Zookeeper集群节点为什么要部署成奇数
Zookeeper集群节点为什么要部署成奇数
Zookeeper集群节点数量为什么必须为奇数呢?我们在刚接触这个问题的时候,可能会以为是Zookeeper的选举机制中要求少数服从多数,我们必须是奇数,否则无法进行正常的选举。那么答案真的是这样么?
其实我们在了解了Zookeeper集群一致性协议—— ZAB算法 之后,发现了其实根本不是这样,我们会发现在Zookeeper的ZAB协议中,在崩溃恢复中选举Leader的时候,投票时会有一个处理逻辑:优先比较ZXID,然后比较myid,又根据我们在Zookeeper集群部署 中部署Zookeeper集群的例子中,发现即时ZXID相同,我们也可以通过比较myid来选举出Leader节点(myid肯定不会相同)。
另外我们还可以了解一下一致性协议—— Paxos算法 ,这其中也是只要求得到大多数的投票才会通过,所以我们部署偶数台,也是可以的,而不会是偶数节点可能导致票数相同的情况,即不会因为偶数节点可能导致票数相同的情况,因为不过半数是失败的。
上述都是在我们学习了Paxos算法以及ZAB算法,从理论上得出的结论,那么我们可以来实际的例子验证一下,现在我们就来按照之前Zookeeper集群部署介绍的步骤来部署一个2个节点的Zookeeper集群,我们来测试一下是否能够成功
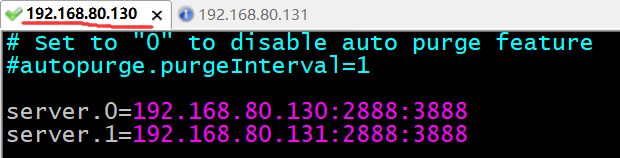

然后我们就可来启动这两台机器了,如下:

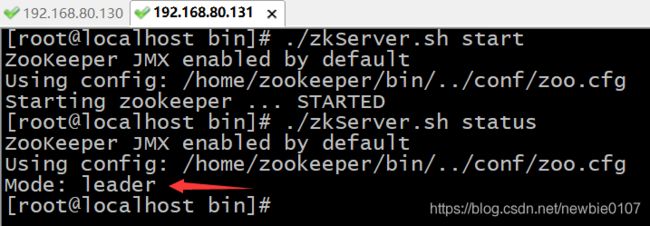
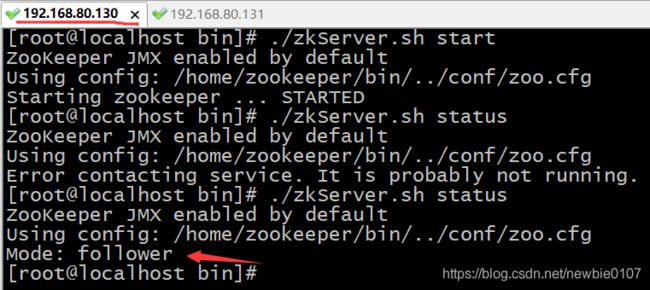
发现我们Zookeeper集群节点数量为2,即偶数台也是可以进行成功部署的。
那么Zookeeper集群节点为什么要部署成奇数呢?,如果不是因为偶数会导致无法选举,那么原因是什么呢?
是因为Zookeeper集群有这样一个特性:集群中只要有过半的机器是正常工作的,那么整个集群对外就是可用的。
也就是说如果有3个Zookeeper 节点,如果有1个Zookeeper 节点死了,还剩下2个正常的节点,存活的节点数过半,Zookeeper服务依旧可以使用。但是如果2个Zookeeper 节点死了,只剩下1个正常的节点,存活的节点数不过半,那么Zookeeper服务就不能用了。
同理如果有4个Zookeeper 节点,如果有1个Zookeeper 节点死了,还剩下3个正常的节点,存活的节点数过半,Zookeeper服务依旧可以使用。但是如果2个Zookeeper 节点死了,只剩下2个正常的节点,存活的节点数不过半,那么Zookeeper服务就不能用了。
我们可以从上发送3个Zookeeper 节点和4个Zookeeper节点的容灾能力是一样的,同理可以发现5和6个Zookeeper节点、7和8个Zookeeper节点等等的容灾能力都是一样的,即 2n 和 2n-1 的容灾是一样的,所以为了更加高效,何必增加那一个不必要的zookeeper呢。所以说,根据以上可以得出结论:从资源节省的角度来考虑,Zookeeper集群的节点最好要部署奇数
Zookeeper集群中为什么要求过半的机器是正常工作的,整个集群对外才是可用的
不过接下来我们可能有有新的问题了,为什么Zookeeper集群会有这样一个特性呢?集群中只要有过半的机器是正常工作的,那么整个集群对外就是可用的。 这一特性其实非常好理解,因为在Paxos算法和ZAB算法中,我们在进行投票选举时,都是要是少数服从多数的呀,想要通过一个提案,必须获得大多数节点的同意,所以如果集群中必须有过半的机器存活,才可以通过投票选举的。
(注意: 在ZAB算法中,并不是简单的优先比较ZXID,然后比较myid,就直接选举出新的Leader了,这里比较完之后,各个节点会进行比较结果,进行重新投票,然后还是依据少数服从多数的原则)。
过半机制的作用
明白了上述的原因,我们又可以提出疑问了,为什么Paxos算法和ZAB算法中都要求过半机制呢?因为过半机制可以解决我们在分布式系统——CAP理论及BASE理论 中到过分布式系统的会带来的常见问题,如:通信异常、网络分区、三态、节点故障 ,这里我们来看一看如果通过过半机制来避免网络分区,及脑裂问题。
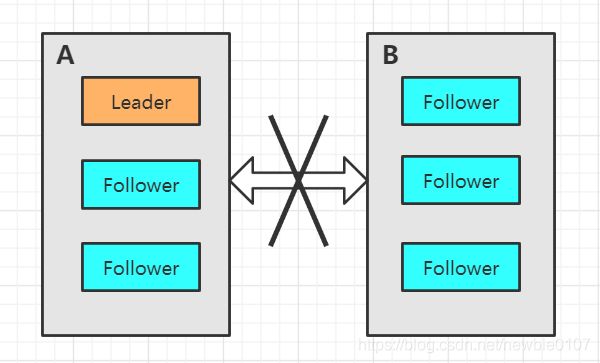
首先我们再来详细了解一下脑裂问题,现在如果有5台机器部署了一个Zookeeper集群,但是他们分布在两个地方A和B,其中A区域3台,B区域2台,如下所示:
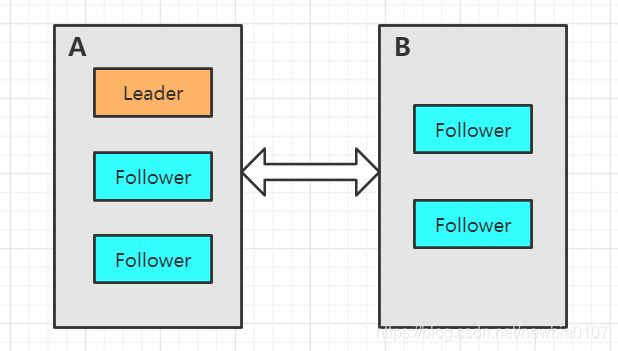
这时突然产生了网络问题,Zookeeper集群的AB区域现在因为网络问题无法进行相互通信,但是区域彼此内是可以进行通信的。
现在假设没有过半机制的限制,因为A区域内存在Leader节点,是没有影响的,但是B区域内出现了问题,现在无法和A区域通信了,所以现在B区域会进行选举Leader,因为现在假设没有过半机制的限制,所以可以选举成功,如下:
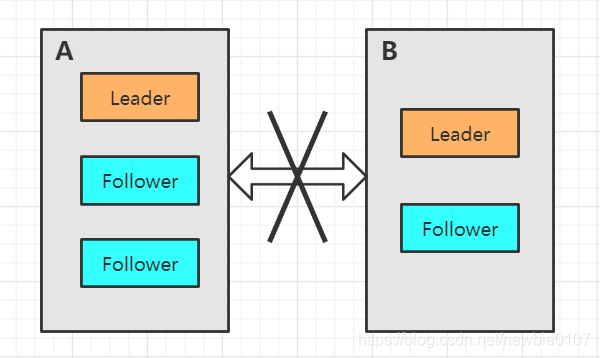
这就相当于原本一个集群,被分成了两个集群,出现了两个Leader,这就是所谓的"脑裂"现象。对于这种情况,其实也可以看出来,原本应该是统一的一个集群对外提供服务的,现在变成了两个集群同时对外提供服务。
假设网络突然又恢复了,区域AB彼此之间又可以进行通信了,那么此时就会出现问题了,两个集群刚刚都对外提供服务了,数据该怎么合并,数据冲突怎么解决等等问题。上述的场景发生时有一个前提条件就是没有考虑过半机制,所以实际上Zookeeper集群中是不会轻易出现脑裂问题的,原因在于过半机制。
因为存在过半机制,区域B中就不可能重新选举出新的Leader,区域B也不会向外部提供服务,等待网络恢复之后,区域B会从区域A中进行数据同步,保证了其一致性。
其实过半机制不仅仅可以避免脑裂的问题,它还可以帮助我们快速选举,因为过半机制,相比于2PC/3PC来说,我们就不需要等待所有节点都投了同一个节点就可以选举出来一个Leader了,这样比较快,所以叫快速领导者选举算法。
那么我们Zookeeper集群节点为什么要部署成奇数的原因就是上述了么?其实还不仅仅是上述节省资源成本的角度,还有一个目的就是,部署奇数可以提高Zookeeper服务的容灾能力,如上述发生了网络问题,区域A、B总有一个可以向外部提供服务,因为部署奇数,无论区域A、B如何划分,都可以选举出一个Leader(或者是原本的Leader)来管理服务。
但是如果部署偶数台,区域A、B的情况如下,那么因为过半机制的原因,是无法从外部提供服务的,那么整个Zookeeper集群就崩溃了。