这里介绍了如何编写完整的堆栈数据库Web应用程序,而不使用SQL,HQL,PHP,ASP,HTML,CSS或Javascript,而是使用Vaadin的UI层和Speedment Stream ORM完全依赖Java。
是否曾经想过快速创建连接到您现有数据库的Web应用程序,或构建具有较短上市时间要求的专业应用程序? Java Stream API释放了用纯Java编写数据库查询的可能性。
在本文中,我们将演示如何利用两个Java框架来完成此任务。 Vaadin和Speedment。 由于它们都使用Java Streams,因此很容易将它们连接在一起。 这意味着我们最终将得到一个简短,简洁且类型安全的应用程序。
对于这个小型项目,我们将使用名为“ Employees”的My SQL示例数据库,该数据库提供分布在六个单独的表上的约160MB数据,并包含400万条记录。
完整的应用程序代码可在GitHub上获得,如果您想在自己的环境中运行该应用程序,则可以克隆此存储库。 您还需要Vaadin和Speedment的试用许可证才能使用本文中使用的功能。 这些是免费的。
预期的最终结果是一个Web应用程序,可以在其中分析不同部门之间的性别平衡和工资分配。 使用纯标准的Vaadin Charts Java组件以图形方式显示结果,如以下视频所示:
设置数据模型
我们正在使用Speedment Stream ORM访问数据库。 使用Speedment初始化程序可以轻松设置任何项目。 Speedment可以直接从数据库的架构数据生成Java类。 生成后,我们可以像下面这样创建Speedment实例:
Speedment speedment = new EmployeesApplicationBuilder()
.withUsername("...") // Username need to match database
.withPassword("...") // Password need to match database
.build();为部门创建下拉菜单
在我们的Web应用程序中,我们希望有一个所有部门的下拉列表。 从该方法可以很容易地从数据库中检索部门:
public Stream departments() {
DepartmentsManager depts = speedment.getOrThrow(DepartmentsManager.class);
return depts.stream();
} 将部门和员工联系在一起
现在,我们将在Departments和Employees之间创建联接关系。 在数据库中,有一个多对多关系表,将这些表连接在一起,称为DeptEmpl 。
首先,我们创建一个自定义元组类,该类将保存联接表中的三个条目:
public final class DeptEmplEmployeesSalaries {
private final DeptEmp deptEmp;
private final Employees employees;
private final Salaries salaries;
public DeptEmplEmployeesSalaries(
DeptEmp deptEmp,
Employees employees,
Salaries salaries
) {
this.deptEmp = requireNonNull(deptEmp);
this.employees = requireNonNull(employees);
this.salaries = requireNonNull(salaries);
}
public DeptEmp deptEmp() { return deptEmp; }
public Employees employees() { return employees; }
public Salaries salaries() { return salaries; }
public static TupleGetter0 deptEmpGetter() {
return DeptEmplEmployeesSalaries::deptEmp;
}
public static TupleGetter1 employeesGetter() {
return DeptEmplEmployeesSalaries::employees;
}
public static TupleGetter2 salariesGetter() {
return DeptEmplEmployeesSalaries::salaries;
}
} DeptEmplEmployeesSalaries只是这三个实体的不可变持有人,除了它具有可用于提取单个实体的三个附加“ getter”方法。 请注意,它们返回TupleGetter ,与仅使用匿名lambda或方法引用相比,它们允许联接和聚合使用优化版本。
现在有了自定义元组,我们可以轻松定义Join关系:
private Join joinDeptEmpSal(Departments dept) {
// The JoinComponent is needed when creating joins
JoinComponent jc = speedment.getOrThrow(JoinComponent.class);
return jc.from(DeptEmpManager.IDENTIFIER)
// Only include data from the selected department
.where(DeptEmp.DEPT_NO.equal(dept.getDeptNo()))
// Join in Employees with Employees.EMP_NO equal DeptEmp.EMP_NO
.innerJoinOn(Employees.EMP_NO).equal(DeptEmp.EMP_NO)
// Join Salaries with Salaries.EMP_NO) equal Employees.EMP_NO
.innerJoinOn(Salaries.EMP_NO).equal(Employees.EMP_NO)
// Filter out historic salary data
.where(Salaries.TO_DATE.greaterOrEqual(currentDate))
.build(DeptEmplEmployeesSalaries::new);
} 在构建Join表达式时,我们首先使用DeptEmp表开始(我们记得,这是Departments和Employees之间的多对多关系表)。 对于此表,我们应用where()语句,以便我们仅能够过滤出属于我们要在联接中出现的部门的多对多关系。
接下来,我们联接Employees表,并指定联接关系,其中新联接的表的Employees.EMP_NO列等于DeptEmp.EMP_NO 。
之后,我们加入Salaries表并指定另一个联接关系,其中Salaries.EMP_NO等于Employees.EMP_NO 。 对于此特定的联接关系,我们还应用where()语句,以便我们过滤掉当前的薪水(而不是历史的,雇员的过去薪水)。
最后,我们调用build()方法并定义DeptEmplEmployeesSalaries类的构造函数,该类包含三个实体DeptEmp , Employees和Salaries 。
计算部门的员工人数
使用上面的join方法,可以很容易地在Join流中计算某个部门的员工人数。 我们可以这样去做:
public long countEmployees(Departments department) {
return joinDeptEmpSal(department)
.stream()
.count();
}计算工资分配汇总
通过使用内置的Speedment Aggregator,我们可以非常轻松地表达聚合。 聚合器可以使用常规Java集合,单个表中的Java流以及连接流,而无需在堆上构造中间Java对象。 这是因为它完全不在堆中存储所有数据结构。
我们首先以创建简单的POJO形式的“结果对象”开始,该POJO将用作完成的堆外聚合与Java堆世界之间的桥梁:
public class GenderIntervalFrequency {
private Employees.Gender gender;
private int interval;
private long frequency;
private void setGender(Employees.Gender gender) { this.gender = gender; }
private void setInterval(int interval) { this.interval = interval; }
private void setFrequency(long frequency) { this.frequency = frequency;}
private Employees.Gender getGender() { return gender; }
private int getInterval() { return interval; }
private long getFrequency() { return frequency; }
}现在有了POJO,我们可以构建一个返回Aggregation的方法,如下所示:
public Aggregation freqAggregation(Departments dept) {
Aggregator aggregator =
// Provide a constructor for the "result object"
Aggregator.builder(GenderIntervalFrequency::new)
// Create a key on Gender
.firstOn(DeptEmplEmployeesSalaries.employeesGetter())
.andThen(Employees.GENDER)
.key(GenderIntervalFrequency::setGender)
// Create a key on salary divided by 1,000 as an integer
.firstOn(DeptEmplEmployeesSalaries.salariesGetter())
.andThen(Salaries.SALARY.divide(SALARY_BUCKET_SIZE).asInt())
.key(GenderIntervalFrequency::setInterval)
// For each unique set of keys, count the number of entitites
.count(GenderIntervalFrequency::setFrequency)
.build();
return joinDeptEmpSal(dept)
.stream()
.parallel()
.collect(aggregator.createCollector());
} 这需要一些解释。 当我们调用Aggregator.builder()方法时,我们提供了“结果对象”的构造函数,我们将其用作堆外世界与堆上世界之间的桥梁。
有了构建器之后,我们就可以开始定义聚合了,通常最简单的方法就是从聚合中要使用的键(即组)开始。 在汇总Join操作的结果时,我们首先需要指定要从中提取密钥的实体。 在这种情况下,我们要使用员工的性别,因此我们调用.firstOn(eptEmplEmployeesSalaries.employeesGetter()) ,该方法将从元组中提取Employees实体。 然后,我们应用.andThen(Employees.GENDER) ,然后从Employees实体中提取性别属性。 key()方法采用一个方法引用作为方法的参考,一旦我们想实际读取聚合结果,该方法将被调用。
第二个键的指定方式几乎相同,只是在这里我们应用.firstOn(DeptEmplEmployeesSalaries.salariesGetter())方法来提取Salaries实体而不是Employees实体。 然后,当我们应用.andThen()方法时,我们正在使用一个表达式来转换薪水,因此它被除以1,000,并被视为整数。 这将为每千美元的工资创建单独的收入等级。
count()运算符只是说我们要计算每个密钥对的出现次数。 因此,如果有两名男性的收入在57位(即57,000到57,999之间的薪水),则计数操作将计算这两个密钥。
最后,在以return开头的行中,将进行汇总的实际计算,由此应用程序将并行汇总所有成千上万的薪水,并返回数据库中所有收入数据的Aggregation 。 可以将Aggregation视为具有所有键和值的List ,只是将数据存储在堆外。
添加JVM中的内存加速
通过仅向我们的应用程序添加两行,我们就可以获得具有JVM内存加速功能的高性能应用程序。
Speedment speedment = new EmployeesApplicationBuilder()
.withUsername("...") // Username need to match database
.withPassword("...") // Password need to match database
.withBundle(InMemoryBundle.class) // Add in-JVM-acceleration
.build();
// Load a snapshot of the database into off-heap JVM-memoory
speedment.get(DataStoreComponent.class)
.ifPresent(DataStoreComponent::load); InMemoryBundle允许使用堆外内存将整个数据库引入JVM,然后允许直接从RAM而不是使用数据库直接执行Streams和Joins。 这将提高性能,并使Java应用程序更具确定性。 使数据处于堆外状态也意味着数据将不会影响Java Garbage Collect,从而可以使用巨大的JVM,而不会影响GC。
由于内存中的加速,即使在我的笔记本电脑上,即使最大的部门拥有超过60,000薪水,也可以在不到100毫秒的时间内进行计算。 这将确保我们的用户界面保持响应状态。
用Java构建UI
现在,数据模型已经完成,我们继续进行应用程序的可视化方面。 如前所述,这是利用Vaadin完成的,该框架允许使用Java实现HTML5 Web用户界面。 Vaadin框架建立在组件的概念上,这些组件可以是布局,按钮或介于两者之间的任何东西。 组件被建模为对象,可以以多种方式对其进行自定义和样式设置。
上图描述了我们打算为DataModel构建的GUI的结构。 它由9个组件组成,其中5个组件是从数据库中读取信息并将其呈现给用户的,其余的则是静态的。 事不宜迟,让我们开始配置UI。

此图显示了GUI中包含的组件的层次结构。
Vaadin UI层
为了将Vaadin集成到应用程序中,我们从Vaadin下载了一个入门包,以建立一个简单的项目基础。 这将自动生成一个UI类,该类是任何Vaadin应用程序的基础。
@Theme("mytheme")
public class EmployeeUI extends UI {
@Override // Called by the server when the application starts
protected void init(VaadinRequest vaadinRequest) { }
// Standard Vaadin servlet which was not modified
@WebServlet(urlPatterns = "/*", name = "MyUIServlet", asyncSupported = true)
@VaadinServletConfiguration(ui = EmployeeUI.class, productionMode = false)
public static class MyUIServlet extends VaadinServlet { }
} 启动应用程序时,将从服务器调用覆盖的init() ,因此,我们很快将在此声明运行应用程序时要执行的操作。 EmployeeUI还包含MyUIServlet ,这是用于部署的标准Servlet类。 对于此应用程序,无需修改。
组件的创建
如上所述,我们所有的组件都将在init()声明。 建议不要将其作为最佳实践,但对于范围较小的应用程序来说效果很好。 虽然,当我们选择一个新部门时,我们希望通过一个单独的方法来集体更新大多数组件,这意味着这些组件将在此过程中被声明为实例变量。
应用标题
我们从创建标题标签开始。 由于其值不会改变,因此可以在本地声明。
Label appTitle = new Label("Employee Application");
appTitle.setStyleName("h2");除了一个值,我们给它一个样式名称。 样式名称允许完全控制组件的外观。 在这种情况下,我们使用内置的Vaadin Valo Theme,只需将参数设置为“ h2”即可选择标题样式。 此样式名称还可用于使用自定义CSS定位组件(例如.h2 {font-family:'Times New Roman;})。
文字栏位

要查看所选部门的员工人数和平均工资,我们使用TextField组件。 TextField主要用于用户文本输入,尽管通过将其设置为只读,我们禁止任何用户交互。 请注意如何用空格分隔两个样式名称。
noOfEmployees = new TextField("Number of employees"); // Instance variable
noOfEmployees.setReadOnly(true);
// Multiple style names are separated with a blank space
noOfEmployees.setStyleName("huge borderless"); 尽管具有不同的标题和变量名称,但该代码对于averageSalary TextField是重复的。
图表
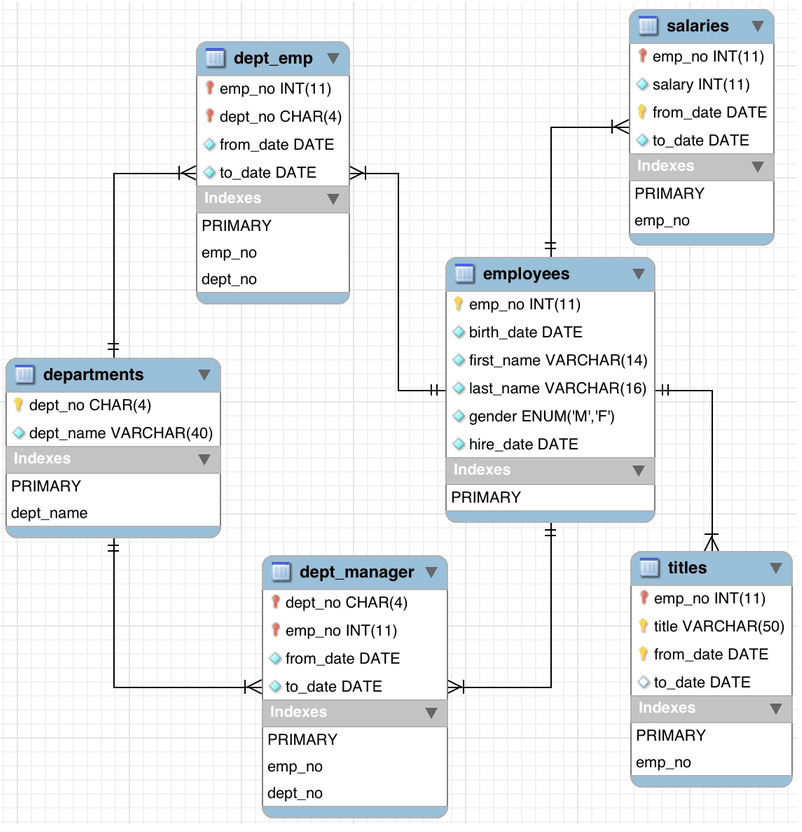
可以使用Vaadin Charts插件轻松创建图表,就像其他任何组件一样,也可以使用具有相应属性的Java Object图表Java Object 。 对于此应用程序,我们使用了COLUMN图表来查看性别平衡,并使用AREASPLINE进行工资分配。
/* Column chart to view balance between female and male employees at a certain department */
genderChart = new Chart(ChartType.COLUMN);
Configuration genderChartConfig = genderChart.getConfiguration();
genderChartConfig.setTitle("Gender Balance");
// 0 is only used as an init value, chart is populated with data in updateUI()
maleCount = new ListSeries("Male", 0);
femaleCount = new ListSeries("Female", 0);
genderChartConfig.setSeries(maleCount, femaleCount);
XAxis x1 = new XAxis();
x1.setCategories("Gender");
genderChartConfig.addxAxis(x1);
YAxis y1 = new YAxis();
y1.setTitle("Number of employees");
genderChartConfig.addyAxis(y1); 与图表关联的大多数属性均由其配置控制,该配置可通过getConfiguration()检索。 然后用于添加图表标题,两个数据系列和轴属性。 对于genderChart ,由于其简单的性质,使用了一个简单的ListSeries来保存数据。 尽管对于salaryChart下面,一个DataSeries选择,因为它处理一个更大,更复杂的数据集。
该声明salaryChart非常类似于的genderChart 。 同样,检索配置并将其用于添加标题和轴。
salaryChart = new Chart(ChartType.AREASPLINE); 由于两个图表都显示了男性和女性的数据,因此我们决定使用一个固定的传说,将其固定在salaryChart 。
/* Legend settings */
Legend legend = salaryChartConfig.getLegend();
legend.setLayout(LayoutDirection.VERTICAL);
legend.setAlign(HorizontalAlign.RIGHT);
legend.setVerticalAlign(VerticalAlign.TOP);
legend.setX(-50);
legend.setY(50);
legend.setFloating(true); 最后,我们添加两个空的DataSeries ,稍后将用数据填充该数据系列。
// Instance variables to allow update from UpdateUI()
maleSalaryData = new DataSeries("Male");
femaleSalaryData = new DataSeries("Female");
salaryChartConfig.setSeries(maleSalaryData, femaleSalaryData);部门选择器
最后一块是部门选择器,它控制应用程序的其余部分。
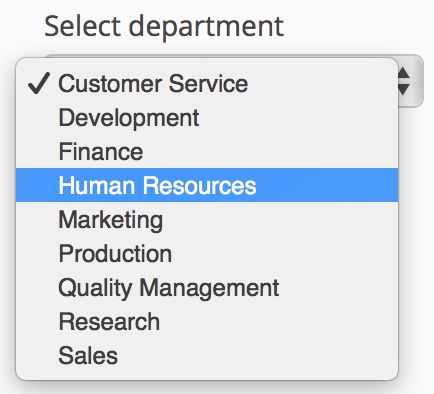
/* Native Select component to enable selection of Department */
NativeSelect selectDepartment = new NativeSelect<>("Select department");
selectDepartment.setItems(DataModel.departments());
selectDepartment.setItemCaptionGenerator(Departments::getDeptName);
selectDepartment.setEmptySelectionAllowed(false); 我们将其实现为NativeSelect DataModel定义的departments() ,以从数据库中检索部门流。 接下来,我们指定要在下拉列表中显示的Department属性(默认为toString() )。
由于不允许空选择,因此将defaultDept设置为Department Stream的第一个元素。 请注意, defaultDept存储为变量,以供以后使用。
/* Default department to use when starting application */
final Departments defaultDept = DataModel.departments().findFirst().orElseThrow(NoSuchElementException::new);
selectDepartment.setSelectedItem(defaultDept);将组件添加到UI
到目前为止,我们只声明了这些组件,而没有将它们添加到实际的画布中。 要在应用程序中显示它们,它们都需要添加到UI中。 这通常是通过将它们附加到Layout来完成的。 布局用于创建结构化的层次结构,并且可以嵌套在一起。
HorizontalLayout contents = new HorizontalLayout();
contents.setSizeFull();
VerticalLayout menu = new VerticalLayout();
menu.setWidth(350, Unit.PIXELS);
VerticalLayout body = new VerticalLayout();
body.setSizeFull();如上面的代码所示,为此使用了三种布局,一种是水平布局,两种是垂直布局。 定义布局后,我们可以添加组件。
menu.addComponents(appTitle, selectDepartment, noOfEmployees, averageSalary);
body.addComponents(genderChart, salaryChart);
contents.addComponent(menu);
// Body fills the area to the right of the menu
contents.addComponentsAndExpand(body);
// Adds contents to the UI
setContent(contents); 组件按添加顺序出现在UI中。 对于VerticalLayout例如菜单),这意味着从上到下。 请注意, HorizontalLayout内容如何保持两个VerticalLayout放置。 这是必要的,因为UI本身只能容纳一个组件,即将所有组件作为一个单元保存的内容。
在用户界面中反映DataModel
现在所有的视觉效果都就位了,是时候让它们反映数据库内容了。 这意味着我们需要通过从DataModel检索信息来向组件添加值。 我们的数据模型和EmployeeUI之间的桥接将通过处理来自selectDepartment事件来selectDepartment 。 这是通过在init()添加选择侦听器来完成的:
selectDepartment.addSelectionListener(e ->
updateUI(e.getSelectedItem().orElseThrow())
); 由于尚未定义updateUI() ,因此这是我们的下一个任务。
private void updateUI(Departments dept) { } 这里快速提醒我们要执行updateUI() :选择一个新部门后,我们要计算并显示员工总数,男性和女性人数,总平均薪水以及男性的薪水分布和那个部门的女性。
方便DataModel ,我们在设计数据模型时就考虑到了这一点,可以轻松地从数据库中收集信息。
我们从文本字段的值开始:
final Map counts = DataModel.countEmployees(dept);
noOfEmployees.setValue(String.format("%,d", counts.values().stream().mapToLong(l -> l).sum()));
averageSalary.setValue(String.format("$%,d", DataModel.averageSalary(dept).intValue())); 男性和女性的总和给出了雇员总数。 averageSalary()返回转换为int的Double 。 这两个值在传递到文本字段之前都格式化为String 。
我们还可以通过检索男性和女性的单独计数来使用Map计数来填充第一张图。
final List maleSalaries = new ArrayList<>();
final List femaleSalaries = new ArrayList<>();
DataModel.freqAggregation(dept)
.streamAndClose()
.forEach(agg -> {
(agg.getGender() == Gender.F ? femaleSalaries : maleSalaries)
.add(new DataSeriesItem(agg.getInterval() * 1_000, agg.getFrequency()));
}); 我们DataModel提供了一个Aggregation ,我们可以认为含有性别,工资的元组的列表和相应的工资频率(有多少人分享的薪水)。 通过在Aggregation流传输,我们可以在包含DataSeriesItem的两个List分离男性和女性数据。 在这种情况下,将DataSeriesItem用作具有x和y值的点。
Comparator comparator = Comparator.comparingDouble((DataSeriesItem dsi) -> dsi.getX().doubleValue());
maleSalaries.sort(comparator);
femaleSalaries.sort(comparator); 在将数据添加到图表之前,我们按x值的升序对其进行排序,否则,该图表将看起来非常混乱。 现在,我们的两个排序List会非常适合与DataSeries salaryChart的。
//Updates salaryChart
maleSalaryData.setData(maleSalaries);
femaleSalaryData.setData(femaleSalaries);
salaryChart.drawChart(); 由于我们要更改整个数据集而不是单个点,因此我们将DataSeries的数据设置为刚创建的x和y的列表。 与ListSeries的更改不同,这不会触发图表的更新,这意味着我们必须使用drawChart()强制进行手动更新。
最后,在应用程序启动时,我们需要使用默认值填充组件。 现在,可以通过在init()末尾调用updateUI(defaultDept)来完成此操作。
Java样式
Vaadin在为组件增加个人感觉时提供了完全的自由。 由于这是纯Java应用程序,因此仅使用了Java框架中可用的样式选项,尽管CSS样式自然可以完全控制视觉效果。

应用ChartTheme之前和之后的比较。
为了使图表具有个人风格,我们创建了一个ChartTheme类, ChartTheme扩展了Theme 。 在构造函数中,我们定义了要更改的属性,即数据系列的颜色,背景,图例和文本。
public class ChartTheme extends Theme {
public ChartTheme() {
Color[] colors = new Color[2];
colors[0] = new SolidColor("#5abf95"); // Light green
colors[1] = new SolidColor("#fce390"); // Yellow
setColors(colors);
getChart().setBackgroundColor(new SolidColor("#3C474C"));
getLegend().setBackgroundColor(new SolidColor("#ffffff"));
Style textStyle = new Style();
textStyle.setColor(new SolidColor("#ffffff")); // White text
setTitle(textStyle);
}
} 然后通过将这一行添加到init() ,将主题应用于所有图表:
ChartOptions.get().setTheme(new ChartTheme());结论
我们使用Speedment来连接数据库,使用Vaadin来连接最终用户。 两者之间唯一需要的代码就是几个Java Streams构造,以声明方式描述应用程序逻辑,从而使上市时间和维护成本降至最低。
可以从GitHub上分叉此仓库,并开始自己尝试。
s
Julia·古斯塔夫森(Julia Gustafsson)
Per Minborg
翻译自: https://www.javacodegeeks.com/2018/06/full-stack-java.html