系统重温Pandas笔记:Task Special:第一次综合练习
文章目录
-
- 【任务一】企业收入的多样性
- 【任务二】组队学习信息表的变换
- 【任务三】漂亮国投票情况
- 远昊大佬的参考答案
-
- 第一题
- 第二题
- 第三题
【任务一】企业收入的多样性
【题目描述】一个企业的产业收入多样性可以仿照信息熵的概念来定义收入熵指标:

【数据下载】链接:https://pan.baidu.com/s/1leZZctxMUSW55kZY5WwgIw 53 密码:u6fd
解:
首先import所需要的包:
import numpy as np
import pandas as pd
然后读取两张表的数据:
df1 = pd.read_csv('company.csv')
df2 = pd.read_csv('company_data.csv')
对数据做一下清洗,去除含有NAN的行:
df1 = df1.dropna(axis = 0)
df1

df2 = df2.dropna(axis = 0)
df2
将df1中证券代码格式里的#号和补零去掉:
df1['证券代码'] = df1['证券代码'].apply(lambda x: int(str(x[1:])))
df1

将df2中的日期只显示年份:
df2['日期'] = df2['日期'].apply(lambda x: int(str(x[0:4])))
df2

将df1和df2连接, 并去除掉NAN行:
df3 = df1.merge(df2, on=['证券代码','日期'], how='left')
df3 = df3.dropna(axis = 0)
df3
计算收入熵指标:
def myfunc(x):
p = x/x.sum()
res_I = -((p*np.log(p)).sum())
return res_I
res = df3.groupby(['证券代码','日期'])['收入额'].apply(myfunc)
res

将res里的结果变成列:
df4 = res.reset_index()
df4['SHZB_I'] = df4['收入额']
df4 = df4.drop('收入额', 1)
df4
最后将得到的收入熵指标汇总到df1中:
df5 = df1.merge(df4, on=['证券代码','日期'], how='left')
df5

【任务二】组队学习信息表的变换
【题目描述】请把组队学习的队伍信息表变换为如下形态,其中“是否队长”一列取1表示队长,否则为0

【数据下载】链接:https://pan.baidu.com/s/1ses24cTwUCbMx3rvYXaz-Q 34 密码:iz57
解:
首先import所需要的包:
import numpy as np
import pandas as pd
import xlrd
然后读取表的数据:
df1 = pd.read_excel('组队.xlsx')
去掉“所在群”这一列
df1 = df1.drop('所在群', 1)
先处理得到所有队长的表:
df2 = df1[['队伍名称','队长编号','队长_群昵称']]
df2['是否队长'] = 1
df2
然后修改列名,得到和题目要求匹配的队长表:
df3 = df2.rename(columns = {
'队长编号':'编号','队长_群昵称':'昵称'})
df3

筛选队员相关信息的列,并分别重命名编号和昵称,为后续变形做准备:
df4 = df1.drop(['队长编号','队长_群昵称'], 1)
df4 = df4.rename(columns = {
'队员1 编号':'编号_队员1','队员2 编号':'编号_队员2','队员3 编号':'编号_队员3','队员4 编号':'编号_队员4','队员5 编号':'编号_队员5','队员6 编号':'编号_队员6','队员7 编号':'编号_队员7','队员8 编号':'编号_队员8','队员9 编号':'编号_队员9','队员10编号':'编号_队员10'})
df4 = df4.rename(columns = {
'队员_群昵称':'昵称_队员1','队员_群昵称.1':'昵称_队员2','队员_群昵称.2':'昵称_队员3','队员_群昵称.3':'昵称_队员4','队员_群昵称.4':'昵称_队员5','队员_群昵称.5':'昵称_队员6','队员_群昵称.6':'昵称_队员7','队员_群昵称.7':'昵称_队员8','队员_群昵称.8':'昵称_队员9','队员_群昵称.9':'昵称_队员10',})
表太大了,先不截图。
然后对得到的表进行wide_to_long操作:
df5 = pd.wide_to_long(df4,
stubnames=['编号','昵称'],
i = ['队伍名称'],
j='队员',
sep='_',
suffix='.+')
df5
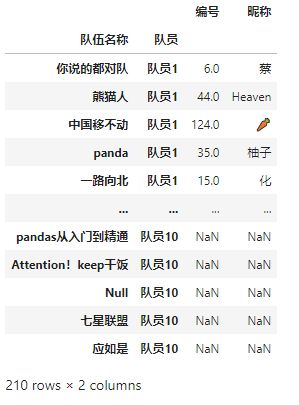
去掉含有NAN的行,并添加“是否队长”列,重设index,删去“队员”列:
df5 = df5.dropna(axis = 0)
df5['是否队长'] = 0
df6 = df5.reset_index()
df6 = df6.drop(['队员'], 1)
df6

将队长和队员的信息拼接:
df7 = pd.concat([df3, df6])
df7
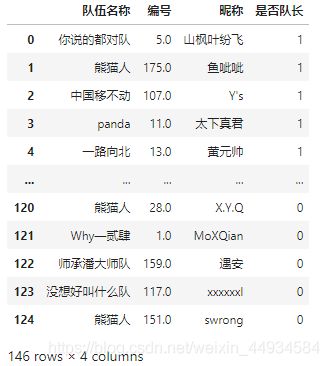
按照题目中的表格样式进行最后的格式调整:
df7 = df7[['是否队长','队伍名称','昵称','编号']]
df7['编号'] = df7['编号'].apply(lambda x: int(x))
df7.sort_values('队伍名称').reset_index().drop(['index'], 1)

【任务三】漂亮国投票情况
【题目描述】两张数据表中分别给出了漂亮国各县(county)的人口数以及大选的投票情况,请解决以下问题:
- 有多少县满足总投票数超过县人口数的一半
- 把州(state)作为行索引,把投票候选人作为列名,列名的顺序按照候选人在全美的总票数由高到低排序,行列对应的元素为该候选人在该州获得的总票数

- 每一个州下设若干县,定义BD在该县的得票率减去CP在该县的得票率为该县的BT指标,若某个州所有县BT指标的中位数大于0,则称该州为BD State,请找出所有的BD State
【数据下载】链接:https://pan.baidu.com/s/182rr3CpstVux2CFdFd_Pcg 32 提取码:q674
解:
1、有多少县满足总投票数超过县人口数的一半
导入需要的包:
import numpy as np
import pandas as pd
读取数据:
df1=pd.read_csv('president_county_candidate.csv')
df2=pd.read_csv('county_population.csv')
计算县的选票总数:
sum1 = df1.groupby(['state','county'])['total_votes'].sum()
sum1
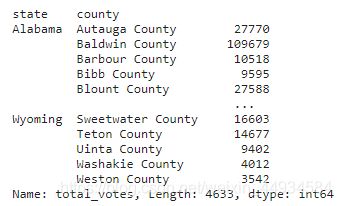
将结果转成dataframe,并连接两表,删去NAN值:
df3 = sum1.reset_index()
df3['US County'] = '.'+df3['county']+', '+df3['state']
df3

df4 = df2.merge(df3, on=['US County'], how='left')
df4 = df4.dropna(axis = 0)
df4

统计满足总投票数超过县人口数的一半的个数:
condition = df4['total_votes'] > (df4['Population']/2)
df4.groupby(condition).count()
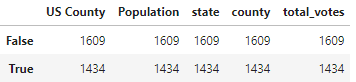
所以是1434个
2.把州(state)作为行索引,把投票候选人作为列名,列名的顺序按照候选人在全美的总票数由高到低排序,行列对应的元素为该候选人在该州获得的总票数
解:
先按照题目要求变形:
df5 = df1.pivot_table(index='state', columns='candidate', values='total_votes',aggfunc = 'sum')
df5.head()

把NaN值用0替换掉
df5 = df5.fillna(0)
df5.head()

类似第一问,先统计每个州候选人得票总数并排序:
sum2 = df1.groupby(['candidate'])['total_votes'].sum().sort_values(ascending = False)
sum2
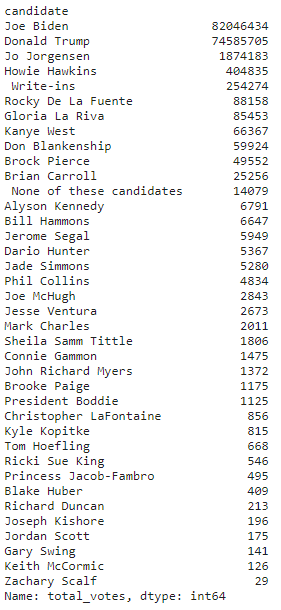
得到列名顺序:
sum2.index

df6 = df5.reindex(columns=sum2.index)
df6

3.每一个州下设若干县,定义BD在该县的得票率减去CP在该县的得票率为该县的BT指标,若某个州所有县BT指标的中位数大于0,则称该州为BD State,请找出所有的BD State
解:
因为比较的都是同一个县比,所以比较得票率和比较得票数在最终结果上一样(被除数相同):
还是和前面一样,先计算他们各自的总票数:
df1['US County'] = '.'+df1['county']+', '+df1['state']
df7 = df1.pivot_table(index='US County', columns='candidate', values='total_votes',aggfunc = 'sum')[['Joe Biden','Donald Trump']]
df7
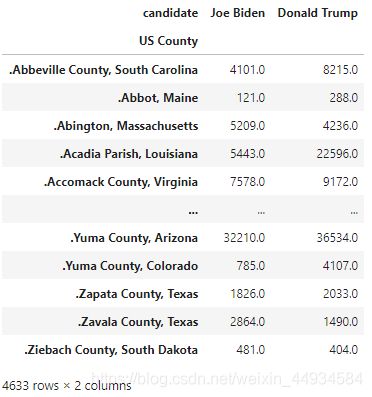
然后得到每个县的BT代替值:
df7['BT'] = df7['Joe Biden']-df7['Donald Trump']
df7

去掉多级索引:
df7 = df7.reset_index(['US County'])
df7

然后将US County拆回去:
df8 = pd.DataFrame((x.split(', ') for x in df7['US County']),columns = ['county','state'])
df8

重新拼起来:
df9 = pd.concat([df7,df8],1)
df9
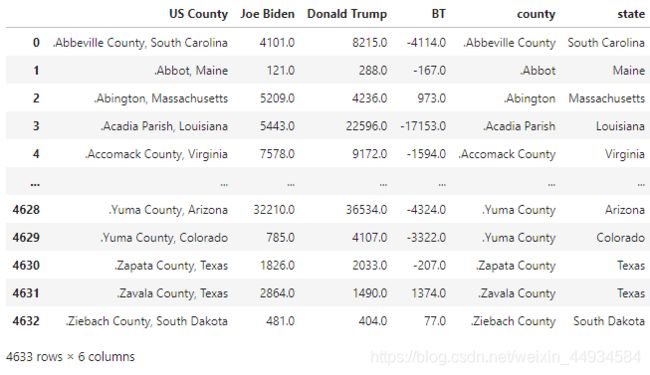
计算各州BT代替值的中位数:
df10 = df9.groupby(['state'])['BT'].median()
df10

与0作比较:
df10>0

从结果中可以得出,结果为True的state是Biden State
即:California, Connecticut, Delaware, District of Columbia, Hawaii, Massachusetts, New Jersey, Rhode Island, Vermont 这9个state。
远昊大佬的参考答案
今天给原题加数据链接的时候,看到远昊大佬更新了参考答案,比我的高级太多太多太多太多。在下方展示出来,以供学习:
第一题
df2['证券代码'] = df2['证券代码'].apply(lambda x:'#%06d'%x)
df2 = df2[df2['证券代码'].isin(df1['证券代码'])]
df2['日期'] = df2['日期'].apply(lambda x: int(x[:4]))
res = df2.groupby(['证券代码', '日期'])['收入额'].apply(lambda x: -((x/x.sum()*np.log(x/x.sum()))).sum()).reset_index()
res = df1.merge(res, how='left', on=['证券代码', '日期']).rename(columns={
'收入额': '收入熵'})
第二题
df = pd.read_excel('组队信息汇总表(Pandas).xlsx')
temp = df.iloc[:,1::2].set_index('队伍名称').T.reset_index(drop=True)
temp['是否队长'] = np.r_[[1], np.zeros(temp.shape[0]-1)].astype('int')
melted = temp.melt(id_vars = '是否队长', value_vars = temp.columns[:-1], var_name = '队伍名称', value_name = '昵称').dropna().reset_index(drop=True)
number = pd.concat([df.iloc[:, 2*(i+1): 2*(i+2)].T.reset_index(drop=True).T for i in range(11)]).rename({
0:'编号', 1:'昵称'}, axis=1).dropna().reset_index(drop=True)
res = melted.merge(number, how='left', on='昵称')
第三题
第一问:
df = pd.read_csv('president_county_candidate.csv')
df_pop = pd.read_csv('county_population.csv')
temp = df_pop['US County'].copy()
df_pop['state'] = temp.apply(lambda x:x.split(', ')[1])
df_pop['county'] = temp.apply(lambda x:x.split(', ')[0][1:])
df_pop = df_pop.drop(['US County'],axis=1)
df = df.merge(df_pop, on=['state','county'],how='left')
df['pop_rate'] = df['total_votes']/df['Population']
res = df.groupby(['state','county'])['pop_rate'].agg(lambda x:x.sum())
(res>0.5).sum()
第二问:
res = df.pivot_table(index='state',columns='candidate',values='total_votes',aggfunc='sum').reindex(df.groupby('candidate')['total_votes'].sum().sort_values(ascending=False).index,axis=1)
第三问:
def select(x):
def inner_select(inner_x):
Total = inner_x.total_votes.sum()
Biden = inner_x.query('candidate=="Joe Biden"').total_votes.sum()
Trump = inner_x.query('candidate=="Donald Trump"').total_votes.sum()
return (Biden-Trump)/Total
res = x.groupby('county')[['candidate','total_votes']].apply(inner_select)
return res.median() > 0
df.groupby('state').filter(select).state.unique()