分库分表 Sharding-JDBC (详解 1/6)
-
狂创客圈 经典图书 : 《Netty Zookeeper Redis 高并发实战》 面试必备 + 面试必备 + 面试必备 【博客园总入口 】
-
疯狂创客圈 经典图书 : 《SpringCloud、Nginx高并发核心编程》 大厂必备 + 大厂必备 + 大厂必备 【博客园总入口 】
-
入大厂+涨工资必备: 高并发【 亿级流量IM实战】 实战系列 【 SpringCloud Nginx秒杀】 实战系列 【博客园总入口 】
目录:分库分表 Sharding-JDBC从入门到精通
| 主题 | 链接地址 |
|---|---|
| 准备1: 在window安装虚拟机集群 | 分布式 虚拟机 linux 环境制作 GO |
| 准备2:在虚拟机的各个节点有 mysql | centos mysql 笔记(内含vagrant mysql 镜像)GO |
| 分库分表 -Sharding-JDBC- 从入门到精通 1 | Sharding-JDBC 分库、分表(入门实战) GO |
| 分库分表 -Sharding-JDBC- 从入门到精通 2 | Sharding-JDBC 基础知识 GO |
| 分库分表 Sharding-JDBC 从入门到精通之 3 | 自定义主键、分布式雪花主键,原理与实战 GO |
| 分库分表 -Sharding-JDBC- 从入门到精通 4 | MYSQL集群主从复制,原理与实战 GO |
| 分库分表 Sharding-JDBC 从入门到精通之 5 | 读写分离 实战 GO |
| 分库分表 Sharding-JDBC 从入门到精通之 6 | Sharding-JDBC执行原理 GO |
| 分库分表 Sharding-JDBC 从入门到精通之源码 | git仓库地址GO |
1.有关Sharding-JDBC
有关Sharding-JDBC介绍这里就不在多说,之前Sharding-JDBC是当当网自研的关系型数据库的水平扩展框架,现在已经捐献给Apache,其原理请参见后面的博客。
shardingsphere文档地址是:https://shardingsphere.apache.org/document/current/cn/overview/。
2 Sharding-JDBC 实战的场景
在深入了解之前,先实战一把,增加印象, 激发兴趣。
一般情况下,大家都会使用水平切分库和表:将一张表水平切分成多张表,还可以放到多个库中。这就涉及到数据分片的规则,比较常见的有:Hash取模分表、数值Range分表、一致性Hash算法分表。
1、Hash取模分表
概念 一般采用Hash取模的切分方式,例如:假设按goods_id分4张表。(goods_id%4 取整确定表)
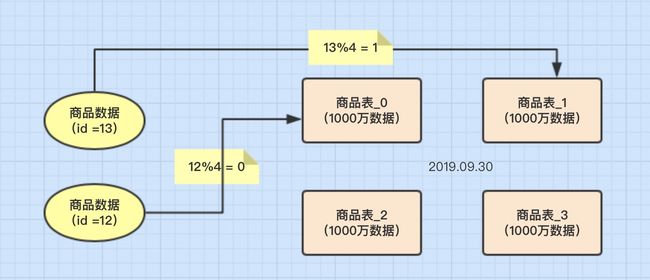
优点
- 数据分片相对比较均匀,不容易出现热点和并发访问的瓶颈。
缺点
-
后期分片集群扩容时,需要迁移旧的数据很难。
-
容易面临跨分片查询的复杂问题。比如上例中,如果频繁用到的查询条件中不带goods_id时,将会导致无法定位数据库,从而需要同时向4个库发起查询,
再在内存中合并数据,取最小集返回给应用,分库反而成为拖累。
2、数值Range分表
概念 按照时间区间或ID区间来切分。例如:将goods_id为11000的记录分到第一个表,10012000的分到第二个表,以此类推。
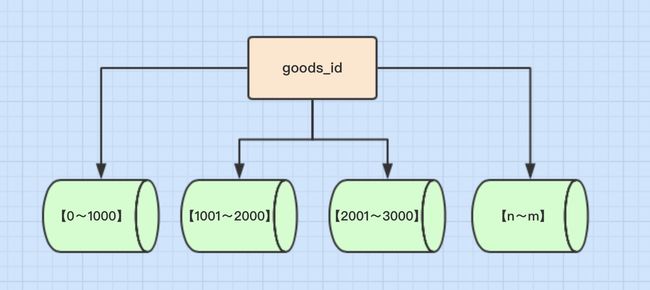
优点
- 单表大小可控
- 天然便于水平扩展,后期如果想对整个分片集群扩容时,只需要添加节点即可,无需对其他分片的数据进行迁移
- 使用分片字段进行范围查找时,连续分片可快速定位分片进行快速查询,有效避免跨分片查询的问题。
缺点
- 热点数据成为性能瓶颈。
例如按时间字段分片,有些分片存储最近时间段内的数据,可能会被频繁的读写,而有些分片存储的历史数据,则很少被查询
3、一致性Hash算法
一致性Hash算法能很好的解决因为Hash取模而产生的分片集群扩容时,需要迁移旧的数据的难题。至于具体原理这里就不详细说,
可以参考一篇博客:一致性哈希算法(分库分表,负载均衡等)
4、实战:简单的Hash取模分表
假设一个订单表的user_id和order_id 分布较为均匀,按照1000W的数据规模,可以使用如下的分库、分表结构来保存:
db0
├── t_order0
└── t_order1
db1
├── t_order0
└── t_order1
简单的进行分库分表: 按照user_id %2 的规则进行分库,按照 order_id %2 的规则进行分表
3 库表的结构设计:
3.1 逻辑订单表
逻辑订单表的结构如下:

3.2 节点1 (cdh1)上的订单库
DROP TABLE IF EXISTS `t_order_0`;
DROP TABLE IF EXISTS `t_order_1`;
DROP TABLE IF EXISTS `t_config`;
CREATE TABLE `t_order_0` (`order_id` bigInt NOT NULL, `user_id` INT NOT NULL, `status` VARCHAR(45) NULL, PRIMARY KEY (`order_id`));
CREATE TABLE `t_order_1` (`order_id` bigInt NOT NULL, `user_id` INT NOT NULL, `status` VARCHAR(45) NULL, PRIMARY KEY (`order_id`));
3.3 节点2 (cdh2)上的订单库
DROP TABLE IF EXISTS `t_order_0`;
DROP TABLE IF EXISTS `t_order_1`;
DROP TABLE IF EXISTS `t_config`;
CREATE TABLE `t_order_0` (`order_id` bigInt NOT NULL, `user_id` INT NOT NULL, `status` VARCHAR(45) NULL, PRIMARY KEY (`order_id`));
CREATE TABLE `t_order_1` (`order_id` bigInt NOT NULL, `user_id` INT NOT NULL, `status` VARCHAR(45) NULL, PRIMARY KEY (`order_id`));
两个db上,都有t_order_0,和t_order_1两个表
4 Sharding-JDBC 分库分表配置
- 分库
本文分库样例比较简单,根据数据库表中字段user_id%2进行判断,如果user_id%2==0则使用ds0,否则使用ds1。
- 分表
分样例比较简单,根据数据库表中字段order_id%2进行判断,如果order_id%2==0则使用t_order_0,否则使用t_order_1。
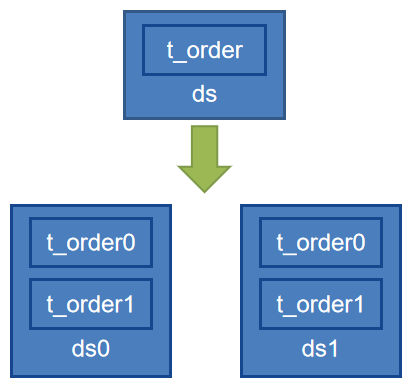
对 t_order 表进行的如下图所示的数据表水平 分库和分表,具体如下图所示:
(对 t_order_item 表也要进行类似的水平分片,但是这部分配置省略了):
在 yml 配置文件中,可以使用 Groovy 表达式,进行分库分表的规则配置,具体的 Groovy 表达式如下:
表达式一: 例如 ds0.t_order_0
ds$->{0..1}.t_order_$->{0..1}
表达式一:db 维度的拆分, 例如 ds_0、ds_1
ds_${user_id % 2}
表达式一:table 维度的拆分, 例如 t_order_1
t_order_${order_id % 2}
这些表达式被称为 Groovy 表达式,它们的含义很容易识别:
1)对 t_order 进行两种维度的拆分:db 维度和 table 维度;
2)在db 维度,user_id % 2 == 0 的记录全部落到 ds0,user_id % 2 == 1 的记录全部落到 ds1;(有人称这一过程为水平分库,其实它的本质还是在水平地分表,只不过依据表中 user_id 的不同把拆分的后的表放入两个数据库实例。)
3)在表维度,order_id% 2 == 0 的记录全部落到 t_order0,order_id% 2 == 1 的记录全部落到 t_order1。
4)对记录的读和写都按照这种方向进行,“方向”,就是分片方式,就是路由。
使用这种简洁的 Groovy 表达式, 可以设置的分片策略和分片算法。但是这种方式所能表达的含义是有限的。因此,官方提供了分片策略接口和分片算法接口,让你们利用 Java 代码尽情表达更为复杂的分片策略和分片算法。
实际上,分片算法是分片策略的组成部分,分片策略设置=分片键设置+分片算法设置。上述配置里使用的策略是 Inline 类型的分片策略,使用的算法是 Inline 类型的行表达式算法。
具体的配置如下:
spring:
application:
name: sharding-jdbc-provider
jpa: #配置自动建表:updata:没有表新建,有表更新操作,控制台显示建表语句
hibernate:
ddl-auto: none
dialect: org.hibernate.dialect.MySQL5InnoDBDialect
show-sql: true
freemarker:
allow-request-override: false
allow-session-override: false
cache: false
charset: UTF-8
check-template-location: true
content-type: text/html
enabled: true
expose-request-attributes: false
expose-session-attributes: false
expose-spring-macro-helpers: true
prefer-file-system-access: true
settings:
classic_compatible: true
default_encoding: UTF-8
template_update_delay: 0
suffix: .ftl
template-loader-path: classpath:/templates/
shardingsphere:
props:
sql:
show: true
# 配置真实数据源
datasource:
common:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
validationQuery: SELECT 1 FROM DUAL
names: ds0,ds1
ds0:
url: jdbc:mysql://cdh1:3306/store?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&useSSL=true&serverTimezone=UTC
username: root
password: 123456
# 配置第 2 个数据源 org.apache.commons.dbcp2
ds1:
url: jdbc:mysql://cdh2:3306/store?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&useSSL=true&serverTimezone=UTC
username: root
password: 123456
# 配置分片规则和分片算法
rules:
# 配置分片规则
sharding:
tables:
# 配置 t_order 表规则
t_order:
actualDataNodes: ds$->{0..1}.t_order_$->{0..1}
# 配置分库策略
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: database-inline
# 配置分表策略
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: table-inline
keyGenerateStrategy:
column: order_id
keyGeneratorName: snowflake
# 配置分片算法
bindingTables: t_order
sharding-algorithms:
database-inline:
type: INLINE
props:
algorithm-expression: ds$->{user_id % 2}
table-inline:
type: INLINE
props:
algorithm-expression: t_order_$->{order_id % 2}
keyGenerators:
snowflake:
type: SNOWFLAKE
props:
workerId: 123
5.代码实现
本文使用SpringBoot2,SpringData-JPA,Druid连接池,和当当的sharding-jdbc 5。
5.1 依赖文件
新建项目,加入当当的sharding-jdbc-core依赖和druid连接池。请参见源码工程。
5.2 启动类
使用@EnableTransactionManagement开启事务,
使用@EnableConfigurationProperties注解加入配置实体,启动类完整代码请入所示。
package com.crazymaker.springcloud.sharding.jdbc.demo.start;
@EnableConfigurationProperties
@SpringBootApplication(scanBasePackages =
{"com.crazymaker.springcloud.sharding.jdbc.demo",
// "com.crazymaker.springcloud.base",
// "com.crazymaker.springcloud.standard"
}, exclude = {
DataSourceAutoConfiguration.class,
SecurityAutoConfiguration.class,
DruidDataSourceAutoConfigure.class})
@EnableScheduling
@EnableSwagger2
@EnableJpaRepositories(basePackages = {
"com.crazymaker.springcloud.sharding.jdbc.demo.dao.impl",
// "com.crazymaker.springcloud.base.dao"
})
@EnableTransactionManagement(proxyTargetClass = true)
@EntityScan(basePackages = {
// "com.crazymaker.springcloud.user.*.dao.po",
"com.crazymaker.springcloud.sharding.jdbc.demo.entity.jpa",
// "com.crazymaker.springcloud.standard.*.dao.po"
})
/**
* 启用 Hystrix
*/
@EnableHystrix
@EnableFeignClients(
basePackages = "com.crazymaker.springcloud.user.info.remote.client",
defaultConfiguration = FeignConfiguration.class)
@Slf4j
@EnableEurekaClient
public class ShardingJdbcDemoCloudApplication
{
public static void main(String[] args)
{
ConfigurableApplicationContext applicationContext = SpringApplication.run(ShardingJdbcDemoCloudApplication.class, args);
Environment env = applicationContext.getEnvironment();
String port = env.getProperty("server.port");
String path = env.getProperty("server.servlet.context-path");
System.out.println("\n----------------------------------------------------------\n\t" +
"Application is running! Access URLs:\n\t" +
"Local: \t\thttp://localhost:" + port + path + "/index.html\n\t" +
"swagger-ui: \thttp://localhost:" + port + path + "/swagger-ui.html\n\t" +
"----------------------------------------------------------");
}
}
5.3实体类和数据库操作层
就是简单的实体和Repository,更多详细内容请参见源码工程。
/*
* Copyright 2016-2018 shardingsphere.io.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*
*/
package com.crazymaker.springcloud.sharding.jdbc.demo.entity.jpa;
import com.crazymaker.springcloud.sharding.jdbc.demo.entity.Order;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.Table;
@Entity
@Table(name = "t_order")
public final class OrderEntity extends Order
{
@Id
@Column(name = "order_id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Override
public long getOrderId() {
return super.getOrderId();
}
@Column(name = "user_id")
@Override
public int getUserId() {
return super.getUserId();
}
@Column(name = "status")
public String getStatus() {
return super.getStatus();
}
}

5.4 服务层
更多详细内容请参见源码工程。
5.4 Controller
接下来创建一个Controller进行测试,保存方法使用了插入数据和查看数据,根据我们的规则,会每个库插入数据,同时我这里还创建了一个查询方法,查询全部订单。
package com.crazymaker.springcloud.sharding.jdbc.demo.controller;
@RestController
@RequestMapping("/api/sharding/")
@Api(tags = "sharding jdbc 演示")
public class ShardingJdbcController
{
@Resource
JpaEntityService jpaEntityService;
@PostMapping("/order/add/v1")
@ApiOperation(value = "插入订单")
public RestOut orderAdd(@RequestBody Order dto)
{
jpaEntityService.addOrder(dto);
return RestOut.success(dto);
}
@PostMapping("/order/list/v1")
@ApiOperation(value = "查询订单")
public RestOut> listAll()
{
List list = jpaEntityService.selectAll();
return RestOut.success(list);
}
}
6 执行测试
6.1 打开swagger
启动应用。
然后,在浏览器或HTTP请求工具访问http://localhost:7700/sharding-jdbc-provider/swagger-ui.html,如图所示
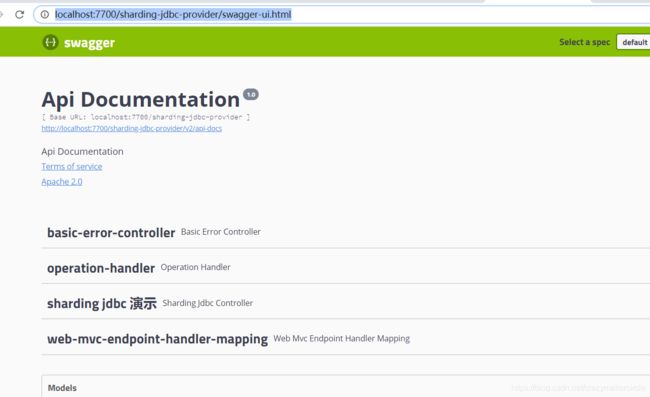
6.2 加入两条数据

使用插入订单的接口,可以插入订单, 注意 userid %2 ==0 进入 db1, 注意 userid %2 ==1进入 db2, 具体在哪个表呢?
因为 orderid是通过雪花算法生成的,如果orderid%2==0 ,则进入t_order_0,否则使用t_order_1。
插入之后,可以通过数据库,看结果。具体如下图:
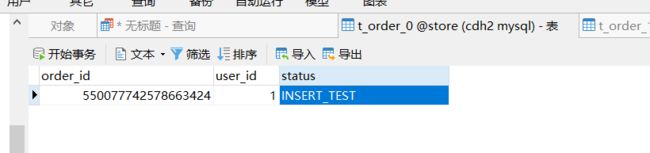
6.3 查看数据
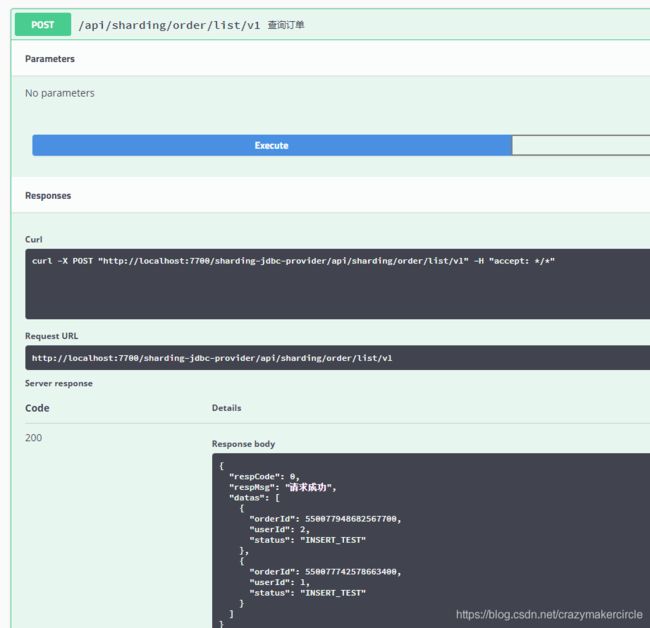
使用程序的查询全部的方法,shardingjdbc ,会查出所有的订单。
7 总结
使用shardingjdbc ,除了数据源的配置有些特殊的规则外, 持久层程序和普通的 JPA代码,区别并不大。
当然,如果要实现特殊的分库分表逻辑,还是需要动代码的,请看后续分解。
回到◀疯狂创客圈▶
疯狂创客圈 - Java高并发研习社群,为大家开启大厂之门