使用ItelliJ IDEA构建Spark项目(Windows)
最近实习需要用到Graphx, 但是之前没有接触过Spark的相关知识,于是开始自学Spark。首先环境搭建就是一道坎,折腾来折腾去花了两天的时间才终于成功基于Scala和Maven 实现了WordCount,也算是Spark中的HelloWorld了吧。
环境搭建
首先我们需要搭建好相关的环境,包括:IntelliJ IDEA(官网上下载最新的就行了)、JDK(1.8)、Scala(2.12.12)、Spark(3.0.1)、Hadoop(2.7.4)Maven(如果你下载的是最新版的IDEA的话就不用下载了,因为IDEA里面已经自带了)(安装完后记得添加环境变量)
这里要注意版本问题,各个包之间的版本是有对应限定的,如果不想麻烦的话都下载和我上面标注好的版本就行了,本人目前使用是没有问题的。除此之外安装的时候还有一些小问题:启动spark的时候还是会提示找不到可执行的hadoop winutils.exe,这个时候要去网上下载好这个文件在hadoop\bin 中替换掉原文件就可以了。
最后我们在IDEA中安装Scala的插件:
在开始页面中的Plugins中找到Scala的插件然后安装就可以了:

项目编辑
首先新建一个项目,并在左边选择Maven, 然后选择 Project SDK(这里下拉框应该会自动生成可以选择的SDK,没有的话就手动选择之前下载的JDK的文件)。点击create from archetype 选择,点击Next。
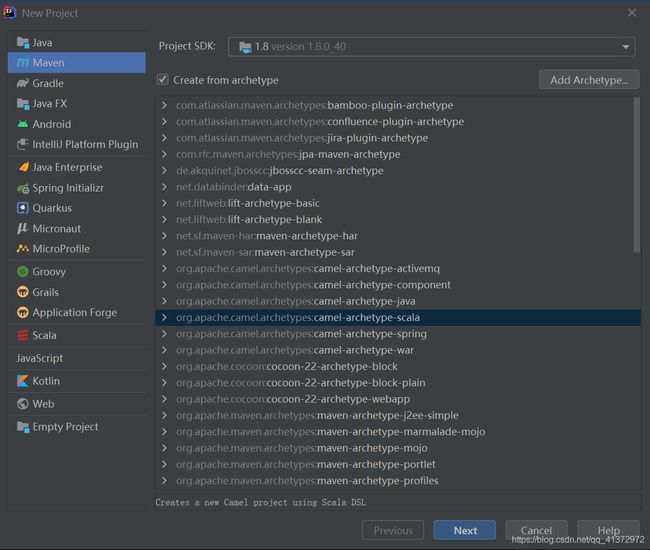
这里选择要创建项目的路径,然后填写项目的名称,然后点finish.
刚进去的时候我们先设置一下Plugins, 点击左上角的File->Settings->Plugins 看看有没有scala插件,有的话就不管,没有的话就装上去。

然后我们再设置一下各个sdk, Flie->Project Settings->Global Libraries 在这里将之前安装的scala-sdk装入。然后这里还要将Libraries设置一下File->Project Settings->Libraries 这里同样将scala-sdk装入,这些应该点击“+”号后都已经将sdk列出来了,这时点击sdk变蓝后确认就行了。
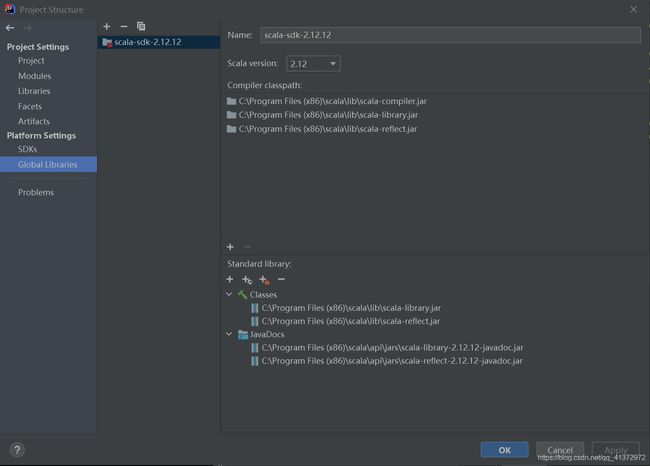

然后在File->Project Settings->SDKs中将jdk导入。
接下来就到了最关键的一步了,我们需要为这个项目配置依赖,只有配置了依赖,我们才能在项目中import 我们需要的库,配置需要在pom.xml中写出。只要我们在pom中写进了我们需要的一些库,maven会帮我们自动下载的,但是maven 默认的下载源在国外,所以下载经常断,导致无法正确的配置上我们需要的包,因此我建议在写pom 之前我们先设置国内的下载镜像地址。首先我们点击File->Settings->Build,Execution,Deployment->Build Tools->Maven. 这里有两个需要更改的地方:一个是User settings file 一个是Local repository.这里系统会默认两个路径,但是为了便于管理,我们还是把他们更改成我们自定义的路径。其中User settings file 中的.xml文件是我们的设置文件,我们将下述内容写进我们自定义的settings文件中:
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0
https://maven.apache.org/xsd/settings-1.0.0.xsd">
<mirrors>
<mirror>
<id>alimavenid>
<name>aliyun mavenname>
<url>http://maven.aliyun.com/nexus/content/groups/public/url>
<mirrorOf>centralmirrorOf>
mirror>
mirrors>
settings>

这样以来我们再下载依赖的包的时候就会默认在国内的镜像上面下载了。
最后再建立一个空的文件夹respository(这里注意这个文件夹的路径一定要和之前填写的Local repository对应,同理我们自己建的.xml文件也要和User settings file中填写的路径相对应)用来存放我们下载下来的依赖包。
到这一步我们终于可以将我们需要的依赖写到我们的项目里了,这里我给出我的pom,直接复制然后覆盖掉原来的pom文件就可以了:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.scala.sparkgroupId>
<artifactId>StatartifactId>
<version>1.0-SNAPSHOTversion>
<properties>
<spark.version>3.0.1spark.version>
<scala.version>2.12.12scala.version>
<hadoop.version>2.7.3hadoop.version>
properties>
<dependencies>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.12artifactId>
<version>3.0.1version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming_2.12artifactId>
<version>3.0.1version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.12artifactId>
<version>3.0.1version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-hive_2.12artifactId>
<version>3.0.1version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-mllib_2.12artifactId>
<version>3.0.1version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.scala-toolsgroupId>
<artifactId>maven-scala-pluginartifactId>
<version>2.15.2version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.8.0version>
<configuration>
<source>1.8source>
<target>1.8target>
configuration>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-surefire-pluginartifactId>
<version>2.19version>
<configuration>
<skip>trueskip>
configuration>
plugin>
plugins>
build>
project>
当我们把依赖写上去的时候Maven会帮我自动加载进项目,如果respository中没有的话Maven会帮我们自动下载,所以第一次配置依赖的时候会下载一会儿,我们只要耐心的等待一下就可以了。全部下载完毕并装载之后,我们可以发现之前红色的那些包现在都变成白色的了,这就意味着我们的依赖已经成功导入了。
前戏这么久终于可以进入正题了,因为这是第一次所以会有些麻烦。下面开始编写WordCount的主要程序,我们首先在下图所示的scala文件夹中建立一个Scala Cass文件,然后开始编写代码:
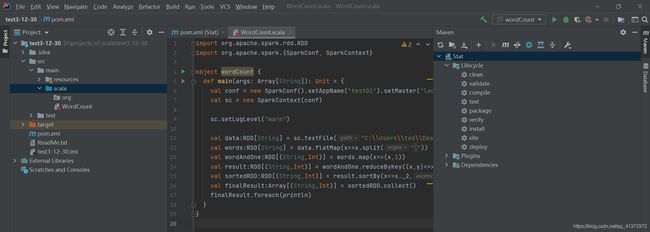
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
object wordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("test01").setMaster("local[2]")
val sc = new SparkContext(conf)
sc.setLogLevel("warn")
val data:RDD[String] = sc.textFile("C:\\Users\\ted\\Desktop\\xxx.txt")
val words:RDD[String] = data.flatMap(x=>x.split(" "))
val wordAndOne:RDD[(String,Int)] = words.map(x=>(x,1))
val result:RDD[(String,Int)] = wordAndOne.reduceByKey((x,y)=>x+y)
val sortedRDD:RDD[(String,Int)] = result.sortBy(x=>x._2,false)
val finalResult:Array[(String,Int)] = sortedRDD.collect()
finalResult.foreach(println)
}
}
这里textFile填写我们想要统计的文档的路径即可。
到这里为止我们的整个项目就写完了,右键文件然后Run就可以了。

文件打包
最后我们把我们编辑好的项目打包成jar文件。
我们点击右侧的Maven然后选择Stat->lifecycle->package双击就可以了,打包好的jar文件在我们项目下面的target文件夹下面。
最后我们用Spark运行打包好的jar文件,方法如下:进入我们安装Spark的文件夹下的bin文件夹,例如我的是C:\BigData\spark-3.0.1-bin-hadoop2.7\bin,在这里打开powershell, 输入spark-submit --class WordCount xxx.jar(将xxx替换成你之前生成的jar文件的路径)然后点击运行就可以了。最后同样也是能输出我们想要的结果:
![]()

到此为止终于是完成了Spark版的"HelloWorld"!!!