读Windows核心编程-2-字符和字符串
(2)字符和字符串处理
字符编码
ANSI为单字节编码,所以最多表示256个符号,这远远不够,因此双字节字符集(double-byte character set, DBCS)应运而生,其原理是当第一个字节在某一范围内时,需要继续检测第二个字节才能确定这两个字节代表什么符号,以日本字为例,首字节在0x81~0x9F或0xE0~0xFC,那么就需要检测下一个字节。这样的话,有的符号一个字节表示,有的是两个字节表示。单单使用strlen也无法确定字符串到底有多少字符,它只告诉你到结尾的0之前有多少个字节。
Unicode标准包含以下几种编码转换格式(Unicode Transformation Format):
UTF-8:
值在0x0080以下的,压缩为1个字节,适合于美国使用的字符;
0x0080~0x07FF转换为2个字节,适合于欧洲和中东地区的语言;
0x0800以上转换为3个字节,适合于亚洲语言;
代理对(surrogate pair)被写为4个字节。
由于UTF-8对ANSI字符的兼容性,并且在ANSI字符较多的情况下更节省空间,因此比较流行,然后在字符串中存在大量0x0800以上的字符时,UTF-16比较高效;
UTF-16:
所有字符以2个字节表示,对于2字节还不够的语言使用代理(surrogate)来表示,后者使用4个字节来表达一个字符,但由于只有少数语言才会用到,因而2字节编码方式多数情况下比较高效。Windows内核/COM/.NET都是采用UTF-16编码。
UTF-32:
每个字符都采用4字节表示,这种方式比较简单,如果只在内存中使用的话,UTF-32是个高效的方式,然后如果保存文件或者网络传输的话,就比较浪费空间了。
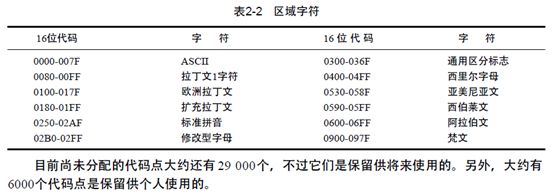
ANSI字符和Unicode字符
ANSI字符和字符串:
Char c='A';
Char sz[100]="A String";
Unicode字符和字符串:
Wchar_t c=L'A';
Wcahr_t sz[100]=L"A String"
ANSI和Unicode都能编译:
#ifdef UNICODE
#define __TEXT(quote) L##quote
Typedef WCHAR TCHAR;
Typedef const WCHAR *PCTSTR;
#else
#define __TEXT(quote) quote
Typedef CHAR TCHAR;
Typedef const CHAR *PCTSTR;
#endif
#define TEXT(quote) __TEXT(quote)
#define _T(quote) __TEXT(quote)
TCHAR c=_T('A');
TCHAR sz[100]=_T("A String");
Windows的ANSI和Unicode函数
Windows API使用UNICODE宏来区分ANSI和Unicode的使用。
自Windows NT起,Windows所用版本都用Unicode来构建,所以所有的核心函数都需要Unicode字符串,然而为了兼容性,SDK为大多数API提供ANSI版本,但ANSI版本只是个转换壳,就是说ANSI版本的API在内部分配缓冲区,并将ANSI字符串转成Unicode,然后调用相应的Unicode版本,并将结果Unicode转回ANSI然后释放缓冲区并返回。
另外,COM接口只接受Unicode字符串。
资源(字符串表,对话框模板,菜单等)编译完后都是以Unicode字符串保存,如果程序没有定义UNICODE宏,操作系统将执行内部转换。例如,在实际编译模块的时候,LoadString会变成调用LoadStringA,LoadStringA读取资源中的Unicode字符串,并把它转换成ANSI返回给应用程序。
C运行时的ANSI和Unicode函数
C运行时使用_UNICODE来区分ANSI和Unicode,比Windows API使用的宏多个下划线。
C运行时的ANSI和Unicode函数都是"自力更生",不象Windows API那样,C运行时的ANSI和Unicode版本不会互相调用。
Strlen() // ANSI,string.h
Wcslen() // Unicode, string.h
#ifdef _UNICODE
#define _tcslen wcslen // tchar.h
#else
#define _tcslen strlen // tchar.h
#endif
一些修改字符串的C运行时函数存在缓冲溢出的隐患,因此,Microsoft引入了相应的安全字符串函数,例如,应使用_tcscpy_s来替代_tcscpy。更多字符串安全函数见strsafe.h。
利用_countof宏(定义与stdlib.h)可以计算字符串长度,使用_set_invalid_parameter_handler来注册自定义的失败处理函数,使用_CrtSetReportMode(_CRT_ASSERT, 0)可以禁用Debug Assertion Failed对话框。
使用*_s系列字符串安全函数在缓冲区不足时,它们只简单的将目标缓冲区置为'\0',而使用StringCch*和StringCb*系列函数可以在缓冲区截断获得更多的控制。
CompareString按照字符在LCID所标识的语言中的含义来比较字符串,因此速度慢,适用于需要展示给用户的字符串比较;CompareStringOrdinal按照字符码位比较,速度快,但不考虑区域设置,适用于程序内部的字符串比较。此外这两个函数返回值与C运行时库函数的结果值(-1,0,1)不同:
0:表示失败;
CSTR_LESS_THAN = 1;
CSTR_EQUAL = 2;
CSTR_GREATER_THAN = 3;
可以将返回值减2来保持一致。
使用Unicode的好处
-
Unicode有利于程序本地化;
-
只发布一个二进制文件即可支持所有语言;
-
由于Windows核心API都使用Unicode,因此应用程序使用Unicode可减少转换,提升效率;
-
避免了误用已经弃用的(deprecated)函数,很多已弃用的函数没有提供Unicode版本;
-
轻松与COM, .NET集成;
-
操纵程序自身的资源的效率也得到提升(资源始终是以Unicode保存)。
推荐的字符和字符串处理方式
-
使用使用TCHAR/PTSTR来表示字符和字符串;
-
明确区分字符串(char/wchar_t/TCHAR)和字节串(BYTE);
-
使用TEXT/_T宏来表示字面量字符和字符串;
-
使用_countof来计算字符串长度,而不是sizeof;
-
分配缓冲区时始终要乘以sizeof(TCHAR);
-
UNICODE和_UNICODE要么同时定义,要么都不定义;
-
不使用不安全的字符串函数;
-
不使用Kernel32的字符串方法,如lstrcat和lstrcpy;
ANSI和Unicode字符串转换
ANSI转换到Unicode
int WINAPI MultiByteToWideChar(
_In_ UINT CodePage,
_In_ DWORD dwFlags,
_In_NLS_string_(cbMultiByte) LPCCH lpMultiByteStr,
_In_ int cbMultiByte,
_Out_writes_to_opt_(cchWideChar, return) LPWSTR lpWideCharStr,
_In_ int cchWideChar
);
Unicode转换到ANSI
Int WINAPI WideCharToMultiByte(
_In_ UINT CodePage,
_In_ DWORD dwFlags,
_In_NLS_string_(cchWideChar) LPCWCH lpWideCharStr,
_In_ int cchWideChar,
_Out_writes_bytes_to_opt_(cbMultiByte, return) LPSTR lpMultiByteStr,
_In_ int cbMultiByte,
_In_opt_ LPCCH lpDefaultChar,
_Out_opt_ LPBOOL lpUsedDefaultChar
);
判断文本是否为Unicode
BOOL WINAPI IsTextUnicode(
_In_reads_bytes_(iSize) CONST VOID* lpv,
_In_ int iSize,
_Inout_opt_ LPINT lpiResult
);
代码示例:
BOOL StringReverseW(PWSTR pW, int cch){
PWSTR pEnd=pW+wcsnlen_s(pW, cch)-1;
wchar_t c;
while(pW<pEnd){
c=*pW;
*pW=*pEnd;
*pEnd=c;
++pW;
--pEnd;
}
return TRUE;
}
BOOL StringReverseA(PSTR p, int cch){
PWSTR pW;
int nLenOfWide;
BOOL fOK=FALSE;
nLenOfWide=MultiByteToWideChar(CP_ACP, 0, p, -1, NULL, 0);
pW=(PWSTR)HeapAlloc(GetProcessHeap(), 0, nLenOfWide*sizeof(wchar_t));
if(NULL==pW)
return fOK;
MultiByteToWideChar(CP_ACP, 0, p, cch, pW, nLenOfWide);
fOK = StringReverseW(pW, nLenOfWide);
if(fOK){
WideCharToMultiByte(CP_ACP, 0, pW, nLenOfWide, p, cch, NULL, NULL);
}
HeapFree(GetProcessHeap(), 0, pW);
return fOK;
}
void test_unicode(){
std::wcout.imbue(std::locale("chs"));
wchar_t ws[]=L"I我z";
int len=_countof(ws)-1;
int size=sizeof(ws);
wcout<<(PCTSTR)ws<<endl;
char cs[]="i他Z";
int clen=_countof(cs)-1;
int csize=sizeof(cs);
cout<<cs<<endl;
BOOL bIsUnicode=IsTextUnicode(ws, size, NULL);
BOOL bCIsUnicode=IsTextUnicode(cs, csize, NULL);
if(StringReverseW(ws,size)){
wcout<<(PCTSTR)ws<<endl;
}
if(StringReverseA(cs, csize)){
cout<<cs<<endl;
}
}
参考:
http://blog.csdn.net/ax614/article/details/6694625
http://www.cnblogs.com/fangyukuan/archive/2010/08/19/1804055.html