数据增强调研
文章目录
- 数据增强调研报告
-
- 一、常用的增强技术
-
- (一)几何变换
- (二)颜色空间转换
- 二、一般增强技术
-
- (一)内核过滤器(Kernel filters)
- (二)混合图像(mixing image)[5]
- (三)、高级增强技术
-
- 一、特征空间增强(Feature space augmentation)
- (二)、Adversarial training对抗训练
- (三)GAN‑based Data Augmentation[10][11]
- (四)、神经风格转移[11] Neural Style Transfe
- (五)、元学习[2][13]
- 四、总结
- 五、参考文献
数据增强调研报告
使用深度学习解决问题的一个常见障碍是训练模型所需的数据量。对大数据的需求是因为模型中有大量参数需要学习,在有限数据的情况下,数据增强至关重要。数据增强方法从问题的根源——训练数据集——开始进行。这是在假设可以通过扩充从原始数据集中提取更多信息的情况下完成的。这些增强通过数据扭曲或过采样人为地扩大了训练数据集的大小。数据扭曲增强是对现有图像进行转换,以便保留它们的标签。这包括几何和颜色转换,随机擦除,对抗性训练,和神经风格转移。过采样增强是创建合成实例,并将它们添加到训练集中。这包括混合图像、特征空间扩展和生成性对抗网络。过采样和数据扭曲扩展并不形成相互排斥的二分法。例如,GAN样本可以随机裁剪堆叠,以进一步扩大数据集。
本次调查中列出的增强是几何变换、颜色空间变换、核过滤器、混合图像、随机擦除、特征空间增强、对抗训练、基于GAN的增强、神经风格转移和元学习方案。
一、常用的增强技术
(一)几何变换
优点在于对于训练数据中存在的位置偏差,几何变换是非常好的解决方案。如果存在位置偏差,例如在面部识别数据集中,每个面部都完美地位于框架的中心,几何变换是一个很好的解决方案。除了克服位置偏差的强大能力之外,几何变换也很有用,因为它们易于实现,在许多图像处理库可以让水平翻转和旋转等操作轻松上手。
缺点在于几何变换的一些缺点包括额外的内存、变换计算成本和额外的训练时间。必须手动观察一些几何变换,如平移或随机裁剪,以确保它们没有改变图像的标签。最后,在医学图像分析等许多应用领域,训练数据与测试数据之间的偏差比位置和平移差异更复杂。因此,几何变换可以应用的位置和时间的范围相对有限。
挑战在于在几何增强过程中,我们要考虑几何扩增物的应用“安全性”,即它在转换后保留标签的可能性。因此在一定的失真幅度下保持标签不发生变换,也是目前存在的特定数据的扩增设计和开发通用扩增策略的挑战。
几何变换类型:
- 翻转
可以选择水平或垂直翻转图像。垂直轴翻转比水平翻转更常见。这种增强是最容易实现的方法之一,并且在诸如CIFAR-10和ImageNet这样的数据集上证明是有用的,但一些架构并不支持垂直翻转图像,例如:数字字符识别过程中(6&9)。
- 旋转
旋转增强是通过在1和359度之间的轴上左右旋转图像来完成的。旋转增强的安全性在很大程度上取决于旋转度参数。1到20度之间的轻微旋转可能对数字识别任务(如MNIST)有用,但随着旋转程度的增加,数据的标签在转换后不再保留。
- 3.平移
向左、向右、向上或向下移动图像是一种非常有用的变换,可以避免数据中的位置偏差。例如,如果一个数据集中的所有图像都是居中的,这在人脸识别数据集中是很常见的,这将需要在完全居中的图像上测试该模型。当原始图像在一个方向上平移时,剩余的空间可以用常数值(如0秒或255秒)填充,也可以用随机或高斯噪声填充。这种填充保留了图像增强后的空间维度。
- 缩放
图像可以被放大或缩小。放大时,放大后的图像尺寸会大于原始尺寸。大多数图像处理架构会按照原始尺寸对放大后的图像进行裁切。
- 剪裁
通过裁剪每个图像的中心块,裁剪图像可以用作具有混合高度和宽度尺寸的图像数据的实际处理步骤。此外,随机裁剪也可以用来提供非常类似于平移的效果。但随机裁剪和平移的区别在于,裁剪会减小输入的大小,例如(256,256) → (224,224),而平移会保留图像的空间维度。根据为裁剪选择的减少阈值,这可能不是一个保留标签的转换。
- 噪声注入
过拟合(Overfitting)经常会发生在神经网络试图学习高频特征(即非常频繁出现的无意义模式)的时候,而学习这些高频特征对模型提升没什么帮助。那么如何处理这些高频特征呢?一种方法是采用具有零均值特性的高斯噪声,它实质上在所有频率上都能产生数据点,可以有效的使高频特征失真,减弱其对模型的影响。
但这也意味着低频的成分(通常是你关心的特征)同时也会受到影响,但是神经网络能够通过学习来忽略那些影响。事实证明,通过添加适量的噪声能够有效提升神经网络的学习能力,即给图像添加噪声可以帮助CNNs学习更健壮的特征。
一个“弱化”的版本是椒盐噪声,它以随机的白色和黑色像素点呈现并铺满整个图片。这种方式对图像产生的作用和添加高斯噪声产生的作用是一样的,只是效果相对较弱。
(二)颜色空间转换
转换图像数据被编码成3个堆叠矩阵,每个矩阵的大小为高度×宽度。这些矩阵表示单个RGB颜色值的像素值。光照偏差是图像识别问题中最常见的挑战之一。因此,颜色空间变换的有效性,也称为光度变换,概念化相当直观。快速修复过亮或过暗的图像的方法是在图像中循环,并以恒定值减少或增加像素值。一个快速的颜色空间操作是拼接出单独的RGB颜色矩阵。另一种变换包括将像素值限制在某个最小值或最大值。数字图像中颜色的内在表现有助于许多增强策略。色彩空间转换也可以从图像编辑应用程序中获得。每个RGB颜色通道中图像的像素值被聚集以形成颜色直方图。此直方图可用于应用改变图像色彩空间特征的过滤器。色彩空间的增加给了创造力很大的自由。
改变图像的颜色分布可以很好地解决测试数据所面临的照明挑战。
与几何变换类似,颜色空间变换的缺点是增加了内存、变换成本和训练时间。此外,颜色变换可能会丢弃重要的颜色信息,因此并不总是保持标签的变换。例如,对于某些任务来说,颜色是一个非常重要的区别特征,然不和适宜的颜色空间转换将消除数据集中存在的有利于空间特征的颜色偏差,以至不利于图像分类识别
颜色空间变换可以从颜色抖动(随机颜色处理)、边缘增强和主成分分析三方面研究。
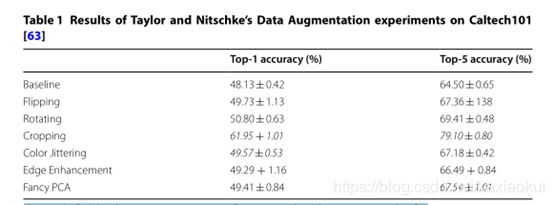
对于几何变换和颜色空间转换,泰勒和尼茨基[4]提供了一个关于几何变换和光度变换(颜色空间)有效性的比较研究,他们在Caltech101数据集上进行了4倍交叉验证,筛选出8421张大小为256 × 256的图像,并对这些扩展进行了测试(表1)研究表明,对于以下方法对比而说,剪裁在图像增强过程中的增强效果更加明显。
二、一般增强技术
(一)内核过滤器(Kernel filters)
内核过滤器是一种非常流行的图像处理技术,用于锐化和模糊图像。这些滤镜通过在图像上滑动n × n矩阵来工作,既可以使用高斯模糊滤镜(这会导致图像更模糊),也可以使用高对比度垂直或水平边缘滤镜(会导致边缘图像更清晰)。直观地说,在测试期间,用于数据增强的模糊图像可能导致对运动模糊的更高抵抗力。此外,为数据增强而锐化图像可以封装更多感兴趣对象的细节。锐化和模糊是对图像应用核过滤器的一些经典方式。内核过滤器是一个相对未被探索的数据扩充领域。这种技术的一个缺点是,它与CNNs的内部机制非常相似。中枢神经系统有参数内核,可以学习逐层表示图像的最佳方式。例如,可以用一个卷积层来实现像PatchShuffle正则化这样的东西。这可以通过修改标准卷积层参数来实现,使得填充参数保持空间分辨率,并且随后的激活层将像素值保持在0到255之间,这与将像素映射到0到1之间的值的sigmoid激活不同。内核过滤器可以更好地实现为网络的一个层,而不是通过数据扩充作为数据集的一个补充。
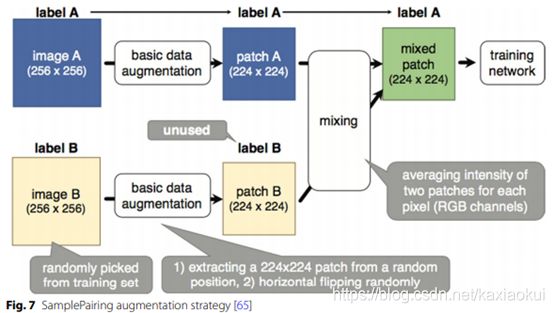
(二)混合图像(mixing image)[5]
混合图像是通过平均像素值将图像混合在一起是一种非常违反直觉的数据增强方法。
对人类观察者来说,这样做产生的图像看起来不像是有用的转换。然而,Ionue[7]展示了如何将样本配对发展成为有效的扩增策略。并在研究中发现的另一个细节是,当混合来自整个训练集的图像而不是来自完全属于同一类的实例时,获得了更好的结果。此外,样本配对可以叠加在其他增强技术之上。
方法:①一种非线性方法将图像组合成新的训练实例[6]:

②另一方法是随机裁剪图像并将裁剪后的图像连接在一起以形成新图像[8]:

这项技术的一个明显缺点是,从人类的角度来看,它没有什么意义。混合图像带来的性能提升很难理解或解释。可能解释是数据集大小的增加导致了诸如线和边之类的低级特征的更可靠表示。
(三)、随机擦除random erasing [9]
这一点受到dropout正规化的启发,随机擦除迫使模型学习有关图像的更多描述性特征,从而防止过拟合某个特定视觉特征。,随机擦除的好处在于可以确保网络关注整个图像,而不只是其中的一部分。随机擦除的一个缺点是不一定会保留标签。
在所讨论的几何变换、色彩空间变换、核滤波器、混合图像和随机擦除中,几乎所有这些变换都带有相关的失真幅度参数。在数据非常有限的领域,这可能会导致进一步的过度拟合。因此,重要的是要考虑搜索算法,以获得增强数据的最佳子集,从而训练深度学习模型。
(三)、高级增强技术
一、特征空间增强(Feature space augmentation)
神经网络的顺序处理可以被操纵,使得中间表示可以从网络整体中分离出来。可以提取和隔离完全连接的层中的图像数据的低维表示。特例:基于SMOTE类别不平衡的过采样法来进行特征空间的插值操作进行数据增强,就实验效果而言不算特别出众。此外:特征空间增强的一个缺点是很难解释矢量数据。可以使用自动编码器网络将新矢量恢复成图像;然而,这需要复制正在训练的CNN的整个编码部分。对于深度中枢神经系统,这导致大量的自动编码器,训练起来非常困难和耗时。最后,Wong等人[14]发现,当可以在数据空间中变换图像时,数据空间增强将优于特征空间增强。即,不建议使用。
(注SMOTE[1](合成少数类过采样技术)是一种流行的增强,用于缓解阶级不平衡的问题。它是基于随机过采样算法的一种改进方案,由于随机过采样采取简单复制样本的策略来增加少数类样本,这样容易产生模型过拟合的问题,即使得模型学习到的信息过于特别(Specific)而不够泛化(General),SMOTE算法的基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中。
缺点: 一是在近邻选择时,存在一定的盲目性。即如何确定K值,才能使算法达到最优这是未知的。 另外,该算法无法克服非平衡数据集的数据分布问题,容易产生分布边缘化问题。)
(二)、Adversarial training对抗训练
对抗训练是使用两个或多个网络的框架,这些网络的损失函数中编码有不同的目标,通过限制敌对网络可用的扩充和扭曲集,它可以学习产生导致错误分类的扩充,从而形成有效的搜索算法。这些增强对于加强分类模型中的弱点是有价值的。因此,对抗训练是一种有效的数据增强搜索技术。但是实际应用中其实提高不一定明显,因为自然对抗样本的数目没有那么多。而NIPS的对抗攻击大赛很多从神经网络的学习策略下手,进行梯度攻击,更加偏向于人为的攻击了,对于普适的检测性能提高意义反而不大,更强调安全需求高的场合。即对抗训练虽然是有效的搜索技术,但实用率当前来讲,并不高
(三)GAN‑based Data Augmentation[10][11]
GAN可以用作过采样技术来解决类不平衡的问题。且用于无监督异常检测。通过对罕见的正常样本(发生概率小的样本)进行过采样,GANs能够降低异常检测的假阳性率。但很难从当前的前沿架构中获得高分辨率输出。增加生成器生成的图像的输出大小可能会导致训练不稳定和不收敛。此外,训练过程中仍需要大量的数据来训练。因此,根据初始数据集的有限程度,GANs可能不是一个实用的解决方案。即目前来讲GAN虽然可以解决类不平衡问题,但因其训练仍需要大量数据,且难以获取高分辨率输出,也不太具有实用性。
(四)、神经风格转移[11] Neural Style Transfe
该算法的工作原理是通过操纵CNNS上的序列表示,使一幅图像的风格可以转移到另一幅图像,同时保留其原始内容。神经风格转移扩展了照明变化,并允许不同的纹理和艺术风格的编码。这使得数据增强的实践者在通过神经风格转移导出新图像时,可以决定从哪种风格中取样。但是选择哪种风格的样品可能是一项具有挑战性的任务,如果样式集太小,可能会给数据集带来进一步的偏差。且需要大量额外的内存和计算来转换和存储图像。运行时间非常慢,因此不适用于数据增强。即当前来讲神经风格转移可以扩充数据,扩展照明变化,更换图像风格,但扩展风格选取,和运行时间,计算量方面仍是很大的挑战,不具有实用性。
(五)、元学习[2][13]
深度学习研究中的元学习概念通常是指用神经网络优化神经网络的概念。利用进化和随机搜索算法是未来工作的一个有趣的领域。元学习中的优化策略则是:优化一组初始参数,或优化一个可以快速在每个任务上表现良好的模型,尝试用系统性的方法去学习一种在各种任务中都非常优秀的初始化参数。其可以避免迁移学习需要大量样本的情况,研究了如何从有限带标签数据中学习的问题,故元学习需要不同的数据组合模式,关注点转向收集许多种类的任务。
当前针对实验“元学习”的方法有很多,具体可以分为以下几类:
1、基于记忆Memory的方法。基本思路:因为要通过以往的经验来学习,那就可以通过在神经网络中添加Memory来实验。
2、基于预测梯度的方法。基本思路:Meta Learning的目的是实现快速学习,而实现快速学习的关键点是神经网络的梯度下降要准和快,那么就可以让神经网络利用以往的任务学习如何预测梯度,这样面对新的任务,只要梯度预测的准,那么学习就会快。
3、利用Attention注意力机制.基本思路:训练一个Attention模型,在面对新任务时,能够直接的关注最重要部分。
4、借鉴LSTM的方法.基本思路:LSTM内部的更新非常类似于梯度下降的更新,那么能否利用LSTM的结构训练处一个神经网络的更新机制,输入当前网络参数,直接输出新的更新参数
5、面向RL的Meta Learning方法.基本思路:既然Meta Learning可以用在监督学习,那么增强学习上又可以怎么做呢?能否通过增加一些外部信息的输入比如reward,和之前的action来实验。
6、通过训练一个base model的方法,能同时应用到监督学习和增强学习上
基本思路:之前的方法只能局限在监督学习或增强学习上,能否做出一个更通用的模型。
7、利用WaveNet的方法.基本思路:WaveNet的网络每次都利用了之前的数据,那么能否照搬WaveNet的方式来实现Meta Learning呢?就是充分利用以往的数据。
8、预测Loss的方法.基本思路:要让学习的速度更快,除了更好的梯度,如果有更好的Loss,那么学习的速度也会更快,因此,可以构建一个模型利用以往的任务来学习如何预测Loss。
四、总结
增加图像数据的有趣方法分为两大类: 数据扭曲和过采样。这些扩充中常用数据扩增方法——几何变换,颜色特征转换得到广泛应用,且很容易解释其作为数据增强方法的好处,而对于像mixing image此类的方法,尚未被解释其在扩增过程中的有效之因,同时对于特征空间增强,对抗学习,GAN,以及神经风格转移和迁移学习,其均存在耗费时间长,作为数据增强暂不实用的特点,故数据扩充的未来工作将集中在许多不同的领域,如建立扩充技术的分类法,提高GAN样本的质量,学习将元学习和数据扩充相结合的新方法,发现数据扩充和分类器体系结构之间的关系,并将这些原则扩展到其他数据类型等。除此之外,我们还可以通过调整分辨率大小,探索膨胀数据的子集以找到训练数据的最佳排序来解决数据扩增的问题。
五、参考文献
[1] Chawla N V, Bowyer K W, Hall L O, et al. SMOTE: synthetic minority over-sampling technique[J]. Journal of Artificial Intelligence Research, 2002, 16(1):321-357.
[2] Santoro, Adam, Bartunov, Sergey, Botvinick, Matthew, Wierstra, Daan, and Lillicrap, Timothy. Meta-learning with memory-augmented neural networks. In Proceedings of The 33rd International Conference on Machine Learning, pp. 1842–1850, 2016.
[3]Shorten C , Khoshgoftaar T M . A survey on Image Data Augmentation for Deep Learning[J]. Journal of Big Data, 2019, 6(1):1-48.
[4]Luke T, Geoff N. Improving deep learning using generic data augmentation. arXiv preprint. 2017.
[5] Hiroshi I. Data augmentation by pairing samples for images classification. ArXiv e-prints. 2018
[6]Cecilia S, Michael JD. Improved mixed-example data augmentation. ArXiv preprint. 2018
[7]Tomohiko K, Michiaki I. Icing on the cake: an easy and quick post-learning method you can try after deep learning. arXiv preprints. 2018.
[8]Ryo T, Takashi M. Data augmentation using random image cropping and patches for deep CNNs. arXiv preprints. 2018.
[9] Zhun Z, Liang Z, Guoliang K, Shaozi L, Yi Y. Random erasing data augmentation. ArXiv e-prints. 2017.
[10] Christopher B, Liang C, Ricardo GPB, Roger G, Alexander H, David AD, Maria VH, Joanna W, Daniel R. GAN augmentation: augmenting training data using generative adversarial networks. arXiv preprint. 2018
[11]Leon AG, Alexander SE, Matthias B. A neural algorithm of artistic style. ArXiv. 2015
[12] A F A , A I D , B E K , et al. GAN-based synthetic medical image augmentation for increased CNN performance in liver lesion classification[J]. Neurocomputing, 2018, 321:321-331.
[13] Meta-Learning: A Survey. Joaquin Vanschoren
[14]Sebastien CW, Adam G, Victor S, Mark DM. Understanding data augmentation for classification: when to warp? CoRR, abs/1609.08764, 2016.