NLP(二十八)多标签文本分类
本文将会讲述如何实现多标签文本分类。
什么是多标签分类?
在分类问题中,我们已经接触过二分类和多分类问题了。所谓二(多)分类问题,指的是y值一共有两(多)个类别,每个样本的y值只能属于其中的一个类别。对于多标签问题而言,每个样本的y值可能不仅仅属于一个类别。
举个简单的例子,我们平时在给新闻贴标签的时候,就有可能把一篇文章分为经济和文化两个类别。因此,多标签问题在我们的日常生活中也是很常见的。
对于多标签问题,业界还没有很成熟的解决方法,主要是因为标签之间可能会存在复杂的依赖关系,这种依赖关系现阶段还没有成熟的模型来解决。我们在解决多标签问题的时候,一种办法是认为标签之间互相独立,然后把该问题转化为我们熟悉的二(多)分类问题。
本文以 2020语言与智能技术竞赛:事件抽取任务 中的数据作为多分类标签的样例数据,借助多标签分类模型来解决。
整个项目的结构如下图所示:
首先,让我们来看一下样例数据。
数据分析
首先,让我们来看一下样例数据的几个例子:
司法行为-起诉|组织关系-裁员 最近,一位前便利蜂员工就因公司违规裁员,将便利蜂所在的公司虫极科技(北京)有限公司告上法庭。
组织关系-裁员 思科上海大规模裁员人均可获赔100万官方澄清事实
组织关系-裁员 日本巨头面临危机,已裁员1000多人,苹果也救不了它!
组织关系-裁员|组织关系-解散 在硅谷镀金失败的造车新势力们:蔚来裁员、奇点被偷窃、拜腾解散
从上面的例子中我们可以看出,同样的描述文本,有可能会属于多个事件类型。比如上面的在硅谷镀金失败的造车新势力们:蔚来裁员、奇点被偷窃、拜腾解散,该句话中包含了组织关系-裁员和组织关系-解散两个事件类型。
该数据集中的训练集一共有11958个样本,65个事件类型,我们对该训练集进行简单的数据分析,来看看多事件类型的个数和占比,以及每个事件类型的数量。数据分析的脚本如下:
# -*- coding: utf-8 -*-
# author: Jclian91
# place: Pudong Shanghai
# time: 2020-04-09 21:31
from collections import defaultdict
from pprint import pprint
with open("./data/multi-classification-train.txt", "r", encoding="utf-8") as f:
content = [_.strip() for _ in f.readlines()]
# 每个事件类型的数量统计
event_type_count_dict = defaultdict(int)
# 多事件类型数量
multi_event_type_cnt = 0
for line in content:
# 事件类型
event_types = line.split(" ", maxsplit=1)[0]
# 如果|在事件类型中,则为多事件类型
if "|" in event_types:
multi_event_type_cnt += 1
# 对应的每个事件类型数量加1
for event_type in event_types.split("|"):
event_type_count_dict[event_type] += 1
# 输出结果
print("多事件类型的样本共有%d个,占比为%.4f。" %(multi_event_type_cnt, multi_event_type_cnt/len(content)))
pprint(event_type_count_dict)
输出结果如下:
多事件类型的样本共有1121个,占比为0.0937。
defaultdict(,
{'交往-会见': 98,
'交往-感谢': 63,
'交往-探班': 69,
'交往-点赞': 95,
'交往-道歉': 149,
'产品行为-上映': 286,
'产品行为-下架': 188,
'产品行为-发布': 1196,
'产品行为-召回': 287,
'产品行为-获奖': 139,
'人生-产子/女': 106,
'人生-出轨': 32,
'人生-分手': 118,
'人生-失联': 105,
'人生-婚礼': 59,
'人生-庆生': 133,
'人生-怀孕': 65,
'人生-死亡': 811,
'人生-求婚': 76,
'人生-离婚': 268,
'人生-结婚': 294,
'人生-订婚': 62,
'司法行为-举报': 98,
'司法行为-入狱': 155,
'司法行为-开庭': 105,
'司法行为-拘捕': 712,
'司法行为-立案': 82,
'司法行为-约谈': 266,
'司法行为-罚款': 224,
'司法行为-起诉': 174,
'灾害/意外-地震': 119,
'灾害/意外-坍/垮塌': 80,
'灾害/意外-坠机': 104,
'灾害/意外-洪灾': 48,
'灾害/意外-爆炸': 73,
'灾害/意外-袭击': 117,
'灾害/意外-起火': 204,
'灾害/意外-车祸': 286,
'竞赛行为-夺冠': 430,
'竞赛行为-晋级': 302,
'竞赛行为-禁赛': 135,
'竞赛行为-胜负': 1663,
'竞赛行为-退役': 95,
'竞赛行为-退赛': 141,
'组织关系-停职': 87,
'组织关系-加盟': 335,
'组织关系-裁员': 142,
'组织关系-解散': 81,
'组织关系-解约': 45,
'组织关系-解雇': 93,
'组织关系-辞/离职': 580,
'组织关系-退出': 183,
'组织行为-开幕': 251,
'组织行为-游行': 73,
'组织行为-罢工': 63,
'组织行为-闭幕': 59,
'财经/交易-上市': 51,
'财经/交易-出售/收购': 181,
'财经/交易-加息': 24,
'财经/交易-涨价': 58,
'财经/交易-涨停': 219,
'财经/交易-融资': 116,
'财经/交易-跌停': 102,
'财经/交易-降价': 78,
'财经/交易-降息': 28})
模型训练
我们利用sklearn模块中的MultiLabelBinarizer进行多标签编码,如果文本所对应的事件类型存在,则将该位置的元素置为1,否则为0。因此,y值为65维的向量,其中1个或多个为1,是该文本(x值)对应一个或多个事件类型。
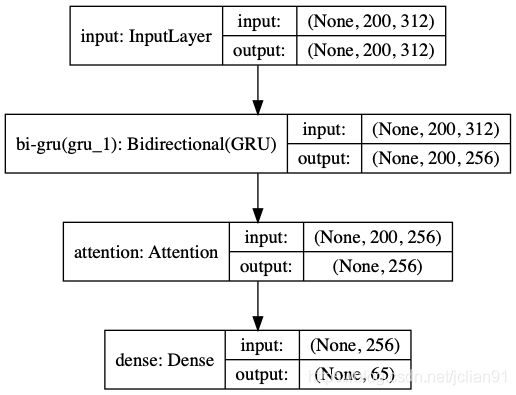
我们采用ALBERT对文本进行特征提取,最大文本长度为200,采用的深度学习模型如下:
模型训练的脚本(model_trian.py)的代码如下:
# -*- coding: utf-8 -*-
# author: Jclian91
# place: Pudong Shanghai
# time: 2020-04-03 18:12
import json
import numpy as np
from sklearn.preprocessing import MultiLabelBinarizer
from keras.models import Model
from keras.optimizers import Adam
from keras.layers import Input, Dense
from att import Attention
from keras.layers import GRU, Bidirectional
from tqdm import tqdm
import matplotlib.pyplot as plt
from albert_zh.extract_feature import BertVector
with open("./data/multi-classification-train.txt", "r", encoding="utf-8") as f:
train_content = [_.strip() for _ in f.readlines()]
with open("./data/multi-classification-test.txt", "r", encoding="utf-8") as f:
test_content = [_.strip() for _ in f.readlines()]
# 获取训练集合、测试集的事件类型
movie_genres = []
for line in train_content+test_content:
genres = line.split(" ", maxsplit=1)[0].split("|")
movie_genres.append(genres)
# 利用sklearn中的MultiLabelBinarizer进行多标签编码
mlb = MultiLabelBinarizer()
mlb.fit(movie_genres)
print("一共有%d种事件类型。" % len(mlb.classes_))
with open("event_type.json", "w", encoding="utf-8") as h:
h.write(json.dumps(mlb.classes_.tolist(), ensure_ascii=False, indent=4))
# 对训练集和测试集的数据进行多标签编码
y_train = []
y_test = []
for line in train_content:
genres = line.split(" ", maxsplit=1)[0].split("|")
y_train.append(mlb.transform([genres])[0])
for line in test_content:
genres = line.split(" ", maxsplit=1)[0].split("|")
y_test.append(mlb.transform([genres])[0])
y_train = np.array(y_train)
y_test = np.array(y_test)
print(y_train.shape)
print(y_test.shape)
# 利用ALBERT对x值(文本)进行编码
bert_model = BertVector(pooling_strategy="NONE", max_seq_len=200)
print('begin encoding')
f = lambda text: bert_model.encode([text])["encodes"][0]
x_train = []
x_test = []
process_bar = tqdm(train_content)
for ch, line in zip(process_bar, train_content):
movie_intro = line.split(" ", maxsplit=1)[1]
x_train.append(f(movie_intro))
process_bar = tqdm(test_content)
for ch, line in zip(process_bar, test_content):
movie_intro = line.split(" ", maxsplit=1)[1]
x_test.append(f(movie_intro))
x_train = np.array(x_train)
x_test = np.array(x_test)
print("end encoding")
print(x_train.shape)
# 深度学习模型
# 模型结构:ALBERT + 双向GRU + Attention + FC
inputs = Input(shape=(200, 312, ), name="input")
gru = Bidirectional(GRU(128, dropout=0.2, return_sequences=True), name="bi-gru")(inputs)
attention = Attention(32, name="attention")(gru)
num_class = len(mlb.classes_)
output = Dense(num_class, activation='sigmoid', name="dense")(attention)
model = Model(inputs, output)
# 模型可视化
# from keras.utils import plot_model
# plot_model(model, to_file='multi-label-model.png', show_shapes=True)
model.compile(loss='binary_crossentropy',
optimizer=Adam(),
metrics=['accuracy'])
history = model.fit(x_train, y_train, validation_data=(x_test, y_test), batch_size=128, epochs=10)
model.save('event_type.h5')
# 训练结果可视化
# 绘制loss和acc图像
plt.subplot(2, 1, 1)
epochs = len(history.history['loss'])
plt.plot(range(epochs), history.history['loss'], label='loss')
plt.plot(range(epochs), history.history['val_loss'], label='val_loss')
plt.legend()
plt.subplot(2, 1, 2)
epochs = len(history.history['accuracy'])
plt.plot(range(epochs), history.history['accuracy'], label='acc')
plt.plot(range(epochs), history.history['val_accuracy'], label='val_acc')
plt.legend()
plt.savefig("loss_acc.png")
训练过程输出内容如下:
一共有65种事件类型。
(11958, 65)
(1498, 65)
I:BERT_VEC:[graph:opt:128]:load parameters from checkpoint...
I:BERT_VEC:[graph:opt:130]:freeze...
I:BERT_VEC:[graph:opt:133]:optimize...
I:BERT_VEC:[graph:opt:144]:write graph to a tmp file: ./tmp_graph11
100%|██████████| 11958/11958 [02:47<00:00, 71.39it/s]
100%|██████████| 1498/1498 [00:20<00:00, 72.54it/s]
end encoding
(11958, 200, 312)
Train on 11958 samples, validate on 1498 samples
在最终的epoch上,训练集上的acuuracy为0.9966,测试集上的acuuracy为0.9964。训练结果的loss和acc曲线如下:
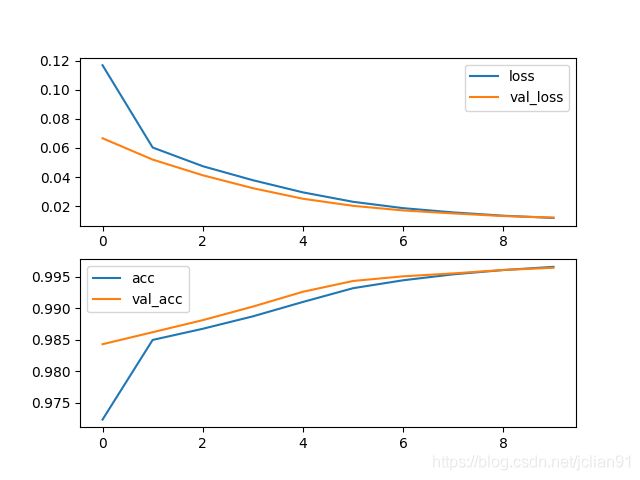
从上述结果看,多标签分类的模型效果还是相当不错的。
模型预测
我们利用下面的模型预测脚本(model_predict.py)对新的测试集数据进行验证,脚本代码如下:
# -*- coding: utf-8 -*-
# author: Jclian91
# place: Pudong Shanghai
# time: 2020-04-03 21:50
import json
import numpy as np
from keras.models import load_model
from att import Attention
from albert_zh.extract_feature import BertVector
load_model = load_model("event_type.h5", custom_objects={
"Attention": Attention})
# 预测语句
text = "北京时间6月7日,中国男足在广州天河体育场与菲律宾进行了一场热身赛,最终国足以2-0击败了对手,里皮也赢得了再度执教国足后的首场比赛胜利!"
text = text.replace("\n", "").replace("\r", "").replace("\t", "")
labels = []
bert_model = BertVector(pooling_strategy="NONE", max_seq_len=200)
# 将句子转换成向量
vec = bert_model.encode([text])["encodes"][0]
x_train = np.array([vec])
# 模型预测
predicted = load_model.predict(x_train)[0]
indices = [i for i in range(len(predicted)) if predicted[i] > 0.5]
with open("event_type.json", "r", encoding="utf-8") as g:
movie_genres = json.loads(g.read())
print("预测语句: %s" % text)
print("预测事件类型: %s" % "|".join([movie_genres[index] for index in indices]))
其中的几个样本的预测结果如下:
预测语句: 北京时间6月7日,中国男足在广州天河体育场与菲律宾进行了一场热身赛,最终国足以2-0击败了对手,里皮也赢得了再度执教国足后的首场比赛胜利!
预测事件类型: 竞赛行为-胜负
预测语句: 巴西亚马孙雨林大火持续多日,引发全球关注。
预测事件类型: 灾害/意外-起火
预测语句: 19里加大师赛资格赛前两天战报 中国选手8人晋级6人遭淘汰2人弃赛
预测事件类型: 竞赛行为-晋级
预测语句: 日本电车卡车相撞,车头部分脱轨并倾斜,现场起火浓烟滚滚
预测事件类型: 灾害/意外-车祸
预测语句: 截止到11日13:30 ,因台风致浙江32人死亡,16人失联。具体如下:永嘉县岩坦镇山早村23死9失联,乐清6死,临安区岛石镇银坑村3死4失联,临海市东塍镇王加山村3失联。
预测事件类型: 人生-失联|人生-死亡
预测语句: 定位B端应用,BeBop发布Quest专属版柔性VR手套
预测事件类型: 产品行为-发布
预测语句: 8月17日。凌晨3点20分左右,济南消防支队领秀城中队接到指挥中心调度命令,济南市中区中海环宇城往南方向发生车祸,有人员被困。
预测事件类型: 灾害/意外-车祸
预测语句: 注意!济南可能有雷电事故|英才学院14.9亿被收购|八里桥蔬菜市场今日拆除,未来将建新的商业综合体
预测事件类型: 财经/交易-出售/收购
预测语句: 昨天18:30,陕西宁强县胡家坝镇向家沟村三组发生山体坍塌,5人被埋。当晚,3人被救出,其中1人在医院抢救无效死亡,2人在送医途中死亡。今天凌晨,另外2人被发现,已无生命迹象。
预测事件类型: 人生-死亡|灾害/意外-坍/垮塌
总结
本项目已经上传至Github项目,网址为:https://github.com/percent4/multi-label-classification-4-event-type 。
后续有机会再给大家介绍更多多标签分类相关的问题,欢迎大家关注~