tensorflow(5)将ckpt转化为pb文件并利用tensorflow/serving实现模型部署及预测
本文将会以一个简单的例子,来介绍如何在tensorflow中将ckpt转化为pb文件,并利用tensorflow/serving来实现模型部署及预测。
我们以线性回归模型来作为例子介绍。整个项目的结构如下图:

线性回归模型
我们有如下模拟数据(随机产生):
import numpy as np
# Create data and simulate results
x_data = np.random.randn(2000, 3)
w_real = [0.3, 0.5, 0.1]
b_real = -0.2
noise = np.random.randn(1, 2000)*0.1
y_data = np.matmul(w_real, x_data.T) + b_real + noise
print(x_data)
print(y_data)
其中x_data,y_data的预览如下:
[[ 0.68287609 -1.12444428 -1.85077702]
[-1.13727073 0.46059937 0.86280493]
[ 0.74450168 -0.89626937 0.49412327]
...
[ 0.13001156 0.97029434 2.06705295]
[ 0.51501686 0.73565942 0.72848873]
[ 1.55647649 0.28905319 0.29061363]]
[[-0.77327739 -0.25601957 -0.50855096 ... 0.73748642 0.57350111
0.42478636]]
接着我们利用tensorflow来实现一个线性回归模型,求取系数w和偏重b。完整的Python代码(linear_regression.py)如下:
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
# Create data and simulate results
x_data = np.random.randn(2000, 3)
w_real = [0.3, 0.5, 0.1]
b_real = -0.2
noise = np.random.randn(1, 2000)*0.1
y_data = np.matmul(w_real, x_data.T) + b_real + noise
NUM_STEPS = 20
wb_ = []
# model structure
with tf.Graph().as_default() as g:
x = tf.placeholder(tf.float32, shape=[None, 3], name="x")
y_true = tf.placeholder(tf.float32, shape=None)
with tf.name_scope('inference') as scope1:
w = tf.Variable([[0, 0, 0]], dtype=tf.float32, name='weights')
b = tf.Variable(0, dtype=tf.float32, name='bias')
y_pred = tf.add(tf.matmul(w, tf.transpose(x)), b, name="y_pred")
with tf.name_scope('loss') as scope2:
loss = tf.reduce_mean(tf.square(y_true-y_pred))
with tf.name_scope('train') as scope3:
learning_rate = 0.5
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
train = optimizer.minimize(loss)
# model train and save
with tf.Session(graph=g) as sess:
init = tf.global_variables_initializer()
sess.run(init)
for step in range(NUM_STEPS):
sess.run(train, {
x: x_data, y_true: y_data})
if step % 5 == 0:
print(step, sess.run([w, b]))
wb_.append(sess.run([w, b]))
print(20, sess.run([w, b]))
saver = tf.train.Saver()
saver.save(sess, "./model/lr.ckpt")
输出的线性回归模型系数如下:
0 [array([[0.29378882, 0.4989346 , 0.0922103 ]], dtype=float32), -0.1957131]
5 [array([[0.3011083 , 0.5013811 , 0.09589875]], dtype=float32), -0.20220888]
10 [array([[0.30110833, 0.5013811 , 0.09589875]], dtype=float32), -0.20220888]
15 [array([[0.30110833, 0.5013811 , 0.09589875]], dtype=float32), -0.20220888]
20 [array([[0.30110833, 0.5013811 , 0.09589875]], dtype=float32), -0.20220888]
可以发现,我们利用tensorflow求得的系数w和偏重b与产生的随机数据中的w、b十分接近,说明该模型的参数是合理的。
ckpt转换为pb
与此同时,该代码会在model文件夹下生成ckpt文件。在文章tensorflow(4)使用tensorboard查看ckpt和pb图结构中给出了如何使用tensorboard来查看ckpt文件的模型图结构。代码(view_ckpt.py)如下:
# -*- coding: utf-8 -*-
import tensorflow as tf
from tensorflow.summary import FileWriter
sess = tf.Session()
tf.train.import_meta_graph("./model/lr.ckpt.meta")
FileWriter("logs/1", sess.graph)
sess.close()
该模型的结构如下图所示:
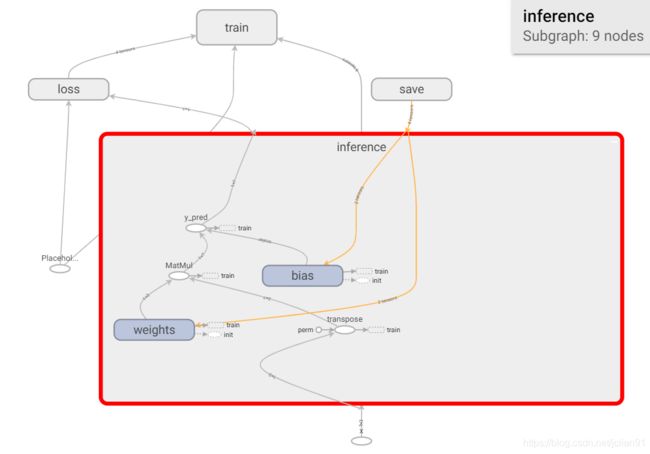
接下来,我们利用代码(ckpt_2_pb.py)将ckpt转化为pb文件。保存为pb文件的好处是实现创建模型与使用模型的解耦,使得前向推导inference代码统一。另外的好处就是保存为pb文件的时候,模型的变量会变成固定的,导致模型的大小会大大缩减。
# -*- coding: utf-8 -*-
import tensorflow as tf
from tensorflow.python import saved_model
export_path = "pb_models/lr/1"
graph = tf.Graph()
saver = tf.train.import_meta_graph("./model/lr.ckpt.meta", graph=graph)
with tf.Session(graph=graph) as sess:
saver.restore(sess, tf.train.latest_checkpoint("./model"))
saved_model.simple_save(session=sess,
export_dir=export_path,
inputs={"x": graph.get_operation_by_name('x').outputs[0]},
outputs={"y_pred": graph.get_operation_by_name('inference/y_pred').outputs[0]})
生成的pb文件位于pb_models/lr/1文件夹下,层级结构如下:
pb_models/
└── lr
└── 1
├── saved_model.pb
└── variables
├── variables.data-00000-of-00001
└── variables.index
3 directories, 3 files
利用saved_model命令可以查看该pb文件的输入、输出信息,命令如下:
saved_model_cli show --dir pb_models/lr/1 --all
输出结果如下:
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['x'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 3)
name: x:0
The given SavedModel SignatureDef contains the following output(s):
outputs['y_pred'] tensor_info:
dtype: DT_FLOAT
shape: (1, -1)
name: inference/y_pred:0
Method name is: tensorflow/serving/predict
该pb文件的输入为x,输出为y_pred。
利用tensorflow/serving实现模型部署及预测
TensorFlow Serving是GOOGLE开源的一个服务系统,适用于部署机器学习模型,灵活、性能高、可用于生产环境。本文利用TensorFlow Serving的官方Docker镜像tensorflow/serving:1.14.0进行模型部署。
利用tensorflow/serving部署上述pb文件的命令如下:
docker run -t --rm -p 8551:8501 -v "path_to_pb_models/pb_models/lr:/models/lr" -e MODEL_NAME=lr tensorflow/serving
输出如下信息即表示模型部署成功:
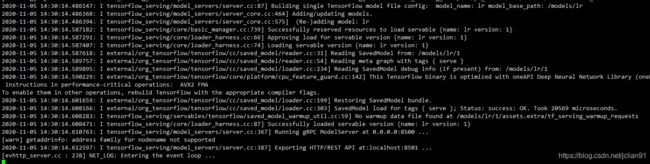
接着我们使用上面部署好的模型HTTP服务来进行预测。代码(tf_serving.py)如下:
# -*- coding: utf-8 -*-
import requests
# 利用tensorflow/serving的HTTP接口请求进行预测
x = [1, 2, 2]
tensor = {
"instances": [{
"x": x}]}
url = "http://192.168.1.193:8551/v1/models/lr:predict"
req = requests.post(url, json=tensor)
if req.status_code == 200:
y_pred = req.json()['predictions'][0]
print("tensorflow/serving predict: ", y_pred)
# 直接按照tf模型训练的系数进行预测
w = [0.30110833, 0.5013811 , 0.09589875]
b = -0.20220888
result = 0
for data, weight in zip(x, w):
result += data*weight
result += b
print("tf model predict: ", result)
输出结果为:
tensorflow/serving predict: [1.29345918]
tf model predict: 1.2934591500000001
总结
本文着重介绍如何在tensorflow中将ckpt转换为pb,并利用tensorflow/serving来实现模型部署、预测来证明生成的pb文件是有效的。
本文演示的代码已经上传至Github,网址为:https://github.com/percent4/ckpt_2_pb_examples 。
后续笔者还会写介绍tensorflow/serving的相关文章,敬请关注~