可能导致消息发送给leader后,follower尚未同步,此时leader宕机,消息也就丢失了。
副本数>1 且ack ==-1可以保证消息一定不丢失。
安装
一、安装zookeeper
*1.*单机安装
1.1 Linux环境,下载安装包命令:
wget http://www.apache.org/dist/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
注意事项:可先在 http://www.apache.org/dist/zookeeper 查看当前zk的版本有哪些,选择合适的版本进行下载。
1.2 解压
tar zxvf zookeeper-3.4.14.tar.gz
1.3 创建数据和日志目录
mkdir -p /data/zookeeper/data
mkdir -p /data/zookeeper/log
1.4 创建服务启动配置文件
cd zookeeper-3.4.14/conf
touch zoo.cfg
使用vi命令打开zoo.cfg,将以下内容复制到此文件并保存
# The number of milliseconds of each tick
# 这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳,单位毫秒。
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
# 这个配置项是用来配置 Zookeeper 接受客户端(这里所说的客户端不是用户连接 Zookeeper 服务器的客户端,而是 Zookeeper 服务器集群中连接到 Leader 的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过 5个心跳的时间(也就是 tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 5*2000=10 秒
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
# 这个配置项标识 Leader 与 Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是 2*2000=4 秒
syncLimit=5
# the directory where the snapshot is stored.
# Zookeeper 保存数据的目录
dataDir=/data/zookeeper/data
# Zookeeper保存日志的目录
dataLogDir=/data/zookeeper/log
# the port at which the clients will connect
# 这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
# 最大客户端连接数
maxClientCnxns=10240
# The number of snapshots to retain in dataDir
# 数据目录里保存的快照数
autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
# 删除快照的时间间隔,单位:小时
autopurge.purgeInterval=1
1.5 启动zk服务
cd到zk安装目录bin目录下
[root@localhost bin]# ./zkServer.sh start
*2.*集群安装
对于每台机器,分别在zoo.cfg配置文件中末尾加入以下内容
server.1=192.168.xxx.1:2888:3888
server.2=192.168.xxx.2:2888:3888
server.3=192.168.xxx.3:2888:3888
参数说明:
server.A=B:C:D:其中 A 是一个数字,表示这个是第几号服务器;B 是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
创建节点识别文件:
分别在每台机器存取数据的目录dataDir下创建名为myid的文件:
cd /data/zookeeper/data
touch myid
各自myid文件中的输入内容为配置文件中server.A对应的A的值。本文中即分别为1,2,3
验证集群:
分别启动各机器上的zk服务,任意机器输入以下命令即可:
./zkCli.sh -server 192.168.xxx.1:2181
./zkCli.sh -server 192.168.xxx.2:2181
./zkCli.sh -server 192.168.xxx.3:2181
根据返回信息判断是否成功。
查看主从信息
./zkServer.sh status
[root@localhost bin]# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /zookeeper-3.4.14/bin/../conf/zoo.cfg
Mode: follower
Mode: follower表示当前zk服务为从,Mode: leader表示当前zk服务为主。
二、安装kafka
*1.*单机安装
1. 安装 kafka 步骤
- 安装包准备
wget http://mirror.bit.edu.cn/apache/kafka/2.2.0/kafka_2.12-2.2.0.tgz1.2
- 解压缩
tar zxvf kafka_2.12-2.2.0.tgz
- 创建日志目录
mkdir -p /data/kafka-logs
2. 配置
listeners=PLAINTEXT://192.xxx.xxx.1:9092 #本机ip,不要用localhost和127.0.0.1
num.io.threads=8 #io线程数
log.dirs=/data/kafka-logs #kafka消息数据存放目录
auto.create.topics.enable=false #不能自动创建主题
zookeeper.connect=192.xxx.xxx.1:2181,192.xxx.xxx.2:2181,192.xxx.xxx.3:2181 #zk集群信息
启动服务,应先启动配置的zk集群的所有服务
bin/kafka-server-start.sh config/server.properties &
*2.*集群安装
1.集群搭建
集群配置,每台机器分别修改server.properties,以192.xxx.xxx.1为例,修改以下内容
broker.id=1 #整数,不要与集群中其他broker.id重复,可以用ip最后一个字段
listeners=PLAINTEXT://192.xxx.xxx.1:9092 #本机ip,不要用localhost和127.0.0.1
num.io.threads=8 #io线程数
log.dirs=/data/kafka-logs #kafka消息数据存放目录
num.partitions=6 #每个topic的默认log划分数,一般为节点数乘以2
log.retention.hours=168 #日志保留时长,一般为7天
auto.create.topics.enable=true
delete.topic.enable=true
default.replication.factor=2
zookeeper.connect=192.xxx.xxx.1:2181,192.xxx.xxx.2:2181,192.xxx.xxx.3:2181 #zk集群信息
分别修改另外2台机器的kafka,区别在于 broker.id 和 listeners的ip配置。
启动服务,按照单机中的启动服务方法,分别启动3台机器上的kafka。
2.验证集群
- 创建主题与查看主题
在 192.xxx.xxx.1 上创建topic,到 kafka 安装 bin 目录下
cd /usr/local/kafka_2.12-2.2.0/bin
创建名为 TEST_TOPIC 的主题
./kafka-topics.sh --create --zookeeper 192.xxx.xxx.1:2181 --replication-factor 2 --partitions 3 --topic TEST_TOPIC
可在 192.xxx.xxx.2 上查看主题
./kafka-topics.sh --describe --zookeeper 192.xxx.xxx.1:2181 --topic TEST_TOPIC
- 发送消息与接收消息
在 192.xxx.xxx.1 上发送消息,将消息发送到集群
./kafka-console-producer.sh --broker-list 192.xxx.xxxx.1:9092,192.xxx.xxxx.2:9092,192.xxx.xxxx.3:9092 --topic TEST_TOPIC
在 192.xxx.xxx.2 上接收来自 192.xxx.xxx.1 的主题为 TEST_TOPIC 的消息
./kafka-console-consumer.sh --bootstrap-server 192.xxx.xxxx.1:9092 --topic TEST_TOPIC --from-beginning
springboot集成kafka的使用
一、pom文件
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.1.6.RELEASEversion>
<relativePath/>
parent>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
<dependency>
<groupId>org.springframework.kafkagroupId>
<artifactId>spring-kafkaartifactId>
<version>2.2.0.RELEASEversion>
dependency>
<dependency>
<groupId>com.google.code.gsongroupId>
<artifactId>gsonartifactId>
<version>2.8.2version>
dependency>
dependencies>
二、application.yml
server:
port: 8099
spring:
kafka:
# kafka服务器IP地址,可以多个
bootstrap-servers: 10.1.28.215:9092
consumer:
# 此消费者所属消费者组的唯一标识。如果消费者用于订阅或offset管理策略的组管理功能,则此属性是必须的。
group-id: test-1
# 指定消息key和消息体的编解码方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
producer:
# 指定消息key和消息体的编解码方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-deserializer: org.apache.kafka.common.serialization.StringSerializer
# 每次批量发送消息的数量
batch-size: 65536
# 生产者用来缓存等待发送到服务器的消息的内存总字节数。如果消息发送比可传递到服务器的快,生产者将阻塞max.block.ms之后,抛出异常。此设置应该大致的对应生产者将要使用的总内存,但不是硬约束,因为生产者所使用的所有内存都用于缓冲。一些额外的内存将用于压缩(如果启动压缩),以及用于保持发送中的请求。
buffer-memory: 524288
三、生产者
@Component
public class KafkaProducer {
private static Logger logger = LoggerFactory.getLogger(KafkaProducer.class);
@Autowired
private KafkaTemplate kafkaTemplate;
private Gson gson = new GsonBuilder().create();
//发送消息方法
public void send() {
for (int i = 0; i < 5; i++) {
Message message = new Message();
message.setId(System.currentTimeMillis());
message.setMsg(UUID.randomUUID().toString() + "---" + i);
message.setSendTime(new Date());
kafkaTemplate.send("hello", gson.toJson(message));
logger.info("发送消息 ----->>>>> message = {}", gson.toJson(message));
}
}
}
四、消费者
@Component
public class KafkaReceiver {
private static Logger logger = LoggerFactory.getLogger(KafkaReceiver.class);
//topics可以配置多个topic
@KafkaListener(topics = {
"hello"})
public void listen(ConsumerRecord<?, ?> record) {
Optional<?> kafkaMessage = Optional.ofNullable(record.value());
if (kafkaMessage.isPresent()) {
Object message = kafkaMessage.get();
logger.info("----------------- record =" + record);
logger.info("------------------ message =" + message);
}
logger.info("----------------- record =" + record);
}
}