Python tkinter库窗口化爬虫
Python tkinter库窗口化爬虫
- 介绍
-
- 获取时光网Headers
- 代码
- 下厨房窗口化爬虫
- 参考资料
介绍
利用爬虫和tkinter库爬取时光网.HTML文件,并用窗口显示出来。
获取时光网Headers
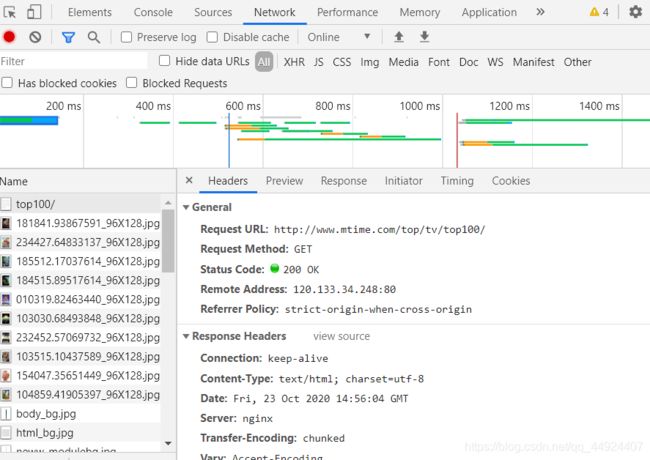
网址:时光网
打开时光网–>找到开发者工具–>点击Network–>ctrl+R–>点击top100/–>下拉找到Request Headers–>复制Request Headers下所有内容
注意:时光网Headers要复制自己电脑上实时的Headers,时光网有反爬虫机制
如下图:
代码
注意:用的时候修改一下a,也即时光网的Headers
import tkinter as tk
import requests
from bs4 import BeautifulSoup
import csv
#http://www.mtime.com/top/tv/top100/
a = '''Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cache-Control: max-age=0
Connection: keep-alive
Cookie: _userCode_=202010232134492918; _userIdentity_=202010232134498209; _tt_=12263541D009AEE729653F9258EDB8C8; DefaultCity-CookieKey=880; DefaultDistrict-CookieKey=0; Hm_lvt_6dd1e3b818c756974fb222f0eae5512e=1603460090; Hm_lpvt_6dd1e3b818c756974fb222f0eae5512e=1603460090; __utma=196937584.2019190126.1603460090.1603460090.1603460090.1; __utmc=196937584; __utmz=196937584.1603460090.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utmt=1; __utmt_~1=1; __utmb=196937584.2.10.1603460090
Host: www.mtime.com
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'''
class Spider():
def get_url(self):
s = "输入的网址为:"
url = self.entry.get()
self.text.insert("insert", s)
self.text.insert("insert", url)
self.text.insert(tk.INSERT, '\n')
self.spider_(url)
def get_headers(self, header_raw):
return dict(line.split(": ", 1) for line in header_raw.split("\n"))
def spider_(self, url):
headers = self.get_headers(a)
res = requests.get(url, headers=headers)
print(res.status_code)
soup = BeautifulSoup(res.text, "html.parser")
#list =
self.text.insert("insert", soup.prettify())
def Windows(self):
self.root = tk.Tk()
self.root.title("Network Crawler")
self.root.geometry("1000x600+300+100")
self.lb = tk.Label(self.root, text="输入网页地址(格式示范:http://270005.ifund.jrj.com.cn/forum270005_)",
height=3, width=68, font=("宋体", 12))
self.entry = tk.Entry(self.root, highlightcolor='black',
highlightthickness=1, width=100, bd=5)
self.button1 = tk.Button(self.root, text=" 抓取网页内容 ", bd=5,
font=('黑体', 13, 'bold'), bg="light grey", command=self.get_url)
self.text = tk.Text(self.root, height=50, width=142)
self.lb.pack(anchor="center")
self.entry.pack(anchor="center")
self.button1.pack(anchor="center")
self.text.pack(anchor="center")
self.root.mainloop()
if __name__ == '__main__':
spider = Spider()
spider.Windows()
下厨房窗口化爬虫
headers同时光网一样需要注意
import tkinter as tk
import requests
from bs4 import BeautifulSoup
#http://www.xiachufang.com/explore/
txt_file = open("text.txt", "w", newline='', encoding='utf-8')
txt_file.write("编号\t\t\t\t\t文本链接\t\t\t\t\t\t\t文本(菜名\t食材)\n")
a = '''Accept: text/html,appAccept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cache-Control: max-age=0
Connection: keep-alive
Cookie: bid=F45eA4fq; sajssdk_2015_cross_new_user=1; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%221755d98b9e0b62-01cb7aa9607138-c781f38-1327104-1755d98b9e123d%22%2C%22%24device_id%22%3A%221755d98b9e0b62-01cb7aa9607138-c781f38-1327104-1755d98b9e123d%22%2C%22props%22%3A%7B%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%7D; Hm_lvt_ecd4feb5c351cc02583045a5813b5142=1603593092; Hm_lpvt_ecd4feb5c351cc02583045a5813b5142=1603593092; __utma=177678124.1859529596.1603593093.1603593093.1603593093.1; __utmc=177678124; __utmz=177678124.1603593093.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utmt=1; __utmb=177678124.1.10.1603593093; __gads=ID=83a02b4f5052fde8-229b817564c40018:T=1603593094:RT=1603593094:S=ALNI_Ma_mJn7f_Dbkhc7Ee4OMjqRyGTYdg
Host: www.xiachufang.com
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'''
class Spider():
#获取网址,并将输入框里的网址传给爬虫
def get_url(self):
s = "输入的网址为:"
url = self.entry.get()
self.text.insert("insert", s)
self.text.insert("insert", url)
self.text.insert(tk.INSERT, '\n')
self.spider_(url)
#转换headers
def get_headers(self, header_raw):
return dict(line.split(": ", 1) for line in header_raw.split("\n"))
#获取get_url,执行爬虫,打印到文本框
def spider_(self, url):
list_data = []
count = 0
try:
for i in range(1, 10):
headers = self.get_headers(a)
url1 = url + "?page="+str(i)
res = requests.get(url1, headers=headers)
print(res.status_code)
soup = BeautifulSoup(res.text, "html.parser")
tag_name = soup.find_all("p", class_="name")
tag_ingredients = soup.find_all("p", class_="ing ellipsis")
for x in range(len(tag_name)):
list_food = "{}\t{}\t{}\n".format("http://www.xiachufang.com" + tag_name[x].find('a')['href'],
tag_name[x].text.strip()
, tag_ingredients[x].text.strip())
list_data.append(list_food)
for food in list_data:
data = "{}\t{}\n".format(count, food)
txt_file.write(data)
count += 1
self.text.insert("insert", data)
self.text.insert(tk.INSERT, '\n')
except:
self.text.insert("insert", "error")
self.text.insert(tk.INSERT, '\n')
#窗口创建
def Windows(self):
self.root = tk.Tk()
self.root.title("Network Crawler")
self.root.geometry("1000x600+300+100")
self.lb = tk.Label(self.root, text="输入网页地址(格式示范:http://270005.ifund.jrj.com.cn/forum270005_)",
height=3, width=68, font=("宋体", 12))
self.entry = tk.Entry(self.root, highlightcolor='black',
highlightthickness=1, width=100, bd=5)
self.button1 = tk.Button(self.root, text=" 抓取网页内容 ", bd=5,
font=('黑体', 13, 'bold'), bg="light grey", command=self.get_url)
self.text = tk.Text(self.root, height=50, width=142)
self.lb.pack(anchor="center")
self.entry.pack(anchor="center")
self.button1.pack(anchor="center")
self.text.pack(anchor="center")
self.root.mainloop()
if __name__ == '__main__':
spider = Spider()
spider.Windows()
参考资料
给大家分享一篇 tkinter python(图形开发界面)
python 窗口化网页爬虫实践
Python tkinter(五) 文本框(Entry)组件的属性说明及示例
python3 爬虫实战:为爬虫添加 GUI 图像界面 之 tkinter
python封装爬虫使用tkinter图形化界面
箬笠蓑衣Python Tkinter Grid布局管理器详解
Python tkinter – 第19章 进度条控件(Progressbar)