零拷贝以及Java实现
一,DMA
1.DMA概念
顾名思义:DMA,即绕开CPU进行数据读写。在计算机中,相比CPU来说,外部设备访问速度是非常缓慢的,因此memory到memory或者memory到device或者device到memory之间搬运数据是非常浪费CPU时间的!造成CPU无法处理实时事件。因此工程师设计出来一种专门协助CPU搬运数据的硬件DMA控制器,协助CPU完成数据搬运。
2.DMA如何与CPU共享完成数据总线使用
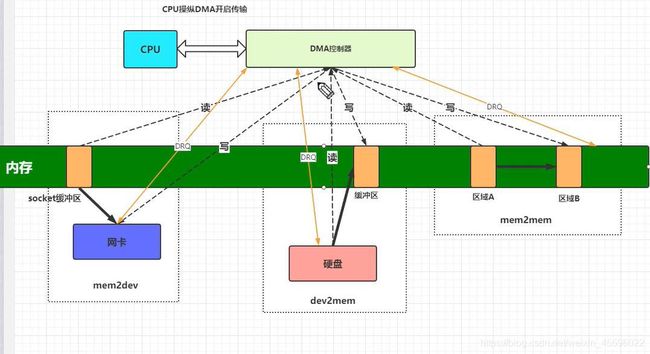
cpu写入数据到网卡
1.首先cpu将数据写入到socket缓冲区
2.cpu通知DMA控制器工作
3.dma控制器将缓冲区的数据写入到网卡
4.dma写入完成后通知cpu
cpu从网卡读取数据
1.cpu通知DMA控制器读取数据
2.DMA从网卡读取数据到socket缓冲区
3.DMA通知CPU读取完成
4.CPU从缓冲区读取数据
二,用户态和内核态
1.为什么需要两种状态的切换
在CPU的所有指令中,有一些指令是非常危险的,如果错用,将导致整个系统崩溃。比如:清内存、设置时钟等。如果所有的程序都能使用这些指令,那么你的系统一天死机n回就不足为奇了。所以,CPU将指令分为特权指令和非特权指令,对于那些危险的指令,只允许操作系统及其相关模块使用,普通的应用程序只能使用那些不会造成灾难的指令。
2.什么是内核空间和用户空间
linux进程有4GB的地址空间
| 应用程序 | shell | vi | … | cc | 用户空间 |
|---|---|---|---|---|---|
| 服务器 | 库函数 | 进程管理 | 存储管理 | 文件管理 | 0-3G |
| 设备驱动 | 消息队列 | 时钟驱动 | 键盘驱动 | 磁盘驱动 | 内核空间 |
| 内核 | 进程调度 | - | 信号量 | - | 3-4G |
3-4G大部分是共享的,是内核态的地址空间。这里存放着整个内核的代码和所有的内核模块以及内核所维护的数据。
3.认识进程描述符和进程内核栈
3.1.进程描述符
为了管理进程,内核必须知道每个进程的信息与其所作的事情进程优先级、分配的地址空间、访问权限etc.)。
进程描述符都是task_struct类型结构, 它的字段包含了与一个进程相关的所有信息(内核还定义了task_t数据类型来等同struct task_struct)。
进程描述符都是task_struct类型的结构,它的字段包含了与一个进程相关的所有信息。因为进程描述符中存放了那么多信息,所以它是非常复杂的,它不仅仅包括了很多进程属性的字段,还有一些字段包括了指向其他数据结构的指针。
task_struct
标示符 : 描述本进程的唯一标识符,用来区别其他进程;
状态 :任务状态,退出代码,退出信号等;
优先级 :相对于其他进程的优先级;
程序计数器:程序中即将被执行的下一条指令的地址;
内存指针:包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针;
上下文数据:进程执行时处理器的寄存器中的数据。;
I/O状态信息:包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表;
记账信息:可能包含处理器时间总和,使用的时钟数总和,时间限制,记账列表等。
保存进程信息的数据结构叫做 task_struct,可以在 include/linux/sched.h 中找到它。
所有运行在系统中的进程都以 task_struct 链表的形式存在内核中。
进程的信息可以通过 /proc 系统文件夹查看。要获取PID为400的进程信息,你需要查看 /proc/400 这个文件夹。大多数进程信息同样可以使用top和ps这些用户级工具来获取。
3.2进程内核栈,用户栈
内核在创建进程的时候,在创建task_struct的同事,会为进程创建相应的堆栈。每个进程会有两个栈,一个用户栈,存在于用户空间,一个内核栈,存在于内核空间。当进程在用户空间运行时,cpu堆栈指针寄存器里面的内容是用户堆栈地址,使用用户栈;当进程在内核空间时,cpu堆栈指针寄存器里面的内容是内核栈空间地址,使用内核栈。
当进程因为中断或者系统调用而陷入内核态之行时,进程所使用的堆栈也要从用户栈转到内核栈。
进程陷入内核态后,先把用户态堆栈的地址保存在内核栈之中,然后设置堆栈指针寄存器的内容为内核栈的地址,这样就完成了用户栈向内核栈的转换;当进程从内核态恢复到用户态之行时,在内核态之行的最后将保存在内核栈里面的用户栈的地址恢复到堆栈指针寄存器即可。这样就实现了内核栈和用户栈的互转。
那么,我们知道从内核转到用户态时用户栈的地址是在陷入内核的时候保存在内核栈里面的,但是在陷入内核的时候,我们是如何知道内核栈的地址的呢?
关键在进程从用户态转到内核态的时候,进程的内核栈总是空的。这是因为,当进程在用户态运行时,使用的是用户栈,当进程陷入到内核态时,内核栈保存进程在内核态运行的相关信心,但是一旦进程返回到用户态后,内核栈中保存的信息无效,会全部清除,因此每次进程从用户态陷入内核的时候得到的内核栈都是空的。所以在进程陷入内核的时候,直接把内核栈的栈顶地址给堆栈指针寄存器就可以了。
4.切换时到底发生了什么
4.1用户态切换到内核态有三种方式
系统调用
这是用户态进程主动要求切换到内核态的一种方式。用户态进程通过系统调用申请使用操作系统提供的服务程序完成工作。例如fork()就是执行了一个创建新进程的系统调用。系统调用的机制核心是使用了操作系统为用户特别开放的一个中断来实现,如Linux的int 80h中断。
异常
当cpu在执行运行在用户态下的程序时,发生了一些没有预知的异常,这时会触发由当前运行进程切换到处理此异常的内核相关进程中,也就是切换到了内核态,如缺页异常。
外围设备的中断
当外围设备完成用户请求的操作后,会向CPU发出相应的中断信号,这时CPU会暂停执行下一条即将要执行的指令而转到与中断信号对应的处理程序去执行,如果前面执行的指令是用户态下的程序,那么转换的过程自然就会是 由用户态到内核态的切换。如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后边的操作等。
这三种方式是系统在运行时由用户态切换到内核态的最主要方式,其中系统调用可以认为是用户进程主动发起的,异常和外围设备中断则是被动的。从触发方式上看,切换方式都不一样,但从最终实际完成由用户态到内核态的切换操作来看,步骤是一样的,都相当于执行了一个中断响应的过程。系统调用实际上最终是中断机制实现的,而异常和中断的处理机制基本一致。
4.2具体的切换步骤
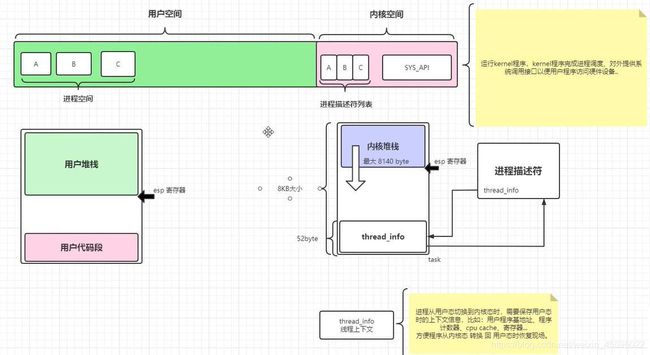
从当前进程的描述符中提取其内核栈的ss0及esp0信息。
使用ss0和esp0指向的内核栈将当前进程的cs,eip,eflags,ss,esp信息保存起来,这个过程也完成了由用户栈到内核栈的切换过程,同时保存了被暂停执行的程序的下一条指令。
将先前由中断向量检索得到的中断处理程序的cs,eip信息装入相应的寄存器,开始执行中断处理程序,这时就转到了内核态的程序执行了。
5.缓冲区读写

三,虚拟内存
1.物理内存

物理内存的查找效率是O1.
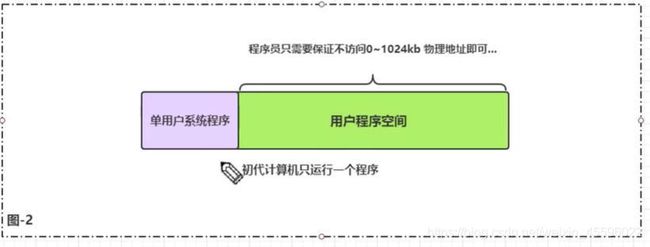
2.单用户操作系统
程序员只要确保自己不访问内核占用的物理地址,其他的物理内存随便操作。
3.多用户操作系统
多个程序员在写多个程序之前,需要互相确定好每个人要是用的物理内存地址,不能占用到他人的物理内存。
但是假如有人故意写程序去搞破坏,就会出现很严重的问题。
空间垂直切分,导致每个人的可用空间都很小。

4.虚拟内存
虚拟内存由此产生,程序员不再直接操作物理内存,而是操作虚拟内存。虚拟内存映射某一段物理内存,而且虚拟内存可以比物理内存大。
操作系统会利用LRU算法将最近最好使用的内存转置到磁盘的swap区。
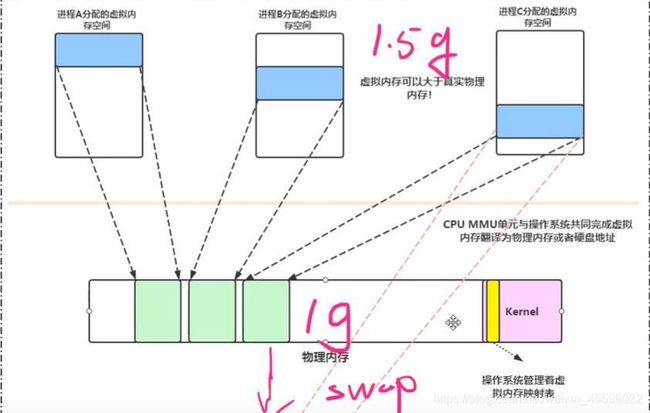
零拷贝思想:利用虚拟内存,让用户空间的缓冲区和内核空间的缓冲区映射到同一块物理内存,减少一次拷贝。
DMA控制器将数据从硬盘拷贝到内核空间的缓冲区,由于内核空间的缓冲区映射的物理内存地址和用户空间的缓冲区映射的物理内存地址是同一块,就不需要在将数据从内核空间缓冲区拷贝到用户空间缓冲区,减少了一次拷贝。

四,传统IO
1.BIO
bio是面向流的网络通信

如图:将硬盘数据从网络传输出去。
1.DM复制硬盘数据到内核缓冲区。
2.cpu将数据从内核缓冲区复制到用户缓冲区
3.cpu将数据从用户缓冲区复制到内核的socket缓冲区域
4.DMA将数据从socket缓冲区复制到网络
此处的复制:先读取数据,然后写出。
整个过程涉及到一次内核态到用户态再到内核态的切换。
2.NIO
NIO:非阻塞切面向块的网络通信
客户端与服务端通过channel进行传输buffer,buffer实际上就是(index,position,capacity);在java层面可以看做是堆空间的一个字节数组,通过socket传输到另一端,但是由于可能碰上传输过程中恰好出现Full GC,那么就会出现问题。所以jvm为了解决这个问题,使用到了堆外内存技术。他会首先将堆空间要传输的字节数组复制到堆外的一块空间,然后在进行socket传输。
堆内到堆外的拷贝就不怕FULL GC的影响么? 实际上是在安全点之外进行的,碰不上FULL GC。
五,两个系统函数
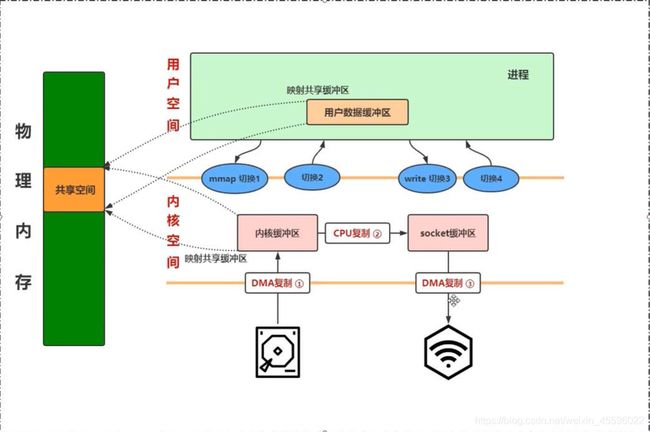
1.mmap+write
mmap特性:将磁盘上的文件映射到内存一份
1.DMA将数据从硬盘复制到内核缓冲区映射的物理内存
2.由于用户数据缓冲区和内核缓冲区映射同一块物理内存地址,就减少了从内核缓冲区拷贝数据到用户缓冲区的过程。
3.CPU将数据从内核缓冲区复制到socket缓冲区
4.DMA将数据从socket缓冲区复制到网络进行传输。
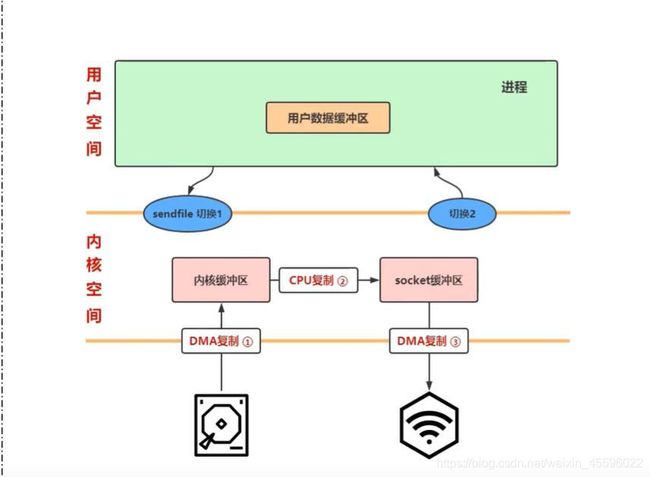
2.sendfile
sendfile(文件描述符,socket描述符)
1.DMA将数据从硬盘复制到内核缓冲区
2.CPU根据函数传递的两个参数将文件从内核缓冲区复制到socket缓冲区
3.DMA将数据从socket缓冲区复制到网络
六,堆外内存
1.堆外内存如何申请?
堆外内存可以通过java.nio的ByteBuffer来创建,调用allocateDirect方法申请即可。
2.堆外内存如何回收?
import sun.nio.ch.DirectBuffer;
public static void clean(final ByteBuffer byteBuffer) {
if (byteBuffer.isDirect()) {
((DirectBuffer)byteBuffer).cleaner().clean();
}
}
七,java如何实现零拷贝的?
1.transferTo
File file = new File("a.txt");
RandomAccessFile raf = new RandomAccessFile(file, "rw");
FileChannel fileChannel = raf.getChannel();
SocketChannel socketChannel = SocketChannel.open(new InetSocketAddress("", 1234));
// 直接使用了transferTo()进行通道间的数据传输
fileChannel.transferTo(0, fileChannel.size(), socketChannel);
NIO的零拷贝由transferTo()方法实现。transferTo()方法将数据从FileChannel对象传送到可写的字节通道(如Socket Channel等)。在内部实现中,由native方法transferTo0()来实现,它依赖底层操作系统的支持。在UNIX和Linux系统中,调用这个方法将会引起sendfile()系统调用。
适用场景
1.较大,读写较慢,追求速度
2.M内存不走,不能加载太大数据
3.带宽不够,即还有其他程序在大量IO
2.map
File file = new File("a.txt");
RandomAccessFile raf = new RandomAccessFile(file, "rw");
FileChannel fileChannel = raf.getChannel();
MappedByteBuffer buffer = fileChannel.map(FileChannel.MapMode.READ_ONLY, 0, fileChannel.size());
它的作用位置处于传统IO(BIO)与零拷贝之间
IO:可以把磁盘的文件经过内核空间,读到JVM空间,然后进行各种操作,最后再写到磁盘或是发送到网络,效率较慢但支持数据文件操作。
零拷贝:直接在内核空间完成文件读取并转到磁盘(或发送到网络)。由于它没有读取文件数据到JVM这一环,因此程序无法操作该文件数据,尽管效率很高!
直接内存则介于两者之间,效率一般且可操作文件数据。直接内存(mmap技术)将文件直接映射到内核空间的内存,返回一个操作地址(address),它解决了文件数据需要拷贝到JVM才能进行操作的窘境。而是直接在内核空间直接进行操作,省去了内核空间拷贝到用户空间这一步操作。其实说白了就是用了mmap函数。
NIO的直接内存是由MappedByteBuffer实现的。核心即是map()方法,该方法把文件映射到内存中,获得内存地址addr,然后通过这个addr构造MappedByteBuffer类,以暴露各种文件操作API。
由于MappedByteBuffer申请的是堆外内存,因此不受Minor GC控制,只能在发生Full GC时才能被回收。而DirectByteBuffer改善了这一情况,它是MappedByteBuffer类的子类,同时它实现了DirectBuffer接口,维护一个Cleaner对象来完成内存回收。因此它既可以通过Full GC来回收内存,也可以调用clean()方法来进行回收。