one-class svm单分类器使用初尝试
ocsvm单分类器使用
每部分代码都有注释,较为详尽了都能看懂。代码可见于开源中国ocsvm的讲解博客,其他很多站也能搜到,看起来还是比较直观步骤也比较清晰,核心的步骤都有,于是就挨个查了一下。
最终做了几个小地方的修改,主要是测试数据和数据个数的调整。
先说下目标,比如你一堆数据是一堆点很多坐标,都是正常数据(图中白色)利用其作为训练集,再有一些测试集的数据(有正样本(图中紫色)和负样本(图中黄色)),利用训练出的模型判定测试集样本是否为正常数据。
这和CNN就有差别了,CNN每个训练样本都有标签,知道哪些正样本哪些负样本,但两种样本数量相对均衡。这里就不均衡了,拿到的全是正样本需要找到异常数据,这就可以称之为异常检测(AD)。
看下这段代码,从结果看,输出的图片是散点图配上两类等高线,填充的等高线是判定区域之外的部分,红色(偏红那个,其实不是红色)部分是判定是否是异常数据的平面,也就是所谓的根据训练得到的分界线。
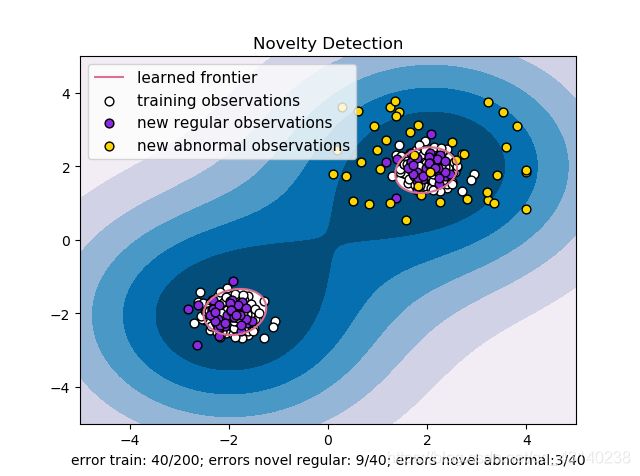
代码如下
'''
ocsvm1
'''
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.font_manager
from sklearn import svm
# linespace(start,end,num)在start和end之间均匀间隔生成的num个数
# meshgrid生成网格点坐标矩阵,xx,yy = np.meshgrid(x,y),xx与yy一一对应坐标数据
# 如xx,yy = np.meshgrid(x,y) x = [0,1,2] y = [0,1] xx = [[0,1,2],[0,1,2]] yy = [[0,0,0],[1,1,1]]
# xx和yy用于画等高线
xx, yy = np.meshgrid(np.linspace(-5, 5, 500), np.linspace(-5, 5, 500))
# Generate train data
# np.random.randn(d1,d2,...,dn),与np.random.rand(d1,d2,...,dn)生成[0,1)范围内的数据相似
# np.random.randn()符合标准正态分布N(0,1)以0为均值1为标准差,d均为生成数据的维度
X = 0.3 * np.random.randn(200, 2)
Y = 0.3 * np.random.randn(40, 2)
# np.r_连接 [1,2,3] [4,5,6] => [1,2,3,4,5,6]
# 此处[2±0.3,2±0.3]与[-2±0.3,-2±0.3]连接
X_train = np.r_[X + 2, X - 2]
X_test = np.r_[Y + 2, Y - 2]
# Generate some abnormal novel observations
# np.random.uniform在[low,high)范围内生成size格式的数据
X_outliers = np.random.uniform(low=0.1, high=4, size=(40, 2))
# fit the model
clf = svm.OneClassSVM(nu=0.1, kernel='rbf', gamma=0.1)
# 分别在(-2,-2)和(2,2)周围的两部分点
clf.fit(X_train)
# 返回每个点的预测结果
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
y_pred_outliers = clf.predict(X_outliers)
# 统计每个部分的异常个数
n_error_train = y_pred_train[y_pred_train == -1].size
n_error_test = y_pred_test[y_pred_test == -1].size
n_error_outlier = y_pred_outliers[y_pred_outliers == 1].size
# plot the line , the points, and the nearest vectors to the plane
# ravel()转化为一维数据,len(Z)=250000
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
# 拆分为500个,len(Z)=500
Z = Z.reshape(xx.shape)
# 绘图
plt.title("Novelty Detection")
# 等高线(填充用contourf)
# (Z.min(), 0]间生成7个数 level为数组 0在最中心处
# 判定超球面边缘等高线为Z.max(),第二个等高线a在Z.max()出画,非填充
plt.contourf(xx, yy, Z, levels=np.linspace(Z.min(), 0, 7), cmap=plt.cm.PuBu)
a = plt.contour(xx, yy, Z, levels=[0, Z.max()], colors='palevioletred')
# 散点图绘制
# plt.scatter(x数组,y数组,颜色,大小,边界颜色)
s =40
b1 = plt.scatter(X_train[:, 0], X_train[:, 1], c='white', s=s, edgecolors='k')
b2 = plt.scatter(X_test[:, 0], X_test[:, 1], c='blueviolet', s=s, edgecolors='k')
c = plt.scatter(X_outliers[:, 0], X_outliers[:, 1], c='gold', s=s, edgecolors='k')
# 设置坐标轴
plt.axis('tight')
plt.xlim((-5, 5))
plt.ylim((-5, 5))
# 设置图片标签
plt.legend([a.collections[0], b1, b2, c],
["learned frontier", 'training observations',
"new regular observations", "new abnormal observations"],
loc="upper left",
prop=matplotlib.font_manager.FontProperties(size=11))
# 设置文字标签
plt.xlabel(
"error train: %d/200; errors novel regular: %d/40; errors novel abnormal:%d/40"%(
n_error_train, n_error_test, n_error_outlier) )
plt.show()
这里的数据主要构成为三类:
- 第一类训练集,训练集数据是
X = 0.3 * np.random.randn(200, 2)
X_train = np.r_[X + 2, X - 2]
也就是(2±0.3,2±0.3)和(-2±0.3,-2±0.3)范围内的200个
- 第二类测试集正样本,该数据为
Y = 0.3 * np.random.randn(40, 2)
X_test = np.r_[Y + 2, Y - 2]
同理就是(2±0.3,2±0.3)和(-2±0.3,-2±0.3)范围内的40个
特别要注意的是理论上来说,如果测试集足够多,应该是非常贴近于训练集最终的错误比例的(毕竟数据都是一样的来的,画的点不一样而已)
- 第三类测试集负样本,测试集负样本
X_outliers = np.random.uniform(low=0.1, high=4, size=(40, 2))
其实就是0.1-4之间的,实际上是比较靠近(2±0.3,2±0.3)范围的一堆点,这里其实也就能发现,负样本集里也不全是负样本,这个根据实际数据的情况来决定,本身数据也肯定有一定的误差,这很符合实际情况。
这段代码里如果你需要替换成自己的数据(二维),应该换掉这部分
X = 0.3 * np.random.randn(200, 2)
Y = 0.3 * np.random.randn(40, 2)
至于最后统计结果部分改一下总样本个数就行。
得到数据以后就是训练、预测、统计、绘图。每一步都详细说明在注释中。
感谢阅读。希望共同进步,如有问题感谢指正。
参考的源代码来源:https://my.oschina.net/u/4353161/blog/4524087
感谢原作者。