mysql查询和修改的底层原理
源于蚂蚁课堂的学习,点击这里查看(老余很给力)
Mysql作为主流数据库,有着强大的数据存储交互功能,成为当下程序猿必备的技能点。很多小伙伴可能对其了解仅限于sql的运用,但对其内部底层如何将数据存储和取出仍然一知半解。本文,帝都的雁分享一下自己了解的mysql的底层原理。
(PS:属于进阶知识,要对mysql的索引底层数据结构、存储引擎有一定概念)
一、通讯方式
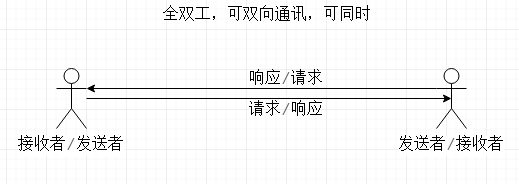
Mysql采用半双工通讯。
通讯方式分为单工、半双工和全双工。
单工:请求方和接收方传输方向是单向的,比如遥控器。

半双工:请求方和接收方传输方向双向,但同一时刻只能有一个传输,一个接收,如对讲机。

全双工:请求方和接收方传输方向双向,同一时刻可以双向传输,比如我们对话。
二、连接方式
Mysql采用长连接。
Http连接分为长连接和短连接。
短连接:一次请求与响应后,马上断开连接。
长连接:建立连接后,可进行多次请求与响应,在最大空闲时间中没有任何交互后,才会断开连接。
TCP协议中每次连接都会遵循三次握手和四次挥手。如果请求频繁,那么我们更多时间消耗在握手和挥手上,输出效率低下,所以长连接更适合于频繁交互的场景。
初学者在于mysql建立连接时,常用JDBC(JavaDataBaseConnection)方式交互。为了避免这种耗时的操作,我们提出了池的概念来进行连接复用。
连接池启动时会初始化一定数量的连接,以链表的方式存放,当有获取连接的请求时,将链表头部的节点取出(从链表剔除),使用后进行归还(再将连接放入链表尾部)。如果这些连接在最大空闲时间内没有任何请求,则连接自动关闭,连接池会将这些连接删除掉,重新创建。
我们可以通过下面sql查询当前mysql服务器配置的基本参数。
# 非交互式超时时间,JDBC连接,默认28800s(8h)
SHOW GLOBAL VARIABLES LIKE 'wait_timeout';
# 交互式超时时间,如sqlYog、navicat等连接工具
SHOW GLOBAL VARIABLES LIKE 'interctive_timeout';
# mysql的最大连接数
SHOW GLOBAL VARIABLES LIKE 'max_connections';
# 数据传输的上限 32M,默认1M
SHOW GLOBAL VARIABLES LIKE 'max_allowed_packet%';
三、mysql缓存设计(了解即可)
在mysql8之前,内置缓存来提升查询速度,减少IO访问。但mysql8开始弃用这种鸡肋的功能,改为推荐使用第三方缓存技术,如redis。
缓存以sql为key,结果集为value,键值对的方式存放在mysql内存中。
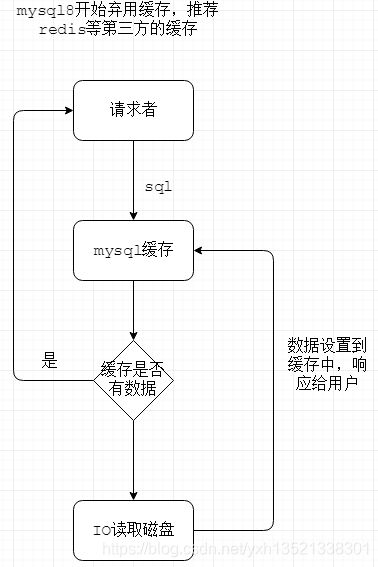
我们可以使用sql_no_cache去绕过mysql的缓存去直接询问数据。
如:SELECT SQL_NO_CACHE NAME FROM user WHERE ID = 1;
四、存储引擎
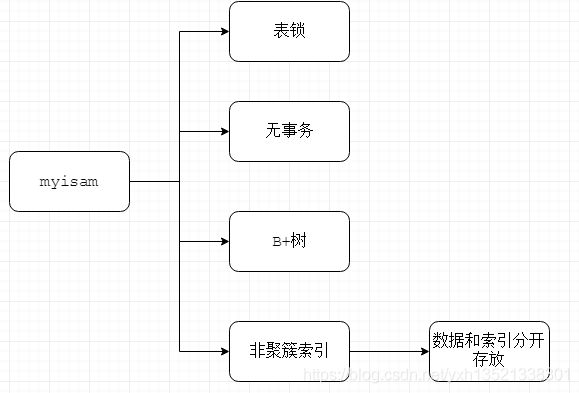
Mysql有很多存储引擎,但常用的为InnoDB和MyiSAM。
Mysql5.5前MyiSAM为默认的存储引擎。MyiSAM没有事务的概念,而且底层采用非聚簇索引,有表锁,使用需要高度注意,否则会产生锁表的问题。
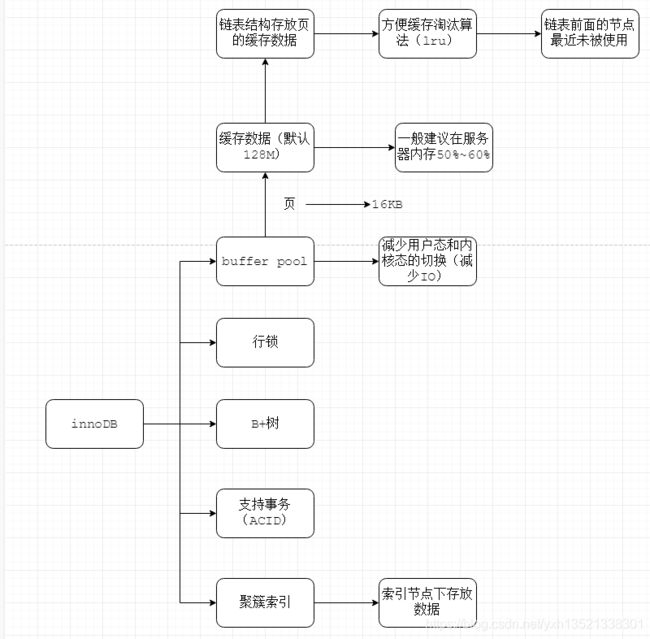
InnoDB为5.5版本开始的改进。支持事务(ACID),采用聚簇索引存放索引和数据,且支持行锁。还提供一个Buffer Pool的缓冲池用于缓存页数据。
Buffer Pool主要用于缓冲数据,减少数据的IO操作,一般大小为服务器内存50%~60%。数据在MySQL底层都是以页的方式出现,用于提升效率。缓存数据以链表的方式存放,采用lru缓存淘汰算法进行数据淘汰处理(头部节点可能最近未被使用)。
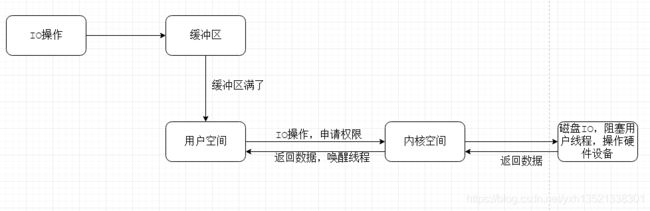
五、用户态和内核态
我们想要获取或保存数据,本质上都是在磁盘上进行IO操作。当应用程序发出此请求后,当前线程处于用户态,不能直接操作计算机硬件,需要进行权限申请,切换至内核态,同时用户线程阻塞等待。内核态IO处理之后,再切换回用户态,唤醒线程进行响应。
所以我们要尽量避免用户态和内核态的切换造成的线程阻塞唤醒这一耗时操作。InnoDB的Buffer Pool很好地实现这一功能。
六、顺序IO和随机IO
顺序IO是指多条记录只需要磁盘寻址一次后,直接在此地址后顺序写入磁盘即可;而随机IO是指多条记录需要各自进行寻址存放数据。
那么为什么日志是顺序IO而数据库数据存放是随机IO呢?
谈谈个人理解。日志不需要维护记录的顺序,即只要这段时间有写入的请求,直接在文件后追加内容即可,所以只要找到日志末尾地址,顺着这个地址向后IO就行。但数据不同,mysql的数据是按照索引的排序来进行存放的,多个记录进行IO时,需要按照索引的排序进行寻址插入。而这多条记录无法保证在索引上的顺序是连续的,需要各自找到自己的地址进行IO。
还有一种说法,多条记录保存时,有可能在磁盘上地址相邻,存放之后,对于索引来说,B+树最下层的链表是排好顺序的,如果按照这个顺序对比每个节点的物理地址,就会发现这些地址由于插入时间不同,根本杂乱无序。
我个人倾向于后者。数据应该插入之后才指向索引对应的位置,否者,索引需要在生成节点的同时就指定物理磁盘地址有些不切实际和占用资源(有待商榷,欢迎大家一起讨论)。
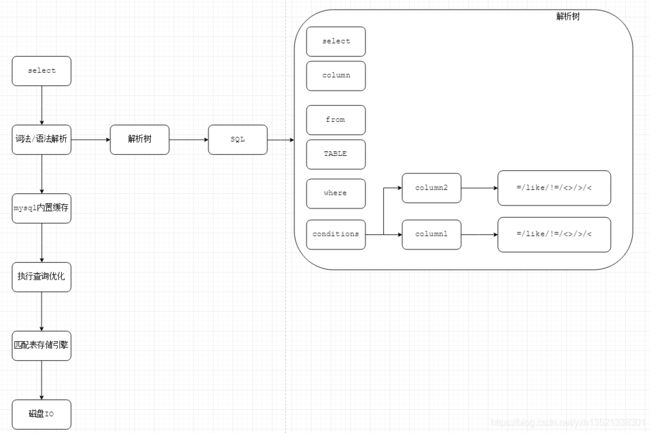
七、查询语句底层原理(InnoDB为例)
当一条sql语句执行时,mysql会先进行词法分析,判断关键字或者sql中字符是否符合sql规范;然后进行语法解析,为sql生成一颗解析树,来检验sql语法是否有误。
Sql检查完毕后,开始以sql为key查询mysql内存缓存中是否有值(mysql8去掉此步骤);缓存无值后,开始选出sql的最佳索引,执行查询优化,根据表的存储引擎交由对应的执行器进行数据的访问。
执行器先去buffer pool中查找对应数据页是否存在缓存中,若不存在则进行随机IO的寻址查找,找到数据的数据页返回给buffer pool进而返回给用户。
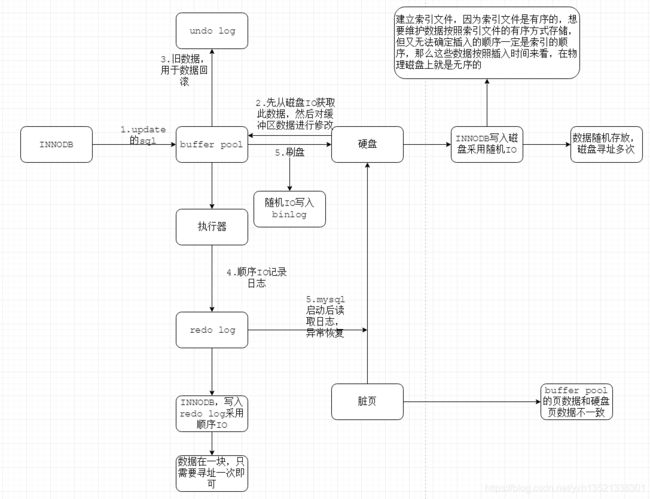
八、更新语句底层原理(InnoDB为例,update/insert/delete)
大致流程同查询。
先经过词法分析、语法解析确保sql的正确性,然后将需要变更的数据先通过磁盘随机IO查询出来,放入到buffer pool 中,buffer pool将这些数据在以顺序IO的方式追加至undo.log中(用于事务回滚)。然后将buffer pool中的数据按照sql进行变更,变更后将变更日志以顺序IO的方式追加至redo.log中(用于异常恢复)。然后通过磁盘多次寻址的随机IO方式变更对应的数据,之后将磁盘数据的变动写入至mysql的bin.log中进行日志快照的备份。
这里有一个数据一致性的问题。比如:如果buffer pool中数据已经变更,但此时MySQL宕机,那么磁盘数据就会和缓冲数据不一致。redo.log用于解决这种灾备或者异常情况的恢复,通过redo.log中的日志快照可以将数据变动同步至恢复正常的mysql服务器对应的物理磁盘上。
如果在buffer pool写入redo.log前,mysql宕机,则无法将数据同步至mysql,需要进行事务回滚,通过undo.log的快照回滚缓冲池的数据。
需要特别注意:undo.log和redo.log是innoDB的设计,bin.log则是mysql自带的日志快照。所以在进行主从复制、集群或mq同步数据,可以采用bin.log进行数据同步。
后续将持续更新一些mysql相关的知识以及sql调优的心得。
欢迎大家和帝都的雁积极互动,头脑交流会比个人埋头苦学更有效!共勉!
公众号:帝都的雁
