Elastic Stack(ELK)宝典之:Logstash输入与输出

文/田雪松
Logstash管道可以配置多个输入插件,这可以将不同源头的数据整合起来做统一处理。在分布式系统中,数据都分散在不同的容器或不同的物理机上,每一份数据往往又不完整,需要类似Logstash这样的工具将数据收集起来。比如在微服务环境下,日志文件就分散在不同机器上,即使是单个请求的日志也有可能分散在多台机器上。如果不将日志收集起来,就无法查看一个业务处理的完整日志。
Logstash管道也可以配置多个输出插件,每个输出插件代表一种对数据处理的业务需求。比如对日志数据存档就可以使用s3输出插件,将日志数据归档到S3存储服务上;还可以使用elasticsearch输出插件,将数据索引到Elasticsearch中以便快速检索等等。在业务系统创建之初,人们对于数据究竟会产生什么样的价值并不清楚。但随着人们对于业务系统理解的深入,对数据处理的新需求就会迸发出来。面对新需求,只要为Logstash管道添加新的输出插件就能立即与新的数据处理需求对接起来,而对已有数据处理业务又不会产生任何影响。到目前为止,Logstash对于常见的数据处理需求都可以很好的对接,这包括数据归档存储、数据分析处理、数据监控报警等等。
Logstash官方提供的输入插件与输出插件都有50多种,而在这共计100多种的插件中每一种插件又有不同的配置参数,想在一章之内将它们彻底介绍清楚有一定的困难。但总结这些插件时会发现,大多数输入插件也会在输出插件中出现。基于这种考量也限于篇幅,本章根据插件所属大类分别按小节介绍,对于比较特殊的插件将在最后一节统一介绍。
在开始介绍这些插件前,先来介绍两个最简单的插件,即stdin输入插件和stdout插件。这两个插件分别代表标准输入和标准输出,也就是命令行控制台。由于它们比较简单,所以一般不需要做任何配置就可以直接使用。stdin只有一组通用参数,这些参数不仅对stdin有效,对其它输入插件也有效。具体如表1所示:
表1 输入插件通用参数
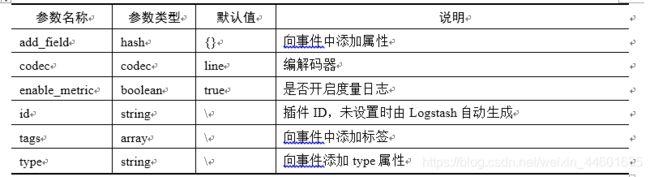
同样的,stdout也是只有通用参数,这些参数也是对所有输出插件都有效。具体如表2所示:
表2 输出插件通用参数

其中codec参数在不同的插件中是不一样的,表13.1和13.2只是示意地列出了stdin和stdout的默认编解码器,其它插件的编解码器在本书第12章第12.3.1节中有详细介绍。stdin和stdout配置示例在第1章和第12章中都曾介绍过,它们可以在学习其它插件时配合使用以形成完整的管道。限于篇幅,如果没有特别的配置,后续示例中涉及这两个插件时一般都会省略掉。
1 beats与elasticsearch
由于同属Elastic Stack家族,Beats和Elasticsearch无疑是Logstash的最佳搭档。Beats组件一般只能作为Logstash的输入,通过beats输入插件接入Logstash。而Elasticsearch组件既可以作为输入也可以作为输出,所以同时存在着elasticsearch输入插件和elasticsearch输出插件。
1.1 beats插件
由于Beats组件只能作为Logstash输入,所以只有beats输入插件而不存在输出插件。Beats组件本身又是一个大家族,每一种Beats类型都对应一个特定领域的数据收集需求。所以Beats组件基本上可以代替Logstash其它输入插件,这使得beats输入插件在所有插件中具有非常重要的地位。尽管beats输入插件非常重要,但beats输入插件在使用上非常简单,只要通过port参数指定Logstash监听Beats组件的端口即可。例如在示例1中,Logstash监听Beats组件的端口被设置为5044:
input {
beats {
port => 5044
}
}
示例1 beats输入插件
与此相对应,Beats组件也需要在它的配置文件中指定输出类型为Logstash,并配置连接端口为5044,详细请参见第15章第15.3.2节的介绍。
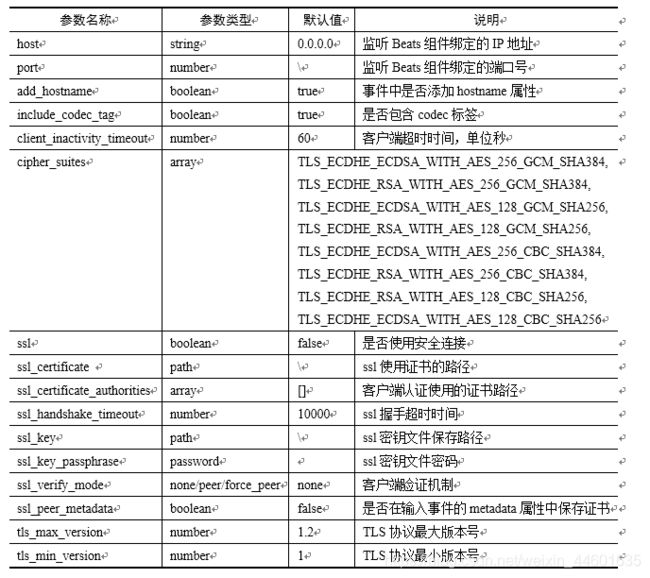
Beats组件在向Logstash输入事件时,都会在@metadata属性中添加三个子属性即beat、version和type。它们分别代表了Beats组件的名称、版本和类型,它们可以在输出组件为elasticsearch时设置索引名称。按Logstash的推荐,为了防止冲突可以将索引名称设置为:“%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}”。例如,如果使用Filebeat版本7.0.0在2019年5月10日导入数据,则索引名称为“filebeat-7.0.0-2019.05.10”。beats输入插件其它参数大部分都与安全连接相关,具体如表3所示:
表3 beats输入插件参数
1.2 elasticsearch插件
Elasticsearch既可以作为Logstash输入也可以作为输出,但在多数情况下Elasticsearch都是作为Logstash输出使用,所以先来看一下elasticsearch输出插件。
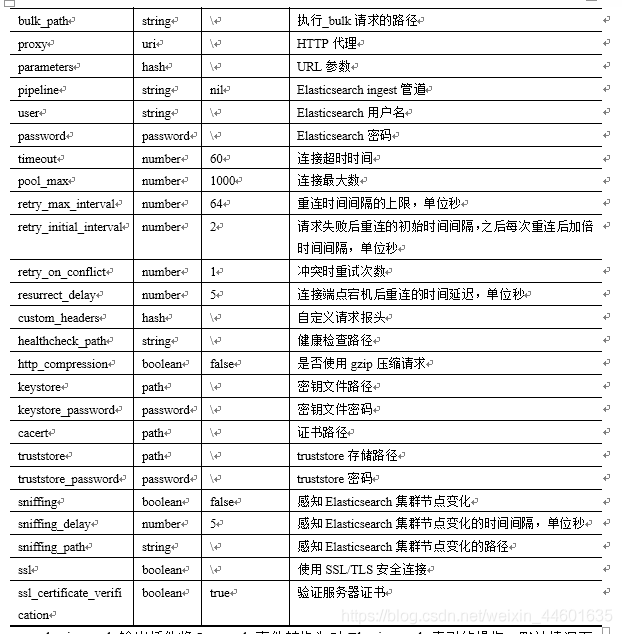
elasticsearch输出插件使用hosts参数设置连接Elasticsearch实例的地址,hosts参数可以接收多个Elasticsearch实例地址,Logstash在发送事件时会在这些实例上做负载均衡。如果连接的Elasticsearch与Logstash在同一台主机且端口为9200,那么这个参数可以省略,因为它的默认值就是[//127.0.0.1]。与连接相关的参数如表4所示:
表4 elasticsearch插件连接相关参数
elasticsearch输出插件将Logstash事件转换为对Elasticsearch索引的操作,默认情况下插件会将事件编入名称格式为“logstash-%{+YYYY.MM.dd}”的索引中,可使用index参数修改索引名称格式。除了编入索引以外,elasticsearch输出插件还支持根据ID删除文档、更新文档等操作,具体可以通过action参数配置。action可选参数包括index、delete、create和update几种,其中index和create都用于向索引中编入文档,区别在于create在文档存在时会报错,而index则会使用新文档替换原文档。delete和update则用于删除和更新文档,所以在使用delete、update和create时需要通过document_id参数指定文档ID。此外,update在更新时如果文档ID不存在,那么可以使用upsert参数设置添加新文档的内容。例如:
output {
elasticsearch {
document_id => "%{message}"
action => "update"
upsert => "{\"message\":\"id didn't exist\"}"
}
}
示例2 action与document_id
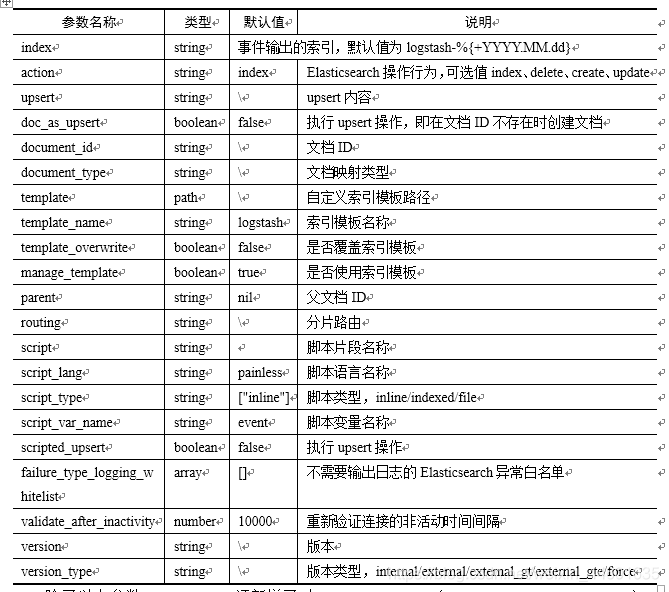
在示例2中,使用message属性的内容作为文档ID值,并根据这个ID值使用当前文档更新原文档。如果文档不存在则使用upsert参数设置的内容添加文档,upsert参数要求为字符串类型,其中属性要使用双引号括起来。除了upsert以外,还可以将doc_as_upsert参数设置为true,则在文档不存在时会当前文档添加到索引。elasticsearch插件还有很多与Elasticsearch索引、模板、路由等相关的参数,如表5所示:
表5 Elasticsearch输出插件参数
除了以上参数,Logstash 6.6还新增了对Elasticsearch ILM(Index Lifecycle Management)接口的支持,涉及ilm_enabled、ilm_pattern、ilm_rollover_alias等几个参数,它们可用于索引生命周期管理。
Elasticsearch作为Logstash输入源时,Logstash默认会通过DSL从索引“logstash-*”中读取所有文档,一旦读取完毕Logstash就会自动退出。输入插件使用的DSL通过query参数设置,参数值与Elasticsearch的_search接口参数相同。例如想要从kibana_sample_data_flights索引中获取所有出发地为中国的航班文档:
input {
elasticsearch {
hosts => ["localhost"]
index => "kibana_sample_data_flights"
query => '{"query": {"match": {"OriginCountry": "CN"}}}'
}
}
示例3 elasticsearch输入插件
在示例3中,hosts参数指明了要连接Elasticsearch的节点地址,而index参数和query参数则分别指明了要检索的索引名称和相应的DSL。其它可在elasticsearch输入插件中使用的参数如表6所示:
表6 elasticsearch输入插件参数

在这些参数中,schedule可以通过CRON格式设置DSL执行的周期,一旦设置了这个参数,elasticsearch输入插件就会定期执行DSL,而不会在执行结束后就立即退出。
1.3 dead_letter_queue插件
dead_letter_queue插件从Logstash死信队列中读取事件,并将事件传入Logstash管道中做进一步处理。由于目前版本中,死信队列只支持目标数据源为Elasticsearch输出插件,所以本书将它与elasticsearch插件放在一起讲解。死信队列是Logstash在输出事件出错时的一种容错机制,使用dead_letter_queue插件前必须要开启Logstash死信队列功能,有关死信队列的详细内容请参考本书第12章第12.1.3节。
从原理上来说,死信队列中保存的某一管道传输失败的事件,所以dead_letter_queue插件读取进来的事件就不应该再传输回原来的管道。也就是说,dead_letter_queue插件在处理逻辑上应该设计一个新管道来处理失败事件,在新管道中需要将导致错误的原因排除,然后再将死信事件存储到相应的数据源上。
dead_letter_queue插件使用path参数设置死信队列存储路径,使用pipeline_id参数设置管道ID。如果没有设置pipeline_id,默认将读取主管道main。所以使用dead_letter_queue插件最简形式就是设置好死信队列路径即可:
input {
dead_letter_queue {
path => "/path/to/data/dead_letter_queue"
}
}
示例4 dead_letter_queue插件
dead_letter_queue插件还可以通过一种称为SinceDB的文件保存插件读取队列的偏移量,这可以保证在Logstash重启或意外崩溃后不会重复读取死信事件。有两个参数与SinceDB相关,一个是commit_offsets参数,用于设置是否保存读取的偏移量;另一个是sincedb_path参数,用于设置SinceDB存储路径。elasticsearch输入插件的参数如表13.4所示:
表4 elasticsearch输入插件参数

2 面向文件的插件
面向文件的输入插件从文件中读取数据并转换为事件传入Logstash管道,而面向文件的输出插件则将Logstash管道事件转换为文本写入到文件中。面向文件的输入输出插件名称都是file,它们都需要通过path参数设置文件路径。不同的是,文件输入插件的path参数类型是数组,所以可以指定一组文件作为输入源头。而文件输出插件的path参数则为字符串,只能设置一个文件名称。此外,文件输入插件的path参数只能是绝对路径而不能使用相对路径,并且在路径中可使用“*”和“**”这样的通配符。而文件输出插件则可以使用相对路径,并且还可以在路径中使用“%{}”的形式动态设置文件路径或名称。这也是文件输出插件形成滚动文件的方式,例如使用“path => /logs/log-%{+YYYY-MM-dd}.log”配置输出插件就可以每日生成一个文件。
……………
本文节选自《Elastic Stack应用宝典》,机械工业出版社2019年10月出版