Python每日一练(24)-requests 模块获取免费的代理并检测代理 IP 是否有效
目录
- 1. 通过代理服务发送请求
- 2. 获取免费的代理 IP
- 3. 检测代理 IP 是否有效
1. 通过代理服务发送请求
在爬取网页的过程中,经常会出现不久前可以爬取的网页现在无法爬取的情况,这是因为您的 IP 被爬取网站的服务器屏蔽了。此时,代理服务可以为您解决这一麻烦,设置代理时,首先需要找到代理地址,例如,58.220.95.80,对应的端口号为 9401,完整的格式为 58.220.95.80:9401。代码如下:
# -*- coding: UTF-8 -*-
"""
@author:AmoXiang
@file:7.代理的应用.py
@time:2020/11/13
"""
import requests # 导入网络请求模块
from lxml import etree
# 头部信息
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36"
}
proxies = {
'http': 'http://58.220.95.80:9401',
'https': 'https://58.220.95.80:9401' # 设置代理IP与对应的端口号
}
try:
# 对需要爬取的网页发送请求
response = requests.get(url="https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&tn=baidu&wd=ip%E5%9C%B0%E5%9D%80",
headers=headers, proxies=proxies, timeout=3)
print(response.status_code) # 打印响应状态码
response.encoding = "utf8" # 进行编码
html = etree.HTML(response.text) # 解析HTML
info = html.xpath('//*[@id="1"]/div[1]/div[1]/div[2]/table//tr/td//text()')[1:]
info = " ".join(info).replace("\xa0", "").strip().replace("本机IP:", "本机IP: ")
print(info) # 输出当前IP匿名信息
except Exception as e:
print(f"错误异常信息为: {e}") # 打印异常信息
程序运行结果如下图所示:
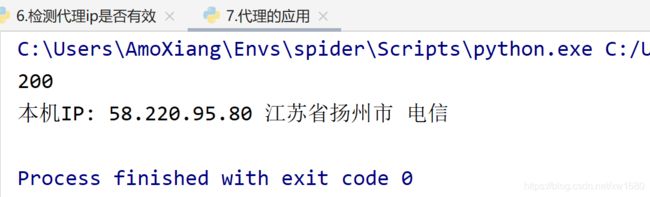
由于示例中代理 IP 是免费的,所以使用得时间不固定,超出使用的时间范围该地址将失效。在地址失效或者地址错误时,控制台将显示以下所示的异常信息。
错误异常信息为: HTTPSConnectionPool(host='www.baidu.com', port=443): Max retries
exceeded with url: /s?ie=utf-8&f=8&rsv_bp=1&tn=baidu&wd=ip%E5%9C%B0%E5%9D%80
(Caused by ProxyError('Cannot connect to proxy.', NewConnectionError
(': Failed to
establish a new connection: [WinError 10060] 由于连接方在一段时间后没有正确答复或
连接的主机没有反应,连接尝试失败。')))
2. 获取免费的代理 IP
为了避免爬取目标网页的后台服务器,对我们实施封锁 IP 的操作。我们可以每发送一次网络请求更换一个 IP,从而降低被发现的风险。其实在获取免费的代理 IP 之前,需要先找到提供免费代理 IP 的网页,然后通过爬虫技术将大量的代理 IP 提取并保存至文件当中。以某免费代理 IP 网页为例,实现代码如下:
# -*- coding: UTF-8 -*-
"""
@author:AmoXiang
@file:5.获取免费的代理ip.py
@time:2020/11/12
"""
import requests # 导入网络请求模块
from lxml import etree # 导入 HTML 解析模块
import pandas as pd # 导入pandas模块
ip_list = [] # 创建保存IP地址的列表
# 头部信息
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"
" (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36"
}
def get_ip(url, headers):
"""
用于获取指定网站中的ip及端口
:param url: 抓取网站的链接
:param headers: 请求头
:return: None
"""
response = requests.get(url=url, headers=headers)
response.encoding = "utf8" # 设置编码方式
if response.status_code == 200: # 判断请求是否成功
html = etree.HTML(response.text) # 解析HTML
# 获取所有带有IP的li标签
li_list = html.xpath('//div[@class="container"]/div[2]/ul/li')[1:]
for li in li_list: # 遍历每行内容
ip = li.xpath('./span[@class="f-address"]/text()')[0] # 获取ip
port = li.xpath('./span[@class="f-port"]/text()')[0] # 获取端口
ip_list.append(ip + ":" + port)
print(f"代理ip为: {ip}, 对应端口为: {port}")
if __name__ == '__main__':
ip_table = pd.DataFrame(columns=["ip"]) # 创建临时表格
for i in range(1, 5):
# 构造免费代理IP的请求地址
url = "https://www.dieniao.com/FreeProxy/{}.html".format(i)
get_ip(url, headers)
ip_table["ip"] = ip_list # 将提取的ip保存至excel文件中的ip列
# 生成xlsx文件
ip_table.to_excel("ip.xlsx", sheet_name="data")
程序代码运行后控制台将显示如下图所示的代理 ip 与对应端口,项目文件中将自动生成 ip.xlsx 文件,文件内容如下图所示:
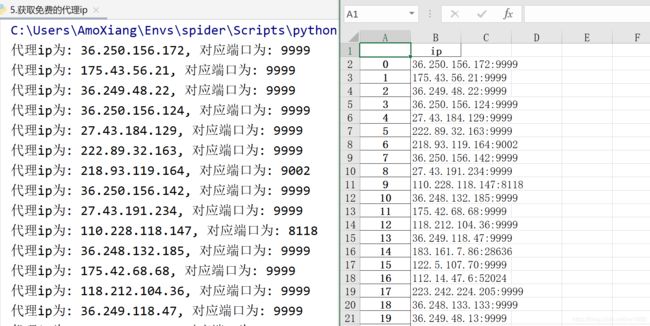
如果以上示例代码运行出错,读者可以参考以上示例代码的学习思路,然后爬取其他免费代理IP的网页。博主这里提供几个免费的代理 IP 网站:
- http://www.goubanjia.com/
- https://www.kuaidaili.com/free/
- http://www.ip3366.net/
- https://ip.jiangxianli.com/?page=1
- https://www.dieniao.com/FreeProxy/1.html
- http://http.zhiliandaili.cn/
3. 检测代理 IP 是否有效
提供免费代理 IP 的网页有很多,但是经过测试会发现并不是所有的免费代理 IP 都是有效的,甚至更不是匿名IP(即获取远程访问用户的 IP 地址是代理服务器的 IP 地址,不是用户本地真实的 IP 地址)。所以要使用我们爬取下来的免费代理 IP,就需要对这个 IP 进行检测。
实现检测免费代理 IP 是否可用时,首先需要读取保存免费代理 IP 的文件,然后对代理 IP 进行遍历并使用免费的代理 IP 发送网络请求,而请求地址可以使用查询 IP 位置的网页。如果网络请求成功说明免费的代理 IP 可以使用,并且还会返回当前免费代理 IP 的匿名地址。代码如下:
# -*- coding: UTF-8 -*-
"""
@author:AmoXiang
@file:6.检测代理ip是否有效.py
@time:2020/11/12
"""
import requests # 导入网络请求模块
import pandas as pd # 导入pandas模块
from lxml import etree # 导入HTML解析模块
ip_table = pd.read_excel("ip.xlsx") # 读取代理IP文件内容
ip_list = ip_table["ip"] # 获取代理IP信息
# 头部信息
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36"
}
# 循环遍历代理IP并通过代理发送网络请求
for ip in ip_list:
# 这里添加了http和https两个代理,这样写是因为有些网页采用 http协议,有的则采用https协议,
# 为了在这两类网页上都能顺利使用代理,所以一般都同时写上。当然,如果确定了某网页的请求类型,可以只写一种
proxies = {
'http': 'http://{ip}'.format(ip=ip),
'https': 'https://{ip}'.format(ip=ip)}
try:
response = requests.get("https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&tn=baidu&wd=ip%E5%9C%B0%E5%9D%80",
headers=headers, timeout=3, proxies=proxies)
if response.status_code == 200: # 判断是否请求成功,请求成功说明代理IP可用
response.encoding = "utf8" # 进行编码
html = etree.HTML(response.text) # 解析HTML
info = html.xpath('//*[@id="1"]/div[1]/div[1]/div[2]/table//tr/td//text()')[1:]
info = " ".join(info).replace("\xa0", "").strip().replace("本机IP:", "本机IP: ")
print(info) # 输出当前IP匿名信息
except Exception as e:
# print(e) # 打印异常信息
pass
程序运行结果如下图所示:

由于博主网络原因,故测试出来的可用的 IP 地址较少。读者可以根据自己查找的(IP查询)请求地址进行更换测试。免费的 IP 地址可用的较少,可以购买付费代理。