Java零基础学习之路(四)Java数据类型
本章节目标:
理解数据类型的作用。Java中包括哪些数据类型?常见的八种基本数据类型都有哪些?会用八种基本数据类型声明变量?什么是二进制?原码反码补码是什么?什么是字节?byte类型取值范围?什么是字符编码方式?每种数据类型在使用时的注意事项?基本数据类型之间的转换?
知识框架:
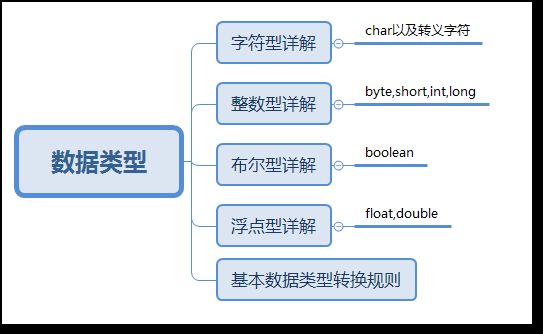
Java的数据类型概述
几乎所有的编程语言中都会有数据类型,什么是数据类型呢?软件的存在主要是进行数据的处理,现实生活中的数据会有很多,所以编程语言对其进行了分门别类,然后不同的数据类型的数据会给其分配不同大小的空间进行存储。换句话说,java中的数据类型作用就是指导java虚拟机在程序运行阶段到底应该给该变量分配多大的内存空间。
Java中的数据类型包括两种,分别是:
● 基本数据类型
● 引用数据类型
Java中的基本数据类型又包括四类8种:
● 整数型(不带小数的数字):byte,short,int,long
● 浮点型(带小数的数字):float,double
● 字符型(文字,单个字符):char
● 布尔型(真和假):boolean
java中除了以上的8种基本数据类型之外,其它的数据类型均属于引用数据类型,也就是说字符串在java中不属于基本数据类型,而属于引用数据类型。请看八种基本数据类型对照表:
| 数据类型 |
占用bit位 |
取值范围 |
缺省默认值 |
| byte(字节型) |
1 |
[-128~127] |
0 |
| short(短整型) |
2 |
[-32768~32767] |
0 |
| int(整型) |
4 |
[-2147483648~2147483647] |
0 |
| long(长整型) |
8 |
|
0L |
| float(单精度) |
4 |
|
0.0f |
| double(双精度) |
8 |
|
0.0 |
| boolean(布尔型) |
1 |
true、false |
false |
| char(字符型) |
2 |
[0~65535] |
‘\u0000’ |
接下来我们普及一下计算机基本知识,计算机在任何情况下都只能识别二进制,因为计算机毕竟是一台通电的机器,电流只有正极、负极,所以只能表示两种情况,也就是1和0。什么是二进制呢?满2进一位,请看对照表
| 十进制 |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
| 二进制 |
0 |
1 |
10 |
11 |
100 |
101 |
110 |
111 |
1000 |
1001 |
1010 |
1011 |
十进制和二进制之间的转换规则:
● 十进制转换成二进制:比方说十进制数65转换成二进制代码,我们可以使用短除法,65对2整除商32余数为1,把1写在旁边,接着32对2整除商16余数为0,把0写在旁边,用16整除2商0余数为0,把0写在旁边,这样进行下去直至商为0时为止。然后把余数逆序排列就得到了65的二进制代码。
● 二进制转换成十进制:比方说二进制代码为1000001的十进制数是多少呢?可以采用按权相加的方法,对于二进制代码1000001首先从右边第一位起对应2的零次方,第二位对应2的一次方,以此类推,把相应的数位与权值相乘得到的积相加即可,即2^0*1+0*2^1+0*2^2+0*2^3+0*2^4+0*2^5+1*2^6=65
接下来我们来看一下byte类型的取值范围:首先byte属于字节型,占用空间大小是1个字节byte,1个byte是8个bit位,二进制位中的一个1或者一个0就是一个bit位,而java中的数字有正负之分,二进制位中最左边的数字表示符号位,0表示正数,1表示负数,所以byte类型最大值是:01111111,将这个二进制位转换为十进制是:127。byte类型最小值是-128,也就是说1个字节可以表示256种不同形式。另外还需要给大家普及一下计算机的容量换算单位:
1byte = 8bit
1KB = 1024byte
1MB = 1024KB
1GB = 1024MB
1TB = 1024GB
对于以上的八种基本数据类型来说,其中七种类型byte,short,int,long,float,double,boolean计算机表示起来是很容易的,因为这七种类型底层直接就是数字,十进制的数字和二进制之间有固定的转换规则,其中boolean类型只有true和false,而true底层实际上是1,false底层实际上是0。除了以上的七种数据类型之外,还有一种类型叫做字符型char,这个对于计算机来说表示起来就不是那么容易了,因为字符毕竟是现实世界当中的文字,计算机是如何表示文字的呢?
起初的计算机实际上只支持数字的,因为计算机起初就是为了科学计算,随着计算机的发展,为了让计算机起到更大的作用,因此我们需要让计算机支持现实世界当中的文字,这个时候某个标准协会就制定了字符编码(字符集),字符编码就是一张对照表,在这个对照表上描述了某个文字与二进制之间的转换关系。
最初的时候美国标准协会制定了ASCII码,ASCII码采用1个字节编码,大家是否还记得1个字节可以表示256种不同的形式,对于美国来说这个足够了,因为英文单词就是由26个英文字母拼凑而成,大小写全部才52个,再加上标点符号也不会超过256个。ASCII码中规定’a’对应97,’b’对应98,以此类推,’A’对应65,’B’对应66,以此类推,’0’字符对应48,’1’字符对应49,以此类推,这些常见的编码还是需要大家记住的。
什么是编码?什么是解码?我们拿’a’来解释:
● ‘a’ ----(以ASCII字符集进行编码)----> 01100001
● 01100001----(以ASCII字符集进行解码)----> ‘a’
大家一定要注意:编码和解码要采用同一种字符编码方式(要采用同一个对照表),不然会出现乱码。
随着计算机的不断发展,为了让计算机支持更多国家的语言,国际标准组织又制定了ISO-8859-1字符集,又被称为latin-1,向上兼容ASCII码,仍不支持中文,主要支持西欧语言。
当计算机发展到亚洲的时候,计算机开始支持简体中文、繁体中文、日本语、朝鲜语等,其中支持简体中文的字符集包括:GB2312 < GBK < GB18030,它们的容量大小不同。支持繁体中文的大五码Big5等。
后来,国际组织制定了一种字符编码方式,叫做Unicode编码,这种编码方式统一了全球所有国家的文字,具体的实现包括:UTF-8,UTF-16,UTF-32等。
java为了国际化,为了支持所有国家的语言,所以java采用的编码方式为Unicode编码。例如’中’对应的Unicode码是’\u4e2d’。在实际开发中几乎所有的团队都会使用Unicode编码方式,因为这种方式更通用,兼容性更好。
Java字符类型
字符型char在java语言中占用2个字节,char类型的字面量必须使用半角的单引号括起来,取值范围为[0-65535],char和short都占用2个字节,但是char可以取到更大的正整数,因为char类型没有负数。java语言中的char类型变量可以容纳一个汉字。请看以下程序:
public class CharTest01 {
public static void main(String[] args) {
char c1 = 'a';
System.out.println(c1);
System.out.println(c1 + 1);
char c2 = '中';
System.out.println(c2);
char c3 = "中";
System.out.println(c3);
char c4 = 97;
System.out.println(c4);
}
}编译报错:

图4-1:编译报错
以上代码编译报错:原因是类型不兼容,使用双引号括起来的一定是字符串类型,不能赋值给char类型的变量。将错误代码注释之后并运行:
运行结果如下图所示:

图4-2:char类型测试
我来解释一下以上的输出结果:c1 + 1为什么是98呢?因为c1是char类型,1是int类型,char类型和int类型混合运算的时候char类型会自动转换成int类型,然后再做运算,a对应的ASCII码是97,所以最终结果是98。另外还有一行代码char c4 = 97,由于c4是char类型,所以会把97看做ASCII码,所以c4是’a’字符。
接下来,我们来看一看关于转义字符:\,请看以下代码:
public class CharTest02 {
public static void main(String[] args) {
char c1 = 't';
System.out.println("这是一个普通的字符 = " + c1);
char c2 = '\t';
System.out.println("abc" + c2 + "def");
}
}编译通过了,并且运行结果如下图所示:![]()
![]()

图4-3:\t
表面看起来’\t’是由两个字符构成,按说应该编译报错,因为它毕竟是一个字符串,最终的结果编译通过了,这还是说明’\t’是一个字符,所以\具有转义功能,根据以上输出结果可以看出\t是制表符。接下来我们来看一看其它的转义字符。
public class CharTest03 {
public static void main(String[] args) {
System.out.println("换行符 = hello\nworld");
System.out.println("普通的单引号 = " + '\'');
System.out.println("普通的斜杠=" + '\\');
System.out.println("普通的双引号=" + "\"");
System.out.println('\u4e2d');
}
}运行结果如下图所示:![]()
![]()

图4-4:转义字符
通过以上的测试:\n表示换行符,\’表示普通的单引号字符,\\表示一个普通的\字符,\”表示一个普通的双引号字符,\u后面的十六进制是文字的Unicode编码。
Java整数类型
整数型数据在java中有三种表示方式,分别是十进制、八进制、十六进制。默认为十进制,以0开始表示八进制,以0x开始表示十六进制。
● 十进制:0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17...
● 八进制:0,1,2,3,4,5,6,7,10,11,12,13,14,15,16,17,20,21...
● 十六进制:0,1,2,3,4,5,6,7,8,9,a,b,c,d,e,f,10,11...
在java语言当中,整数型字面量被当做int类型处理,如果想表示long类型则需要在字面量后面添加L/l,建议大写L,因为小写l和1不好区分。请看以下程序:
public class IntegerTypeTest01 {
public static void main(String[] args) {
//十进制
int a = 10;
System.out.println("a = " + a);
//八进制
int b = 010;
System.out.println("b = " + b);
//十六进制
int c = 0x10;
System.out.println("c = " + c);
}
}运行结果如下图所示:

图4-5:十、八、十六进制
接下来继续看以下代码:
public class IntegerTypeTest02 {
public static void main(String[] args) {
//声明一个int类型的变量a
//100被默认当做int类型处理
//以下代码不存在类型转换
int a = 100;
//100被默认当做int类型处理,占用4个字节
//b变量是long类型,默认可容纳8个字节
//小容量转换成大容量,叫做自动类型转换
long b = 100;
//b变量long类型,占用8个字节
//c变量int类型,占用4个字节
//大容量不能直接赋值给小容量,编译报错了
//int c = b;
//强制类型转换需要添加强制类型转换符
//强制类型转换时可能引起精度损失,谨慎使用
int c = (int)b;
//a是int类型
//b是long类型
//c是int类型
//多种数据类型混合运算时先转换成容量最大的再做运算
//最终的结果是long类型,大容量无法直接赋值给小容量
//所以编译报错了
//int d = a + b + c;
//解决以上编译错误
int d = (int)(a + b + c);
System.out.println("d = " + d);
//或者
long d2 = a + b + c;
System.out.println("d2 = " + d2);
//100L被当做long类型处理
//x变量是long类型
//不存在类型转换
long x = 100L;
System.out.println("x = " + x);
}
}运行结果如下图所示:

图4-6:整数型测试
通过以上代码的学习,我们知道小容量转换成大容量叫做自动类型转换,大容量转换成小容量叫做强制类型转换,强制类型转换要想编译通过必须添加强制类型转换符,虽然编译通过了,但运行阶段可能出现精度损失,谨慎使用。
接下来我们一起来看看精度损失的情况:
运行结果如下图所示:
![]()
图4-7:精度损失
4个字节的int类型300强转为1个字节的byte类型,最终的结果是44,为什么呢?首先300对应的二进制码是:00000000 00000000 00000001 00101100,强制类型转换的时候会变成1个字节,这个时候底层是将前3个字节砍掉了,也就是最后的二进制码是:00101100,这个二进制码对应的是44。
接下来我们再来看一下如果精度损失之后成为负数的情况:
public class IntegerTypeTest03 {
public static void main(String[] args) {
int a = 300;
byte b = (byte)a;
System.out.println("b = " + b);
}
}运行结果如下图所示:
![]()
图4-8:精度损失
为什么以上的运行结果是-106呢?那是因为计算机在任何情况下都是采用二进制补码的形式存储数据的(至于为什么采用二进制补码形式存储数据,这里就不再赘述了,毕竟我们不是做学术研究)。
计算机二进制编码方式包括原码、反码、补码。对于正数来说原码、反码、补码是同一个。对于负数来说呢?负数的反码是在其原码的基础上, 符号位不变,其余各个位取反,例如:-15的原码是:10001111,-15反码是:11110000。负数的补码是其反码再加1。例如:-15的补码是11110000加1:11110001。换句话说-15最终在计算机上会采用11110001二进制来表示。
我们再来看看以上的程序:int a = 150。4个字节的150对应的二进制是:00000000 00000000 00000000 10010110,强转时前3个字节砍掉,最终计算机存储的二进制为:10010110,我们之前说过最终存储在计算机中的是二进制补码形式,也就是说10010110现在是二进制补码形式,我们通过补码推出原码,负数的补码是反码+1,所以10010110减1就是反码10010101,反码的符号位不变,其余位取反就能得出原码:11101010,而这个值就是-106。
接下来我们再来看一段程序,分析以下程序错在哪里,为什么以及怎么解决?
public class IntegerTypeTest05 {
public static void main(String[] args) {
long num = 2147483648;
}
}编译报错了:
![]()
图4-9:编译错误提示信息
以上程序编译报错的原因是:java程序见到2147483648这个整数的时候,默认将其当做int类型来处理,但这个数字本身已经超出了int类型的取值范围,所以编译报错了,注意:这里编译报错的原因并不是说long类型存不下,long类型的变量完全可以存储这个数字,以上程序出现的错误是在赋值之前,还没有进行到赋值运算,数字本身已经超出int类型范围,自己崩掉了。怎么解决以上的问题呢?其实很简单,我们只要让java程序认为2147483648是一个long类型的数据就行了,也就是说在该数字后面添加L问题就解决了(long num = 2147483648L;)。
再来看一看整数类型还有没有其它的知识点要学习,请看以下程序:
public class IntegerTypeTest06 {
public static void main(String[] args) {
byte b = 127;
short s = 32767;
char c = 65535;
byte b1 = 128;
short s1 = 32768;
char c1 = 65536;
}
}编译报错了:

图4-10:编译错误提示信息
通过以上测试,大家需要记住一个结论:当一个整数型的字面量没有超出byte,short,char的取值范围,可以将该字面量直接赋值给byte,short,char类型的变量。
Java布尔类型
在Java语言中布尔类型的值只包括true和false,没有其他值,不包括1和0,布尔类型的数据在开发中主要使用在逻辑判断方面,例如:如果外面在下雨,我出门带一把雨伞。如果明天休息,咱们就一起出去玩耍吧。请看一段程序(以下程序中可能会使用控制语句,后面会详细讲,先能看个大概就行):
public class BooleanTest {
public static void main(String[] args) {
boolean isRain = true;
if(isRain){
System.out.println("外面下雨了,出门要带一把雨伞哦!");
}else{
System.out.println("外面天气晴朗,走起吧!");
}
boolean sex = true;
if(sex){
System.out.println("哥们你好");
}else{
System.out.println("姐们你好");
}
}
}运行结果如下图所示:

图4-11:运行结果
再看一段代码:
public class BooleanTest {
public static void main(String[] args) {
boolean flag = 1;
}
}编译报错了:

图4-12:编译错误信息
以上错误信息提示:类型不兼容,显然boolean类型的值只有true和false,至少在java中不含有其他值。
再来看一段boolean类型的应用:
public class BooleanTest {
public static void main(String[] args) {
java.util.Scanner s = new java.util.Scanner(System.in);
System.out.print("请输入第1个整数 : ");
int a = s.nextInt();
System.out.print("请输入第2个整数 : ");
int b = s.nextInt();
if(a > b){
System.out.println(a + " - " + b + " = " + (a - b));
}else{
System.out.println(b + " - " + a + " = " + (b - a));
}
}
}运行结果如下图所示:

图4-13:布尔类型的使用
说明:在以上程序当中出现的System.out.print()可以输出信息但不换行,之前我们用的System.out.println()可以输出信息并换行。以上代码当中还有一段程序是专门用来接收用户键盘输入的,这段代码大家目前照抄就行,这里简单说一下:
● java.util.Scanner s = new java.util.Scanner(System.in);这行代码表示创建键盘扫描器对象,从键盘上扫描数据。
● int a = s.nextInt();执行到这行代码的时候,程序会停下来等待用户的输入。这个方法只能接收整数类型的数据。
● 另外扩展一下:String str = s.next();这行代码是专门用来接收用户输入字符串类型数据的。
Java浮点类型
浮点型数据实际上在内存中存储的时候大部分情况下都是存储了数据的近似值,为什么呢?这是因为在现实世界中存在无穷的数据,例如:3.333333333333333333..,数据是无穷的,但是内存是有限的,所以只能存储近似值,float单精度占4个字节,double双精度占8个字节,相对来说double精度要高一些。由于浮点型数据存储的是近似值,所以一般判断两个浮点型数据是否相等的操作很少。
在java语言中有这样的一条规定:只要是浮点型的字面量,例如1.0、3.14等默认会被当做double类型来处理,如果想让程序将其当做float类型来处理,需要在字面量后面添加f/F。请看以下代码:
public class DoubleTest {
public static void main(String[] args) {
float f = 3.0;
}
}编译报错了:

图4-14:编译错误提示信息
为什么会编译报错呢?那是因为3.0默认被当做double类型来处理,占用8个字节,前面的f变量是float类型占用4个字节,大容量无法直接赋值给小容量。怎么修改呢?请看代码:
public class DoubleTest {
public static void main(String[] args) {
//float f = 3.0;
//第一种方案
float f = 3.0F;
System.out.println("f = " + f);
//第二种方案
float f1 = (float)3.0;
System.out.println("f1 = " + f1);
}
}运行结果如下图所示:

图4-15:运行结果
以上程序的第一种方案在3.0后面添加了F,3.0F被当做float类型来处理。第二种方案是进行了强制类型转换,第二种方案可能会存在精度损失。
Java基本数据类型转换
Java基本数据类型之间是存在固定的转换规则的,现总结出以下6条规则,无论是哪个程序,将这6个规则套用进去,问题迎刃而解:
● 八种基本数据类型中,除boolean类型不能转换,剩下七种类型之间都可以进行转换;
● 如果整数型字面量没有超出byte,short,char的取值范围,可以直接将其赋值给byte,short,char类型的变量;
● 小容量向大容量转换称为自动类型转换,容量从小到大的排序为:byte < short(char) < int < long < float < double
注:short和char都占用两个字节,但是char可以表示更大的正整数;
● 大容量转换成小容量,称为强制类型转换,编写时必须添加“强制类型转换符”,但运行时可能出现精度损失,谨慎使用;
● byte,short,char类型混合运算时,先各自转换成int类型再做运算;
● 多种数据类型混合运算,各自先转换成容量最大的那一种再做运算;
接下来,根据以上的6条规则,我们来看一下以下代码,指出哪些代码编译报错,以及怎么解决:
public class TypeConversionTest {
public static void main(String[] args) {
byte b1 = 1000;
byte b2 = 20;
short s = 1000;
int c = 1000;
long d = c;
int e = d;
int f = 10 / 3;
long g = 10;
int h = g / 3;
long m = g / 3;
byte x = (byte)g / 3;
short y = (short)(g / 3);
short i = 10;
byte j = 5;
short k = i + j;
int n = i + j;
char cc = 'a';
System.out.println("cc = " + cc);
System.out.println((byte)cc);
int o = cc + 100;
System.out.println(o);
}
}编译报错,错误信息如下所示:

图4-16:类型转换编译错误提示信息
如何修改,请看以下代码:
public class TypeConversionTest {
public static void main(String[] args) {
//1000超出byte取值范围,不能直接赋值
//byte b1 = 1000;
//如果想让上面程序编译通过,可以手动强制类型转换,但程序运行时会损失精度
byte b1 = (byte)1000;
//20没有超出byte取值范围,可以直接赋值
byte b2 = 20;
//1000没有超出short取值范围,可以直接赋值
short s = 1000;
//1000本身就是int类型,以下程序不存在类型转换
int c = 1000;
//小容量赋值给大容量属于自动类型转换
long d = c;
//大容量无法直接赋值给小容量
//int e = d;
//加强制类型转换符
int e = (int)d;
//int类型和int类型相除最后还是int类型,所以结果是3
int f = 10 / 3;
long g = 10;
//g是long类型,long类型和int类型最终结果是long类型,无法赋值给int类型
//int h = g / 3;
//添加强制类型转换符
int h = (int)(g / 3);
//long类型赋值给long类型
long m = g / 3;
//g先转换成byte,byte和int运算,最后是int类型,无法直接赋值给byte
//byte x = (byte)g / 3;
//将以上程序的优先级修改一下
byte x = (byte)(g / 3);
short y = (short)(g / 3);
short i = 10;
byte j = 5;
//short和byte运算时先各自转换成int再做运算,结果是int类型,无法赋值给short
//short k = i + j;
int n = i + j;
char cc = 'a';
System.out.println("cc = " + cc);
//将字符型char转换成数字,'a'对应的ASCII是97
System.out.println((byte)cc);
//char类型和int类型混合运算,char类型先转换成int再做运算,最终197
int o = cc + 100;
System.out.println(o);
}
}运行结果如下图所示:

图4-17:类型转换测试