【进阶之路】并发编程(三)-非阻塞同步机制
导言
这一篇的内容主要来自于《java并发编程实战》,有一说一,看这种写的很专业的书不是很轻松,也没办法直接提高多少开发的能力,但是却能更加夯实基础,就像玩war3,熟练的基本功并不能让你快速地与对方拉开差距,但是却能再每一次团战中积累优势。
近年来,并发编程的领域更多的偏向于使用非阻塞算法,这种算法底层用原子机器指令(如比较交换CAS之类的)来替代锁用以确保数据在并发访问中的一致性。这样的非阻塞算法广泛的用于在操作系统和JVM中实现线程/程序调用机制、垃圾回收算法等。

java5.0后,使用原子变量类(例如AtomicInteger和AtomicReference)来构建高效的非阻塞算法。
与基本类型的包装类相比原子变量类是可修改的,在原子变量类中没有重新定义hashCode或equals方法,每个实例都是不同的,不宜用做基于散列的容器中的键值。
原子变量类比锁的粒度更细量级更轻,将发生竞争的范围缩小到单个变量上。
从《并发编程实战》这本书出发,对给予的用例进行测试,能够得出的结论:原子变量因其使用CAS的方法,在性能上有很大优势。
- 1、在没有竞争的情况下,原子变量的性能更高。
- 2、在中低程度的竞争下,原子变量基于CAS的操作,性能会远超过锁。
- 3 在高强度的竞争下,锁能够更好地帮助我们避免竞争(类似于,交通略拥堵时,环岛疏通效果好,但是当交通十分拥堵时,信号灯能够实现更高的吞吐量)。
之前的文章已经讲过了volatitle变量、CAS算法、AtomicInteger线程安全的原子变量等,没有看过或者已经忘记的的同学可以点击下方的蓝色链接去看看(复习一下)。
【进阶之路】包罗万象——JAVA中的锁
非阻塞算法
如果一个线程的失败或者挂起不会导致其他线程的失败或挂起,这种算法就叫做非阻塞算法。
1、非阻塞栈
在并发访问的环境下,push和pop方法通过CAS算法可以保证栈的原子性和可见性,从而安全高效的更新非阻塞栈。
//根据《并发编程实战》的代码进行分析
public class CocurrentStack {
/**
* AtomicReference和AtomicInteger非常类似,不同之处就在于AtomicInteger是对整数的封装,
* 而AtomicReference则对应普通的对象引用。也就是它可以保证你在修改对象引用时的线程安全性
*/
AtomicReference> top = new AtomicReference>();
/*
* 这里定义了一个栈(其实是列表,但是我们提供的功能仅仅能作为栈),
* 当有新值加入,会把旧值挂在新值的next方法上,,可以通过递归next拿到所有Node
* */
public void push(E item) {
Node newHead = new Node(item);
Node oldHead;
do {
oldHead = top.get();
newHead.next = oldHead;
//这边用了CAS算法进行判断,这也是非阻塞算的和核心之一
} while (!top.compareAndSet(oldHead, newHead));
}
/**
* 实现出栈功能,同时出栈也实现了CAS的功能
*/
public E pop() {
Node oldHead;
Node newHead;
do {
oldHead = top.get();
if(oldHead == null) {
return null;
}
newHead = oldHead.next;
} while (!top.compareAndSet(oldHead, newHead));
return oldHead.item;
}
private static class Node {
public final E item;
public Node next;
private Node(E item) {
this.item = item;
}
}
}
根据代码我们可以看出它拥有非阻塞算法的特点:一个线程的失败或者挂起不会导致其他线程的失败或挂起。如果某项操作的完成具有不确定性,不成功则会重新执行。
这个非阻塞栈通过CAS来尝试修改栈顶元素,该方法为原子操作,如果发现被其他线程干扰,CAS会更新失败,这个时候意味着另一个线程已经修改了堆栈。这些操作都是原子化地进行的。同时,我们需要不断的循环,以保证在线程冲突的时候能够重试更新。
2、非阻塞链表
根据CAS算法的内容与对非阻塞栈的研究,我们知道要实现非阻塞算法的方法就是实现原子级的变量。
使用非阻塞算法实现一个链接队列比栈更复杂,因为它需要支持首尾的快速访问,需要维护两个独立的队首指针和队尾指针,初始时都指向队列的末尾节点,在成功加入新元素时两个指针都需要原子化的更新。
//依然是根据《并发编程实战》的代码进行分析
public class LinkedQueue {
private static class Node {
final E item;
//还是和之前的一样,以保证你在修改对象引用时的线程安全性
final AtomicReference> next;
public Node(E item, Node next) {
this.item = item;
this.next = new AtomicReference>(next);
}
}
//初始化节点
private final Node dummy = new Node(null, null);
//声明AtomicReference类型的头尾节点、一切都是为了安全
private final AtomicReference> head
= new AtomicReference>(dummy);
private final AtomicReference> tail
= new AtomicReference>(dummy);
/**
*非阻塞算法新增操作
*/
public boolean put(E item) {
//声明一个新的节点
Node newNode = new Node(item, null);
while (true) {
Node curTail = tail.get();
Node tailNext = curTail.next.get();
//得到链表的尾部节点
if (curTail == tail.get()) {
// 如果尾部节点的后续节点不为空,则队列处于不一致的状态
if (tailNext != null) {
// 比较后将为尾部节点向后退进;
tail.compareAndSet(curTail, tailNext);
} else {
// 如果尾部节点的后续节点为空,则队列处于一致的状态,没有其他队列操作,尝试更新
if (curTail.next.compareAndSet(null, newNode)) {
// 更新成功,将为尾部节点向后退进;
tail.compareAndSet(curTail, newNode);
return true;
}
}
}
}
}
}
通过代码,我们能看出,队列里的每一个节点都有一个空置节点。任何线程在执行插入操作的时候,都能够通过tail.next操作检查队列的状态。如果不为空的情况,则能判断出有其他的线程已经插入了一个节点,但是还没有将tail指向最新的节点,这时候代码可以通过推进tail指针向前移动一个节点把状态恢复为稳定(即尾结点的置空状态)。同时,另一个已经执行一半的线程的尾结点恢复稳定后,也不会受到影响。
这种设计的好处在于,如果多个线程同时操作方法,不需要加锁等待,每次插入之前链表自身会检查tail.next是否为空来判定队列是否需要保持稳定状态,如果是,它首先会推进队尾指针(可能多次),直到队列处于稳定状态(tail.next为空)。
我们从源码中也能看到,非阻塞链表ConcurrentLinkedQueue的实现方式。
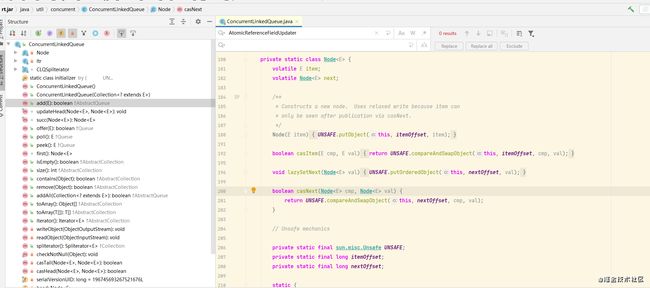
结语
非阻塞算法通过使用底层的并发原语,比如CAS算法,取代了锁.原子变量类向用户提供了这些低层级原语,也能够当做"更佳的volatile变量"使用,同时提供了整数类和对象引用的原子化更新操作.
非阻塞算法在设计和实现中很困难,但是在典型条件下能够提供更好的可伸缩性,并能更好地预防活跃度失败。从JVM并发性能的提升很大程度上来源于非阻塞算法的使用,包括在JVM内部以及平台类库。
有需要的同学可以加我的公众号,以后的最新的文章第一时间都在里面,也可以找我要思维导图
