Python数据可视化的例子——直方图(hist)和核密度曲线(kde)
直方图一般用来观察数据的分布形态,横坐标代表数值的均匀分段,纵坐标代表每个段内的观测数量(频数)。一般直方图都会与核密度图搭配使用,目的是更加清晰地掌握数据的分布特征,下面将详细介绍该类型图形的绘制。
1.matplotlib模块
matplotlib模块中的hist函数就是用来绘制直方图的。关于该函数的语法及参数含义如下:
plt.hist(x, bins=10, range=None, normed=False,
weights=None, cumulative=False, bottom=None,
histtype='bar', align='mid', orientation='vertical',
rwidth=None, log=False, color=None,
label=None, stacked=False)
- x:指定要绘制直方图的数据。
- bins:指定直方图条形的个数。
- range:指定直方图数据的上下界,默认包含绘图数据的最大值和最小值。
- normed:是否将直方图的频数转换成频率。
- weights:该参数可为每一个数据点设置权重。
- cumulative:是否需要计算累计频数或频率。
- bottom:可以为直方图的每个条形添加基准线,默认为0。
- histtype:指定直方图的类型,默认为bar,除此之外,还有barstacked、step和stepfilled。
- align:设置条形边界值的对齐方式,默认为mid,另外还有left和right。
- orientation:设置直方图的摆放方向,默认为垂直方向。
- rwidth:设置直方图条形的宽度。
- log:是否需要对绘图数据进行log变换。
- color:设置直方图的填充色。
- edgecolor:设置直方图边框色。
- label:设置直方图的标签,可通过legend展示其图例。
- stacked:当有多个数据时,是否需要将直方图呈堆叠摆放,默认水平摆放。
这里不妨以Titanic数据集为例绘制乘客的年龄直方图,具体代码如下:
import pandas as pd
import matplotlib.pyplot as plt
# 读入数据
Titanic = pd.read_excel(r'泰坦尼克号乘客年龄分布.xlsx')
# 检查年龄是否有缺失
any(Titanic.Age.isnull())
# 不妨删除含有缺失年龄的观察
Titanic.dropna(subset=['Age'], inplace=True)
#设置绘图风格
plt.style.use('ggplot')
#处理中文乱码
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
#坐标轴负号的处理
plt.rcParams['axes.unicode_minus']=False
# 绘制直方图
plt.hist(x = Titanic.Age, # 指定绘图数据
bins = 20, # 指定直方图中条块的个数
color = 'steelblue', # 指定直方图的填充色
edgecolor = 'black' # 指定直方图的边框色
)
# 添加x轴和y轴标签
plt.xlabel('年龄')
plt.ylabel('频数')
# 添加标题
plt.title('泰坦尼克号乘客年龄分布')
# 显示图形
plt.show()
运行结果:
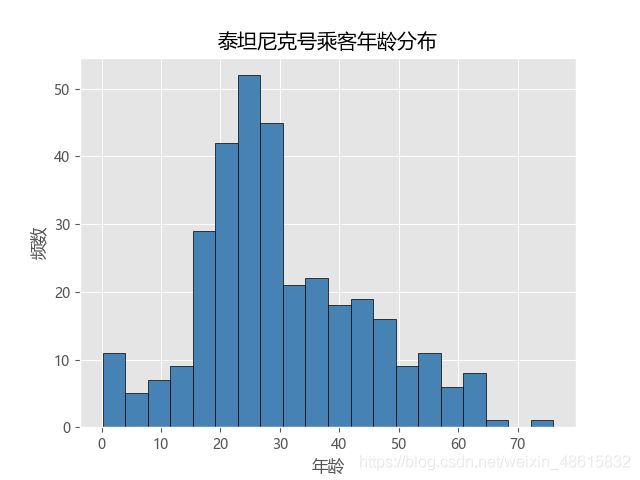
如上图所示,就是关于乘客年龄的直方图分布。需要注意的是,如果原始数据集中存在缺失值,一定要对缺失观测进行删除或替换,否则无法绘制成功。如果在直方图的基础上再添加核密度图,通过matplotlib模块就比较吃力了,因为首先得计算出每一个年龄对应的核密度值。为了简单起见,下面利用pandas模块中的plot方法将直方图和核密度图绘制到一起。
2.pandas模块
import pandas as pd
import matplotlib.pyplot as plt
# 读入数据
Titanic = pd.read_excel(r'泰坦尼克号乘客年龄分布.xlsx')
# 检查年龄是否有缺失
any(Titanic.Age.isnull())
# 不妨删除含有缺失年龄的观察
Titanic.dropna(subset=['Age'], inplace=True)
#设置绘图风格
plt.style.use('ggplot')
#处理中文乱码
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
#坐标轴负号的处理
plt.rcParams['axes.unicode_minus']=False
# 绘制直方图
Titanic.Age.plot(kind = 'hist', bins = 20, color = 'steelblue', edgecolor = 'black', density = True, label = '直方图')
# 绘制核密度图
Titanic.Age.plot(kind = 'kde', color = 'red', label = '核密度图')
# 添加x轴和y轴标签
plt.xlabel('年龄')
plt.ylabel('频数')
# 添加标题
plt.title('泰坦尼克号乘客年龄分布')
# 显示图例
plt.legend()
# 显示图形
plt.show()
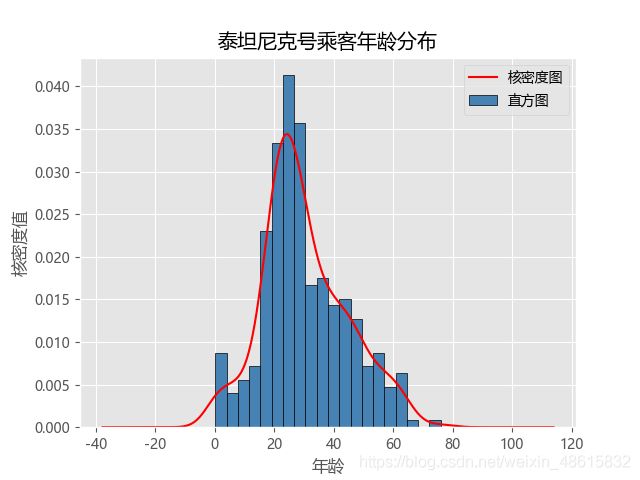
如上图所示,Python的核心代码就两行,分别是利用plot方法绘制直方图和核密度图。需要注意的是,在直方图的基础上添加核密度图,必须将直方图的频数更改为频率,即normed(新版本为density)参数设置为True。
3.seaborn模块
尽管上一幅图满足了两种图形的合成,但其表达的是所有乘客的年龄分布,如果按性别分组,研究不同性别下年龄分布的差异,该如何实现?针对这个问题,使用matplotlib模块或pandas模块都会稍微复杂一些,推荐使用seaborn模块中的distplot函数,因为该函数的代码简洁而易懂。关于该函数的语法和参数含义如下:
sns.distplot(a, bins=None, hist=True, kde=True, rug=False, fit=None,
hist_kws=None, kde_kws=None, rug_kws=None, fit_kws=None,
color=None, vertical=False, norm_hist=False, axlabel=None,
label=None, ax=None)
- a:指定绘图数据,可以是序列、一维数组或列表。
- bins:指定直方图条形的个数。
- hist:bool类型的参数,是否绘制直方图,默认为True。
- kde:bool类型的参数,是否绘制核密度图,默认为True。
- rug:bool类型的参数,是否绘制须图(如果数据比较密集,该参数比较有用),默认为False。
- fit:指定一个随机分布对象(需调用scipy模块中的随机分布函数),用于绘制随机分布的概率密度曲线。
- hist_kws:以字典形式传递直方图的其他修饰属性,如填充色、边框色、宽度等。
- kde_kws:以字典形式传递核密度图的其他修饰属性,如线的颜色、线的类型等。
- rug_kws:以字典形式传递须图的其他修饰属性,如线的颜色、线的宽度等。
- fit_kws:以字典形式传递概率密度曲线的其他修饰属性,如线条颜色、形状、宽度等。
- color:指定图形的颜色,除了随机分布曲线的颜色。
- vertical:bool类型的参数,是否将图形垂直显示,默认为True。(改为False即为horizontal)
- norm_hist:bool类型的参数,是否将频数更改为频率,默认为False。
- axlabel:用于显示轴标签。 label:指定图形的图例,需结合plt.legend()一起使用。
- ax:指定子图的位置。
从函数的参数可知,通过该函数,可以实现三种图形的合成,分别是直方图(hist参数)、核密度曲线(kde参数)以及指定的理论分布密度曲线(fit参数)。接下来,针对如上介绍的distplot函数,绘制不同性别下乘客的年龄分布图,具体代码如下:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 读入数据
Titanic = pd.read_excel(r'泰坦尼克号乘客年龄分布.xlsx')
# 检查年龄是否有缺失
any(Titanic.Age.isnull())
# 不妨删除含有缺失年龄的观察
Titanic.dropna(subset=['Age'], inplace=True)
#设置绘图风格
plt.style.use('ggplot')
#处理中文乱码
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
#坐标轴负号的处理
plt.rcParams['axes.unicode_minus']=False
# 取出男性年龄
Age_Male = Titanic.Age[Titanic.Sex == 'male']
# 取出女性年龄
Age_Female = Titanic.Age[Titanic.Sex == 'female']
# seaborn模块绘制分组的直方图和核密度图
# 绘制男女乘客年龄的直方图
sns.distplot(Age_Male, bins = 20, kde = False, hist_kws = {
'color':'steelblue'}, label = '男性')
# 绘制女性年龄的直方图
sns.distplot(Age_Female, bins = 20, kde = False, hist_kws = {
'color':'purple'}, label = '女性')
plt.title('泰坦尼克号男女乘客的年龄直方图')
plt.xlabel('年龄')
plt.ylabel('频数')
# 显示图例
plt.legend()
# 显示图形
plt.show()
# 绘制男女乘客年龄的核密度图
sns.distplot(Age_Male, hist = False, kde_kws = {
'color':'red', 'linestyle':'-'},
norm_hist = True, label = '男性')
# 绘制女性年龄的核密度图
sns.distplot(Age_Female, hist = False, kde_kws = {
'color':'black', 'linestyle':'--'},
norm_hist = True, label = '女性')
plt.title('泰坦尼克号男女乘客的年龄核密度图')
plt.xlabel('年龄')
plt.ylabel('核密度值')
# 显示图例
plt.legend()
# 显示图形
plt.show()
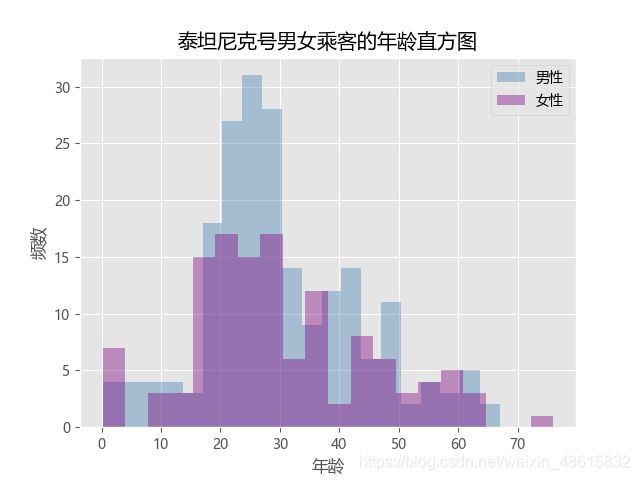
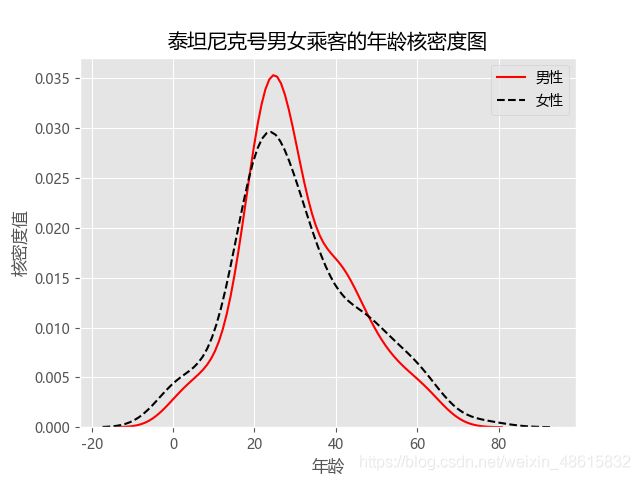
如图所示,为了避免四个图形混在一起不易发现数据背后的特征,将直方图与核密度图分开绘制。从直方图来看,女性年龄的分布明显比男性矮,说明在各年龄段下,男性乘客要比女性乘客多;再看核密度图,男女性别的年龄分布趋势比较接近,说明各年龄段下的男女乘客人数同步增加或减少。
把两种图合在一起画:
【注意】:直方图由频数改为频率
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 读入数据
Titanic = pd.read_excel(r'泰坦尼克号乘客年龄分布.xlsx')
# 检查年龄是否有缺失
any(Titanic.Age.isnull())
# 不妨删除含有缺失年龄的观察
Titanic.dropna(subset=['Age'], inplace=True)
#设置绘图风格
plt.style.use('ggplot')
#处理中文乱码
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
#坐标轴负号的处理
plt.rcParams['axes.unicode_minus']=False
# 取出男性年龄
Age_Male = Titanic.Age[Titanic.Sex == 'male']
# 取出女性年龄
Age_Female = Titanic.Age[Titanic.Sex == 'female']
# seaborn模块绘制分组的直方图和核密度图
# 绘制男女乘客年龄的直方图
sns.distplot(Age_Male, bins = 20, kde = False, hist_kws = {
'color':'steelblue'},
label = ('男性','直方图'),norm_hist=True)
# 绘制女性年龄的直方图
sns.distplot(Age_Female, bins = 20, kde = False, hist_kws = {
'color':'purple'},
label = ('女性','直方图'),norm_hist=True)
# 绘制男女乘客年龄的核密度图
sns.distplot(Age_Male, hist = False, kde_kws = {
'color':'red', 'linestyle':'-'},
norm_hist = True, label = ('男性','核密度图'))
# 绘制女性年龄的核密度图
sns.distplot(Age_Female, hist = False, kde_kws = {
'color':'black', 'linestyle':'--'},
norm_hist = True, label = ('女性','核密度图'))
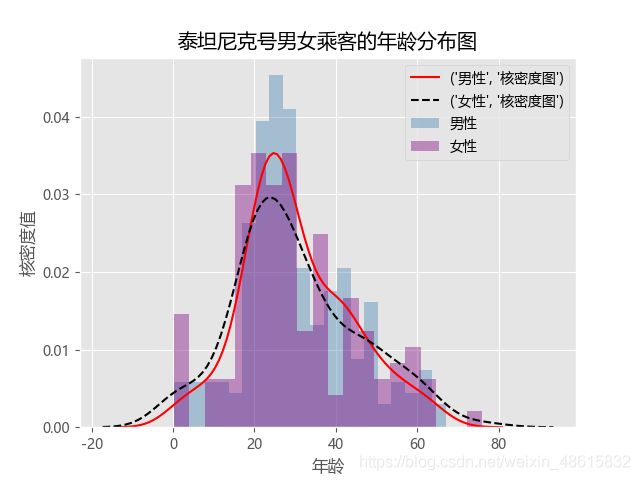
plt.title('泰坦尼克号男女乘客的年龄分布图')
plt.xlabel('年龄')
plt.ylabel('核密度值')
# 显示图例
plt.legend()
# 显示图形
plt.show()