NLP笔记:word2vec简单考察
- NLP笔记:word2vec简单考察
- 1. 简介
- 2. word2vec原理介绍
- 3. gensim实现
- 4. tensorflow实现
- 1. cbow方式
- 2. skip gram方式
- 3. 直接生成方式
- 4. 结论
- 5. pytorch实现
- 1. cbow方式
- 2. skip gram方式
- 6. 总结
- 7. 参考链接
1. 简介
word2vec是nlp之中蛮老的一个技术了,讲道理工作了两年多也基本没有用过这个玩意,除了刚开始工作的时候用了一下之后后面基本就是直接训练了。
word2vec顾名思义,其实就是将word从id转换至一个embedding向量,算是一个比较原始的迁移学习方式,从大量的无标注数据中训练出词向量,然后迁移至其他学习任务当中,可以更好地对词向量进行表达。
在早期的nlp任务当中,像是ner啊或者pos等任务当中,我们往往缺乏足够多的标注数据(事实上现在这部分标注数据也不多),因此我们往往会希望通过其他方式预先学习到一些词向量信息,这样就可以减轻模型整体的学习难度,进而优化模型的整体效果。
其中,关于word2vec一个比较有代表性的工作就是glove词向量。
但是当数据量本身足够时,这种方式就显得有些没有必要,更不要说后面以bert为代表的预训练语言模型的出现之后,word2vec技术就显得太过粗糙也没有必要了。
事实上,就笔者个人所知,从18年底之后似乎也就基本再没有在听到过什么相关的工作了。
但无论如何,作为一种早期的预训练词向量技术,这里还是可以来稍微复习一下的,实在不行用来熟练一下tensorflow以及pytorch的coding技术也是可以的
2. word2vec原理介绍
如前所述,word2vec的本质是无监督地将词学习为一个词向量,即做一个id到vector的映射,有点类似于图片的转换生成模型,先将图片通过一个encoder转换为一个表征向量,然后再通过一个decoder重新恢复为一张图片。
同样的,word2vec的训练方式也是相仿,首先将词汇的通过一个embedding层变换为向量表达,然后再尝试对其进行还原为one_hot形式的词汇id。
根据具体的训练方式不同,他们又主要分为以下两种训练方式:
- cbow训练方式
- 通过前后的token来学习目标token;
- skip_gram训练方式
- 通过当前的token来学习其前后的token;
不过我其实蛮好奇的,为啥不直接预测其本身呢?就是说,我直接输入n个词,将其转换回其本身不就结了?于是我也跑去做了一下实验,结果果然不理想。
后来仔细想了想也是,如果单纯就是那样计算的话,就变成了这样:
X ⋅ A ⋅ B = Y X \cdot A \cdot B = Y X⋅A⋅B=Y
其中, X X X为输入的句子,其中每一行都是一个one_hot向量,而 Y Y Y是恢复得到的目标矩阵,目标就是要令 Y Y Y尽可能等于 X X X。
我们考察 Y Y Y中的任意一个元素 y i j y_{ij} yij,则有:
y i j = ∑ α ∑ β x i α ⋅ a α β ⋅ b β j y_{ij} = \sum_{\alpha}\sum_{\beta}x_{i\alpha}\cdot a_{\alpha\beta} \cdot b_{\beta j} yij=α∑β∑xiα⋅aαβ⋅bβj
很显然,他并没有用到其他词汇的信息,因此,我们无法学习到词与词之间的相关性。
唉,只能说,经典果然是有经典的理由的。
3. gensim实现
gensim是一个开源的机器学习相关的工具库,其中包含了word2vec的训练。
因此,我们这里首先介绍一下使用gensim进行word2vec的训练方法。
首先,需要将数据处理为如下格式:
元芳 你 怎么 看 ?
数据文件中单行为一句话,每句话分好词之后词与词之间使用空格进行分隔。
我们令训练数据为train.txt,则我们可以快速地给出模型训练脚本如下:
from gensim.models import word2vec
sentences = word2vec.LineSentence("data/train.txt")
model = word2vec.Word2Vec(sentences, size=100)
model.save("model/word2vec.model")
三行代码的事,简单的不能再简单。
不过,如果使用gensim进行word2vec的训练的话倒是可以很方便的获取与某个词最为关联的几个词,其代码实现如下:
from gensim.models import word2vec
word2vec_model = word2vec.Word2Vec.load("model/word2vec.model")
word2vec_model.predict_output_word("花果山", topn=5)
不过,倒是好像没有办法直接获取某个词的embedding结果。
4. tensorflow实现
现在,我们来使用tensorflow来自行实现以下word2vec的模型训练。
根据训练策略的不同,我们分别给出cbow和skip gram方式的代码demo如下。
为了更好地进行形象化地说明,我们设置embedding_size=2,这样,我们就可以直接在二维图表中将结果进行呈现了。
这里所有的代码我们都已经放到我的GitHub仓库当中了,这里,我们就只给出我们的实验结果进行说明。
1. cbow方式
我们给出使用cbow方式训练word2vec模型前后的embedding结果如下图所示:
- 训练前
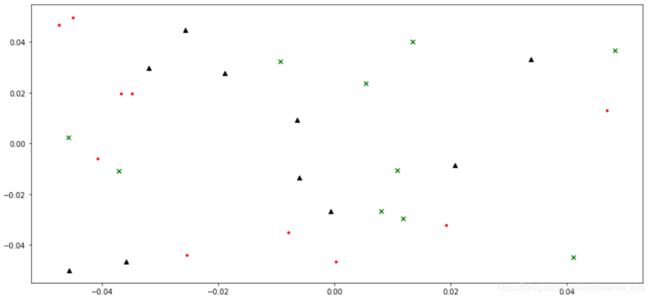
- 训练后

可以看到:
- 在embedding维度为两维的情况下,输出结果并没有呈现较好的团聚效果;
- 但是明显可以看到,词汇的分布间确实受到了训练的影响产生了聚合的现象。
2. skip gram方式
同样的,我们给出skip gram方式下的tensorflow实验结果如下:
- 训练前

- 训练后

可以看到,其结果与上述使用cbow方式训练得到的实验结果相仿。
3. 直接生成方式
另一方面,上面我们理论分析了一下是否可以通过直接预测的方式进行词向量的训练,得到结果如下:
- 训练前

- 训练后
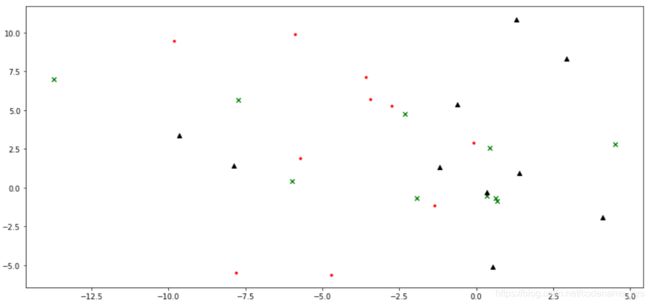
可以看到:
- 和我们的理论分析相一致,训练前后词的embedding结果并没有显示出团聚特性,词和词之间的相似性信息完全没有学习到。
4. 结论
我们整理结论如下:
- 结论而言,在二维情况下,当前并没有很好的学习到词与词之间的相似性信息,这方面的原因可能有很多,包括:
- 可能由于二维情况本来就不太足以表达复杂的词相似性信息;
- 可能由于我们当前给出的训练数据量不足(毕竟我们在数据处理过程中为了图快每个句子中只取用了一个窗口的数据,导致使用的信息量其实很少);
- 可能由于我们的窗口选择不合理,窗口太短一些本应该有关联性的词并没有出现在一个窗口当中;
- ……
- 但是,我们确实又看到模型的embedding结果之间出现了团聚的特性,说明我们当前的代码实现确实是正确的;
- 此外,我们还对直接进行word2vec训练的方式进行了测试,发现其效果确实和我们的理论分析相一致,无法学习到词汇间的关联信息。
5. pytorch实现
同样的,我们给出pytorch的代码实验结果如下。
1. cbow方式
给出cbow方式的模型训练结果如下:
- 训练前

- 训练后

可以看到:
- 我们使用pytorch进行cbow方式的word2vec训练,得到的结果与tensorflow是基本一致的。
不过这其实也是一个正常的结论,毕竟归根究底,tensorflow以及pytorch不过是两个高度封装的数学工具罢了,只要调整好相应的初始参数和运算方法,其结果本就应该是一致的。
2. skip gram方式
同样的,我们给出使用pytorch进行的skip gram方式下的word2vec模型训练结果如下:
- 训练前

- 训练后

同样的,其结果与之前的结果相一致。
6. 总结
这里,我们简单的回顾了一下word2vec的概念以及训练方式,并在tensorflow以及pytorch框架下分别进行了代码实现,并进行了一些简单的实验,其相关的代码全部位于我们的GitHub仓库当中。
为了保证我们结果的直观性,我们定义word的embedding维度为2,结果而言我们观察到了embedding的聚合,但是词和词之间的关联性方面并没有很好的结果表达,这方面还可以进行更多的实验考察,但这里暂时就不进行更深的展开了。
另一方面,在pytorch的代码实验当中,由于对pytorch的不熟悉,也是踩了不少的坑,包括:
- pytorch与tensorflow在参数初始化时的默认值不一致的情况;
- pytorch与tensorflow在cross entropy loss定义上的参数以及功能不完全一致的情况;
- pytorch对于GPU的使用方法;
- ……
其中,有关问题二,我们已经在我们的另一篇博客(NLP笔记:浅谈交叉熵(cross entropy))当中进行了一定的讨论,更多的内容大约后面会挑选一些有意思的在其他的博客中相应的进行一些整理,这里暂时就不多做展开了。
7. 参考链接
- 如何通俗理解word2vec
- [NLP] 秒懂词向量Word2vec的本质
- 一篇通俗易懂的word2vec
- word2vec是如何得到词向量的?
- https://github.com/RaRe-Technologies/gensim/tree/release-3.8.3
- https://github.com/zake7749/word2vec-tutorial