星球年度汇总-爬虫获取股票数据A—概览篇
量化交易是一个多技术综合的项目,学习完书籍《Python股票量化交易从入门到实践》我们提供了升级的学习内容——知识星球《玩转股票量化交易》
在星球中我们深入分享包括Python、爬虫、数据分析、可视化、人工智能、股票策略等各种与股票量化交易相关的内容!
年终岁尾之际,我们开始着手把这一年星球的主题进行串联汇总,帮助大家更系统和整体的掌握分享的干货内容。

为什么学习爬虫呢?
用市面上一些Python第三方库提供了获取股票数据的API接口,使用这些接口可以轻松获取到股票交易数据。
但是,在一些特地的场合下我们只能用网络爬虫这条途径来获取所需的数据。
比如这些库所提供的数据是相对比较普遍的数据,比如开盘价、收盘价、涨幅、成交量等等,而我们所要获取的数据已经超越了它们所能提供的范围。再比如数据的质量、支付的费用等等。
因此在我们掌握使用第三方途径获取股票交易数据后,非常有必要掌握网络爬虫的原理和方法,以备不时之需。
本篇文章作为爬虫系列的概览篇,就让我们先来给大家“激活”下网络爬虫这条数据来源。
初识网络爬虫
在了解网络爬虫的概念之前,我们先设想一个场景:假如没有网络爬虫,我们要阅览东方财富网的行情信息,那么我们需要怎么做?
很显然是使用浏览器访问东方财富网的网站!那么,浏览器访问和网络爬虫爬取,两者有什么区别吗?
在正式介绍网络爬虫的工作模式之前,我们先介绍下平时使用浏览器访问网站的整个过程,这有助于我们更好地理解网络爬虫的工作模式。
当我们在浏览器地址栏中输入https://www.eastmoney.com这个网址后,打开网页会看到东方财富网的页面信息。下一步我们点击导航栏中的用于索引的文字条目,跳转到了新的页面,浏览器地址栏中的网址为也会相应变化,然后我们就可以按这样的方法去查看网页信息。

整个过程简单来说就是浏览器从服务器中获取到网站信息,经过渲染后将效果呈现给我们。总体可以将这个过程概括为以下几步:
第一步:浏览器向DNS服务器发起DNS请求,DNS服务器解析域名后返回域名对应的网站服务器IP地址
第二步:浏览器获取IP地址后向网络服务器发送一个HTTP请求
第三步:网络服务器解析浏览器的请求后从数据库获取资源,将生成的HTML文件封装至HTTP 响应包中,返回至浏览器解析
第四步:浏览器解析HTTP 响应后,下载HTML文件,继而根据文件内包含的外部引用文件、图片或者多媒体文件等逐步下载,最终将获取到的全部文件渲染成完整的网站页面。
因此,我们看到的网页实质上是由渲染后的HTML页面构成的,当我们使用Firefox浏览器打开网页时,鼠标右击浏览器,点击“查看元素”就可以看到当前网页的HTML代码,如下图1.1所示:
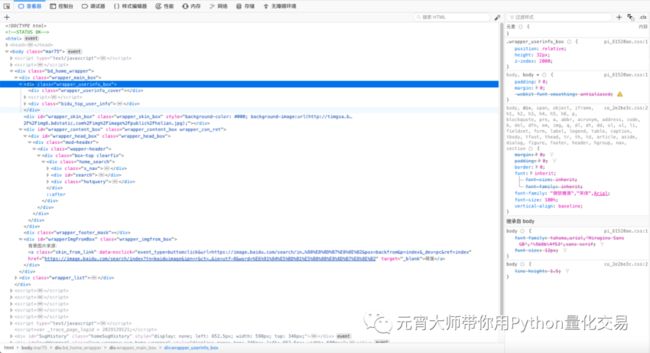
但是,在网络上有着无数的网页,海量的信息,在数据分析中显然不能仅依靠人为点击网页这种方式去查找数据,于是,纵然进化出了网络爬虫。
网络爬虫的工作模式在原理上与浏览器访问网站相似。我们把互联网比作一张大网,爬虫在这张大网上爬行,它在爬取一个网页时,如果遇到所需的资源就可以抓取下来,如果在这个网中它发现了通往另外一个网的一条通道,也就是指向另一个网页的超链接,那么它就可以爬到另一张网上来获取数据。这样,整个连在一起的大网对爬虫来说是触手可及,它将所爬取到的HTML文件内容经过分析和过滤,最终提取所需的图片、文字等资源。
Python实现的流程
Python提供了实现爬虫的核心工具包——网络请求包,比如urllib、urllib2和urllib3,我们能够借此来获取HTML文件。实际上Python中最早内置的网络请求包是urllib,然后在Python2.x中开始自带urllib2,在Python3.x中将urllib和urllib2整合为了urllib3,而urllib2成为了urllib.request。
接下来介绍下推荐使用的urllib3库,只需要通过短短几行代码就能实现HTTP客户端的角色。
使用urllib3库时,首先需要导入urllib3库,例程如下所示:
import urllib3
由于urllib3是通过连接池进行网络请求访问的,所以在访问之前需要创建一个连接池对象PoolManager,使用PoolManager的request()方法发起网络请求。关于request()方法的参数,必须提供method和url,其他参数为选填参数,此处method参数指定为GET请求,url地址为访问的网站地址。
例程如下所示:
http = urllib3.PoolManager()
resp_dat = http.request('GET', " http://image.baidu.com/")
由于request()方法返回的是一个urllib3.response.HTTPResponse对象,最终由data属性返回获取到的HTML文件内容。
例程如下所示:
print(resp_dat.data.decode())
"""
#截取部分内容
"""