转:利用python调用谷歌翻译API
废话少说
从速卖通抓取了一些评论想进行一些简单的文本分析,但是因为速卖通是一个跨境电商平台,上边的评论基本都是小语种,对,小语种,俄语,法语...英语还可以勉强应付一下,但是其他真的是一个字母都不认识啊,所以我就想能不能用python解决这个问题。
知名的翻译(我听说的)就是谷歌,百度,有道,有道翻译英语还行,小语种效果太差了,直接放弃,经过对比百度和谷歌,准确率上还是谷歌更准确一点,毕竟谷歌搜索是全世界的人为其提供训练语料,而百度基本只有中国人在用。
但是,良心百度提供了翻译API接口,而谷歌没有,哎没办法,只能爬了...
正文
首先用chrome打开谷歌搜翻译,看看它是怎么请求数据的
右键 检查 进入开发者工具
选择network,如图
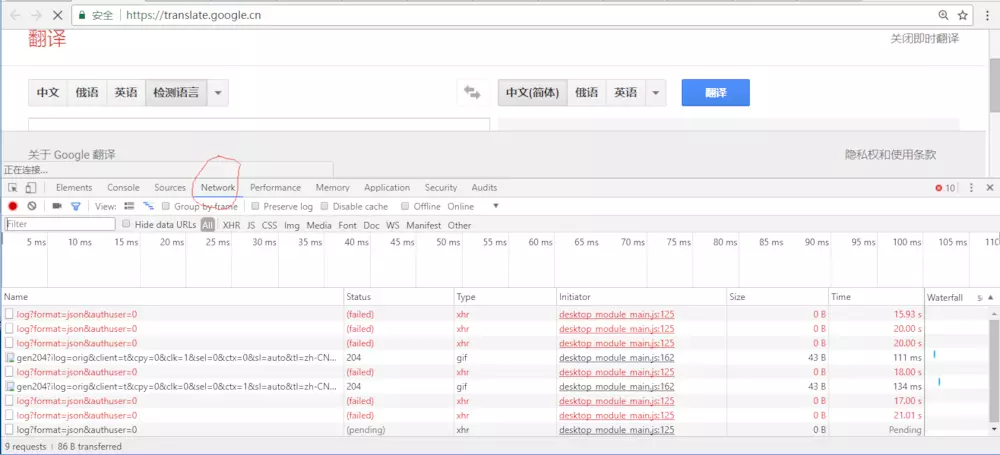
image.png
先点击一下这个clear,把原来的请求都clear(当然是视觉上clear)
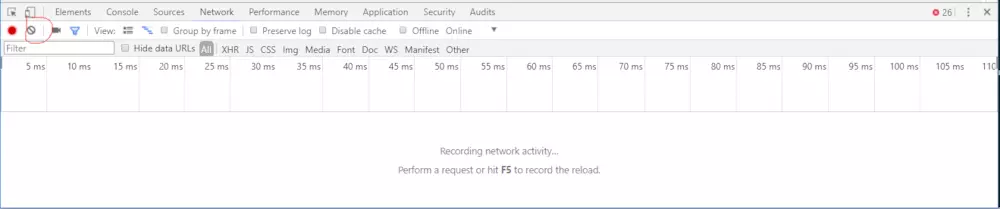
image.png
输入测试翻译内容

image.png
我们很快得到了翻译结果,同时得到了下面几个新的请求,那么返回的结果肯定在下面这几个请求,因为之前已经clear掉了,所以新的请求并不多(测试前,先clear,这个技巧很重要,特别是对于那种电商网站,请求分分钟几十上百,你不先clear掉的话,要找到猴年马月)
我们很快就可以发现是下面这个请求返回了翻译结果

image.png

image.png
通过请求头信息,可以发现是get请求,请求翻译的内容是通过q这个参数传递的,其它参数暂时不知道什么意思。然后,我们就可以用requests库模仿这个请求,看看能否成功。
import requests
res=requests.get('https://translate.google.cn/translate_a/single?client=t&sl=auto&tl=zh-CN&hl=zh-CN&dt=at&dt=bd&dt=ex&dt=ld&dt=md&dt=qca&dt=rw&dt=rm&dt=ss&dt=t&ie=UTF-8&oe=UTF-8&otf=1&ssel=0&tsel=0&kc=7&tk=272537.149261&q=oh%20shit')
print(res.text)

image.png
直接成功,谷歌翻译这么好爬的嘛?感觉不靠谱,把q后面的内容换成hello,果然不行了,报了403,服务器禁止了。哎,我还是太naive啊
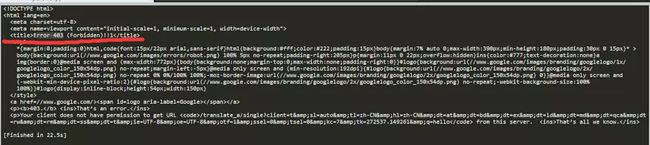
image.png
那么,肯定请求参数里还有一些参数是实时根据内容变化的,很容易注意的tk这个参数。tk=272537.149261,一串数字,你在谷歌翻译里换其它字符串测试,就会发现其它参数基本都一样,只有这个tk不一样.但是呢?以我目前这个水平,是没有能力破解的,于是百度之。果然有大神已经破解了这个tk,但是因为tk的生成是js生成的,所以很多人直接选择了node.js来实现这个爬虫,但是我已经习惯了强大方便的python requests库,所以还是选择继续用python,找了很久才找到python 版本,现在分享出来。
import requests
import json
from bs4 import BeautifulSoup
import execjs #必须,需要先用pip 安装,用来执行js脚本
class Py4Js():
def __init__(self):
self.ctx = execjs.compile("""
function TL(a) {
var k = "";
var b = 406644;
var b1 = 3293161072;
var jd = ".";
var $b = "+-a^+6";
var Zb = "+-3^+b+-f";
for (var e = [], f = 0, g = 0; g < a.length; g++) {
var m = a.charCodeAt(g);
128 > m ? e[f++] = m : (2048 > m ? e[f++] = m >> 6 | 192 : (55296 == (m & 64512) && g + 1 < a.length && 56320 == (a.charCodeAt(g + 1) & 64512) ? (m = 65536 + ((m & 1023) << 10) + (a.charCodeAt(++g) & 1023),
e[f++] = m >> 18 | 240,
e[f++] = m >> 12 & 63 | 128) : e[f++] = m >> 12 | 224,
e[f++] = m >> 6 & 63 | 128),
e[f++] = m & 63 | 128)
}
a = b;
for (f = 0; f < e.length; f++) a += e[f],
a = RL(a, $b);
a = RL(a, Zb);
a ^= b1 || 0;
0 > a && (a = (a & 2147483647) + 2147483648);
a %= 1E6;
return a.toString() + jd + (a ^ b)
};
function RL(a, b) {
var t = "a";
var Yb = "+";
for (var c = 0; c < b.length - 2; c += 3) {
var d = b.charAt(c + 2),
d = d >= t ? d.charCodeAt(0) - 87 : Number(d),
d = b.charAt(c + 1) == Yb ? a >>> d: a << d;
a = b.charAt(c) == Yb ? a + d & 4294967295 : a ^ d
}
return a
}
""")
def getTk(self,text):
return self.ctx.call("TL",text)
def buildUrl(text,tk):
baseUrl='https://translate.google.cn/translate_a/single'
baseUrl+='?client=t&'
baseUrl+='s1=auto&'
baseUrl+='t1=zh-CN&'
baseUrl+='h1=zh-CN&'
baseUrl+='dt=at&'
baseUrl+='dt=bd&'
baseUrl+='dt=ex&'
baseUrl+='dt=ld&'
baseUrl+='dt=md&'
baseUrl+='dt=qca&'
baseUrl+='dt=rw&'
baseUrl+='dt=rm&'
baseUrl+='dt=ss&'
baseUrl+='dt=t&'
baseUrl+='ie=UTF-8&'
baseUrl+='oe=UTF-8&'
baseUrl+='otf=1&'
baseUrl+='pc=1&'
baseUrl+='ssel=0&'
baseUrl+='tsel=0&'
baseUrl+='kc=2&'
baseUrl+='tk='+str(tk)+'&'
baseUrl+='q='+text
return baseUrl
def translate(text):
header={
'authority':'translate.google.cn',
'method':'GET',
'path':'',
'scheme':'https',
'accept':'*/*',
'accept-encoding':'gzip, deflate, br',
'accept-language':'zh-CN,zh;q=0.9',
'cookie':'',
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36',
'x-client-data':'CIa2yQEIpbbJAQjBtskBCPqcygEIqZ3KAQioo8oBGJGjygE='
}
url=buildUrl(text,js.getTk(text))
res=''
try:
r=requests.get(url)
result=json.loads(r.text)
if result[7]!=None:
# 如果我们文本输错,提示你是不是要找xxx的话,那么重新把xxx正确的翻译之后返回
try:
correctText=result[7][0].replace('',' ').replace('','')
print(correctText)
correctUrl=buildUrl(correctText,js.getTk(correctText))
correctR=requests.get(correctUrl)
newResult=json.loads(correctR.text)
res=newResult[0][0][0]
except Exception as e:
print(e)
res=result[0][0][0]
else:
res=result[0][0][0]
except Exception as e:
res=''
print(url)
print("翻译"+text+"失败")
print("错误信息:")
print(e)
finally:
return res
if __name__ == '__main__':
js=Py4Js()
res=translate('Всё качественно и быстро!')
print(res)
最后
谷歌返回的结果是一个json格式的数据,我们将其变成一个嵌套的list,可以发现该list长度为9,第零个元素就是翻译结果,第七个结果是一些提示信息。如图
image.png
当有提示信息的时候,我们将正确的信息重新翻译一遍,返回。
其次翻译之前一定要先分句,因为我测试这样准确率更高一点,直接一段翻译有时候会面貌全非,但是分开一句句翻译,基本就是人话了。
我目前连续测试上千条语句还没有问题,但是速度有快有慢,而且有时候,如果数据量太大的话,可以采用每翻译一句sleep(1),或者使用代理IP
作者:想酷却酷不起来
链接:https://www.jianshu.com/p/95cf6e73d6ee
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
注意以下几点:
1、import execjs失败,解决方法如下:
pip install PyExecJS #python3安装
pip install pyexecjs #python2安装
2、请更改自己网页的baseUrl参数,还有header的user-agent、x-client-data参数。