如何再次提问?基于连续空间改写的生成式问句数据增广
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
问句数据增广旨在自动生成上下文相关的问句增广数据,在机器阅读理解、问答、问句生成和问答式自然语言推理等任务上进一步提升模型性能。基于可控式文本改写的思想,讲者提出了一种新的问句数据增广方法称为CRQDA。该方法将问句数据增广任务看作是一个带限制的文本改写任务以生成上下文相关的可回答和不可回答问句。

刘大一恒:四川大学3+2+3本硕博连读生,师从吕建成教授。主要研究方向为自然语言生成、预训练语言模型和机器阅读理解。目前在ACL、EMNLP、AAAI、TASLP、IJCNN、TALLIP等期刊会议上以第一作者和共一作者发表论文13篇。担任ACL、AAAI、IJCAI、EMNLP、NAACL、EACL、TNNLS等期刊会议审稿人。

一、背景知识
1、数据增广是什么?
数据增广是一种常用的提升模型泛化能力的方法。相比旋转、剪裁等图像数据常用的数据增广方法,合成新的高质量且多样化的离散文本相对来说更加困难。

2、文本数据增广方法分类
第一类是通过直接对文本数据进行局部修改,如采用一些随机替换、删除、插入等操作修改原始数据以得到新的数据样本。
第二类则是利用生成的方式,通过回译、复述、使用预训练语言模型和各类生成模型如VAE,GAN等生成新的训练数据。

3、什么是问句数据增广?
文本数据增广技术被应用到文本分类和机器翻译等任务,而问句数据增广则是文本数据增广中的一类技术,它主要为机器阅读理解、问句生成、问答式自然语言推理等任务对问句数据进行增广,生成额外的成对数据。

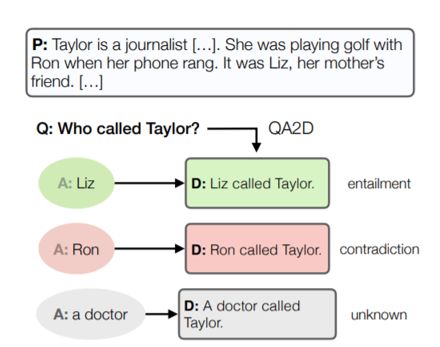
例1:如左图所示机器阅读理解要求模型在给定的段落中找到问句的答案片段。
例2:如右图所示, 给定问句和相关段落中的句子,QNLI要求模型推断该句子是否包含问题的答案。
由于上述任务需要模型对问题-段落对进行推理,因此,使用现有文本数据增广的方法直接增广问句或段落数据的可,能会导致不相关的问句-段落对,从而无法提高下游模型的性能
4、现有技术
a、可回答的问句数据
问句数据增广技术主要通过利用一种称为往返一致性的技术合成可回答的问句数据。
这类方法的思路如下:
1)给定段落C,我们通过答案抽取模型生成潜在的答案片段A;
2)利用答案感知的问句生成模型以段落C和答案A为输入生成相应的问句Q;
3)利用预先训练好的机器阅读理解模型,通过输入段落C和问句Q预测答案片段A‘;
4)如果预测的答案A’与之前生成的答案A一致,则认为该数据对质量较高,可以被保留;
通过以上方法则可以生成大量的可回答问句数据
缺点:该类技术不是专为生成相近的不可回答问句而设计的。

b、不可回答的问句数据
目前研究了不可回答问句的数据增广问题的方法是:
通过特有的数据集,如SQuAD2.0,中对迷惑性答案的标注信息作为锚点,以构建不可回答问句和可回答问句的伪成对数据集,然后通过一个pari2seq的模型,通过有监督学习的方式,将已有的可回答问句改写为相似的不可回答问句。

缺点:
①大部分的数据集都没有提供这样的迷惑答案的标注信息;
②无法轻易的构建出这样的成对数据。
解决思路:
①能否使用无监督的方法实现可回答问句到不可回答问句的改写任务呢?
②如果将问句的可回答性看作一类特别的属性,能否借助现有的无监督属性可控的文本改写技术完成问句数据增广呢?
二、基于可控式改写的问句数据增广方法——CRQDA
受连续空间修改的可控式改写方法的启发,提出了基于可控式改写的问句增广方法(Controllable Rewriting based Question Data Augmentation, CRQDA)。
与在离散空间修改问句的方法不同,该方法在连续的词向量空间,以机器阅读理解模型作为指导对问句进行改写。
相比有监督的方法,该方法不需要成对的问句语料,就可以将可回答问句改写为相似的不可回答问句。
1、核心思想
在连续空间中,以机器阅读理解模型为指导,对问句进行修改并生成新的问句数据。
由两个模块构成
1)预先训练好的机器阅读理解模型,如左图所示,它用于通过梯度信息告诉我们该怎样在连续空间中对问句的表达进行修改;
2)基于Transformer结构的自编码器,由右图所示。它用于将离散的问句映射到连续空间中并重构回离散问句。
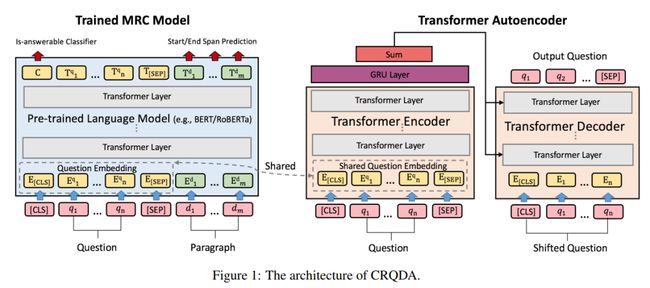
2.1 CRQDA模型结构
a、机器阅读理解模型
采用了基于预训练语言模型(如BERT, RoBERTa),该模型将离散的问句和段落作为输入,通过词向量得到二者的词向量序列,再通过多层的Transformer得到最终的隐层表达序列,在该序列上通过分类器去预测答案的起始和结束位置,同时通过起始位置的特殊字符对问句是否可回答进行分类。
b、Transformer自编码器
①将原始的离散问句数据输入到编码器,通过词向量得到问句在连续空间中的问句向量序列;
②再通过多层Transformer、GRU和求和池化得到问句向量表达;
③接着将问句表达输入到解码器中,重构回离散问句将机器阅读理解模型训练好;
④将它的词向量权值固定并共享到Transformer自编码器的编码器之中。
自编码器训练结束之后,这两个模型的问句词向量则位于同一个连续空间之中,因此可以在这个空间之中以机器阅读理解模型为指导改写问句了。
2、推理阶段
在推理阶段,假设给定一个可回答问句,想将其改写为不可回答问句,那么写需要满足三个限制。
1)改写后的问句与相应的段落输入到机器阅读模型之后,应该让机器阅读理解模型对问句类型的预测结果由原来的可回答转变为不可回答。
2)在连续空间中基于梯度进行改写的步长应该是自适应的,防止改写过大或改写无效。
3)最终改写后生成的问句应该与原始问句相似,这样有助于提升下游模型的性能。

2.2CRQDA问句改写过程
目标1
解决步骤:
①先将原始的离散问句同时输入到机器阅读理解模型和自编码器中,得到问句向量序列,注意这两个序列实际位于同一个连续空间之中。
②将相应的段落也输入到机器阅读理解模型中,并将不可回答问句的标签作为模型问句类型分类的目标,将原始答案也作为答案预测的标签;
③计算机器阅读理解模型的损失值和对应的问句词向量的梯度;
由于原始问句是可回答的,这里刚开始被机器阅读理解模型分类为不可回答的损失值较高。④优化该损失函数为目标,固定住模型的所有参数,利用梯度信息迭代式地改写问句的词向量序列,直到机器阅读理解模型预测改写后的问句为不可回答问句的置信度满足某一阈值,得到了最终改写后的问句词向量,由自编码器就可以重构出新的不可回答问句。

2.3 CRQDA问句修改算法
目标2
解决步骤:
使用了一种动态分配初始化步长的方法,通过分配一系列的改写初始化步长,进行多轮的改写,每次改写迭代使用权重衰减的方法控制步长。
目标3
解决步骤:
设计了一种简单的数据保留机制,即通过比较改写后的问句与原始问句的一元字符重叠率,保留该重叠率在某个阈值范围内的问句作为增广的训练数据
通过这样的方法,我们就可以在不使用可回答与不可回答成对语料的情况下,将可回答问句改写为不可回答问句,同时我们也能用同样的方式生成多个可回答问句
三、实验
在SQuAD2.0数据集上,将CRQDA方法与其他文本数据增广方法进行比较。将不同方法生成的增广数据去训练同样的一个BERT-large模型,然后根据该模型的性能作为评价标准。
1、其他文本数据增广方法
主要比较了四种经典的文本数据增广方法:
1)Easy data augmentation,该方法通过随机替换、删除、插入等操作对问句进行修改生成新的问句数据;
2)back-translation回译,该方法将原始的英文问句先翻译为法语,再将法语翻译回英文,得到新的问句数据;
3)变分自编码器,该方法将原始问句映射到隐空间中,通过采样生成新的问句数据;
4)基于Transformer的自编码器,该方法与CRQDA唯一的区别在于,它通过对词向量序列增加随机高斯分布的噪声来改写问句,而CRQDA通过机器阅读理解模型的梯度信息改写问句。
之外,比较了两种最新的问句数据增广方法;
1)到往返一致技术,通过该方法生成了300万个额外的可回答问句数据;
2)使用可回答与不可回答问句的成对语料训练的pair2seq方法;
Finetune BERT-large on SQuAD2.0+Augmented dataset

2、实验结果
第一行是使用原始数据训练BERT-large模型的性能,四种常用的文本数据增广方法,包括EDA, Back-Translation, Text-VAE, and AE with Noised,都无法进一步提升模型的性能。
分析认为由于这类方法单独对问句进行改写,没有考虑段落和相应的答案信息,可能会破坏问句推理出答案的关键信息,导致引入了额外的噪音,反而损害了模型的性能。
而三种问句数据增广方法,包括 roundtrip consistency, pair2seq, and CRQDA都可以进一步提升模型的性能,并且CRQDA超过了所有基准方法。
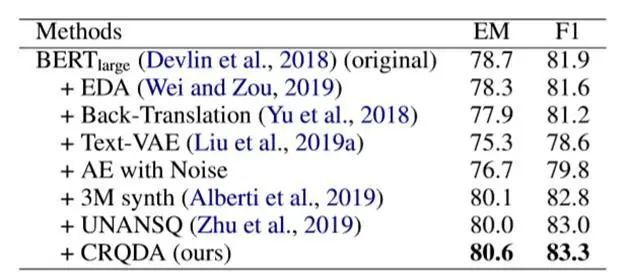
表1 SQuAD2.0数据增广方法对比
3、实验分析
对CRQDA方法进行了进一步的实验分析,用CRQDA方法生成的数据集在其他的机器阅读理解模型上是否也有效果。
a、其他机器阅读理解模型
将生成的同样的增广数据去分别训练BERT-base、BERT-large、RoBERTa-base和RoBERTa-large,可以看到CRQDA方法都可以不同程度上提升模型的性能,在BERT-base上,F1 score甚至可以提升2.4个点。

表2 CRQDA对不同机器阅读理解模型的性能提升
b、不同的数据集
用不同数据集去训练自编码器对性能的影响,使用SQuAD2.0训练集中的所有问句数据训练自编码器,或进一步去收集更多的问句数据,在不同的QA和MRC数据集上收集了200万的高质量问句数据来训练自编码器。进一步探索了通过使用16G的wikidata来进一步预训练自编码器,以及进一步引入一些MASK的机制来预训练自编码器。

表3 不同训练数据对CRQDA的性能影响
可以看到在使用了更多的数据之后,CRQDA生成的数据对下游模型的性能有明显提升,并且自编码器的重构能力也有了很大的提升,在预训练之后几乎可以百分之百的重构原始问句,而引入了mask机制预训练模型之后,尽管可以进一步提升自编码器的重构能力,却降低了它对问句的改写能力。
这样的结果是因为引入了mask这样的噪音预训练自编码器后,可能会加强自编码的抗噪音能力,使得引入的机器阅读理解模型的梯度信息也被一定程度上忽略掉,因此降低了改写问句的性能。
总体而言,使用了预训练之后可以进一步提升方法的效果。
c、不同设定下生成的问句增广数据集
对比了CRQDA在不同设定下生成的问句增广数据集对模型性能的影响,比如只增广可回答问句,只增广不可回答问句,同时增广可回答与不可回答问句,以及通过调整阈值来保留更多或更少的增广数据等等。

表4 CRQDA不同增广数据对性能影响
实验发现所有的设定下都可以进一步提升下游模型的性能,然而,使用更多的数据却不能总是保证模型性能有进一步的提升。使用不可回答问句的增广数据对模型的性能提升最大。
d、SQUAD1.1问句数据增广任务
最后进一步将CRQDA方法用于SQUAD1.1问句数据增广任务。
①将CRQDA生成的增广问句去训练文本生成预训练语言模型,先知网络Prophetnet,通过实验发现CRQDA方法也可以进一步提升它的性能,达到了该任务上的一个SOTA效果。
②将CRQDA应用到QNLI问答式自然语言推理任务上,发现CRQDA方法可以进一步提升BERT-large的性能。
这两个实验进一步说明了CRQDA方法的一个可扩展性。

表5 CRQDA对SQuAD1.1问句生成任务的性能提升

表6 CRQDA对QNLI问答自然语言推理任务的性能提升
总结
提出了一种新的问句数据增广方法称为CRQDA,该方法能够生成包括可回答问句和不可回答问句数据对的增广数据,实验在SQuAD2.0上验证了该方法的有效性。
通过实验验证了该方法可以进一步提升问句生成、问答式自然语言推理等任务的性能。未来也考虑将该方法用到其他的任务上,比如结合视觉信息的问答任务。
论文链接:
https://www.aclweb.org/anthology/2020.emnlp-main.467.pdf
e m t
往期精彩
AI i

整理:唐家欣
排版:岳白雪
审稿:刘大一恒
AI TIME是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注
AI TIME欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你!
请将简历等信息发至[email protected]!
微信联系:AITIME_HY

(直播回放:https://b23.tv/MA9wF4)
(点击“阅读原文”下载本次报告ppt)