datax(三)源码阅读之脚本入口datax.py
目录
一、整体流程
二、获取参数解析器解析参数流程
三、构建启动命令流程
四、总结
一、整体流程
我们线上使用datax,一般会通过执行datax.py进行datax任务的启动,比如执行如下命令:python datax.py datax.json
我们聚焦到datax.py的main方法:
if __name__ == "__main__":
printCopyright() // 1.打印版权信息
parser = getOptionParser() // 2.获取参数解析器解析参数
options, args = parser.parse_args(sys.argv[1:])
if options.reader is not None and options.writer is not None:
generateJobConfigTemplate(options.reader,options.writer)
sys.exit(RET_STATE['OK'])
if len(args) != 1:
parser.print_help()
sys.exit(RET_STATE['FAIL'])
startCommand = buildStartCommand(options, args) // 3.构建启动命令
print startCommand
child_process = subprocess.Popen(startCommand, shell=True) // 4.启动java子进程
register_signal()
(stdout, stderr) = child_process.communicate()
sys.exit(child_process.returncode)我们可以看到总体执行流程分为:
1.打印datax版权信息
2.获取参数解析器解析参数
3.构建启动命令
4.启动java子进程。
这边比较核心的流程是获取参数解析器解析参数和构建启动命令,下面我们着重分析这两个过程。
二、获取参数解析器解析参数流程
核心方法是getOptionParser()方法,如下
def getOptionParser():
usage = "usage: %prog [options] job-url-or-path"
parser = OptionParser(usage=usage)
prodEnvOptionGroup = OptionGroup(parser, "Product Env Options",
"Normal user use these options to set jvm parameters, job runtime mode etc. "
"Make sure these options can be used in Product Env.")
prodEnvOptionGroup.add_option("-j", "--jvm", metavar="", dest="jvmParameters", action="store",
default=DEFAULT_JVM, help="Set jvm parameters if necessary.")
prodEnvOptionGroup.add_option("--jobid", metavar="", dest="jobid", action="store", default="-1",
help="Set job unique id when running by Distribute/Local Mode.")
prodEnvOptionGroup.add_option("-m", "--mode", metavar="",
action="store", default="standalone",
help="Set job runtime mode such as: standalone, local, distribute. "
"Default mode is standalone.")
prodEnvOptionGroup.add_option("-p", "--params", metavar="",
action="store", dest="params",
help='Set job parameter, eg: the source tableName you want to set it by command, '
'then you can use like this: -p"-DtableName=your-table-name", '
'if you have mutiple parameters: -p"-DtableName=your-table-name -DcolumnName=your-column-name".'
'Note: you should config in you job tableName with ${tableName}.')
prodEnvOptionGroup.add_option("-r", "--reader", metavar="",
action="store", dest="reader",type="string",
help='View job config[reader] template, eg: mysqlreader,streamreader')
prodEnvOptionGroup.add_option("-w", "--writer", metavar="",
action="store", dest="writer",type="string",
help='View job config[writer] template, eg: mysqlwriter,streamwriter')
parser.add_option_group(prodEnvOptionGroup)
devEnvOptionGroup = OptionGroup(parser, "Develop/Debug Options",
"Developer use these options to trace more details of DataX.")
devEnvOptionGroup.add_option("-d", "--debug", dest="remoteDebug", action="store_true",
help="Set to remote debug mode.")
devEnvOptionGroup.add_option("--loglevel", metavar="", dest="loglevel", action="store",
default="info", help="Set log level such as: debug, info, all etc.")
parser.add_option_group(devEnvOptionGroup)
return parser 可以看到这边使用了python的OptionParser库进行了参数的构建。
关于OptionParser库这里不做说明,可以参考这篇博客:Python optionParser模块的使用方法
第一行的usage定义了datax.py的使用姿势如下:Usage: datax.py [options] job-url-or-path, 其中[options]表示可选参数,我们下面再说;job-url-or-path表示datax的执行json文件的路径,是datax.py的唯一必填参数
后面的代码就是定义了datax.py的可选参数,分成了如下两类:
1、生产环境参数
①-j 或者 --jvm:jvm参数设置
②--jobid : job唯一id,仅当job的运行模式为Distribute或者Local时必填
③-m 或者 --mode:job运行模式:standalone / local / distribute ,默认为standalone(ps:一般就是standalone模式,生产环境的话可以参考上一篇文章,其实就是standalone模式 + azkaban调度)
④-p 或者 --params : 为datax的json文件设置的动态参数,比如datax的json文件中mysqlReader的table需要外部传入,那就可以在json文件里设置${tableName},然后datax.py通过-p"-DtableName=your-table-name"进行动态设置
⑤-r 或者 --reader: 获取datax的执行的json模板,这里设置具体的reader,比如mysqlReader
⑥-w 或者 --writer: 获取datax的执行的json模板,这里设置具体的writer,比如streamWriter
注意:-r 和 -w需要同时设置,不然不会打印模板,而是执行job,执行如下图
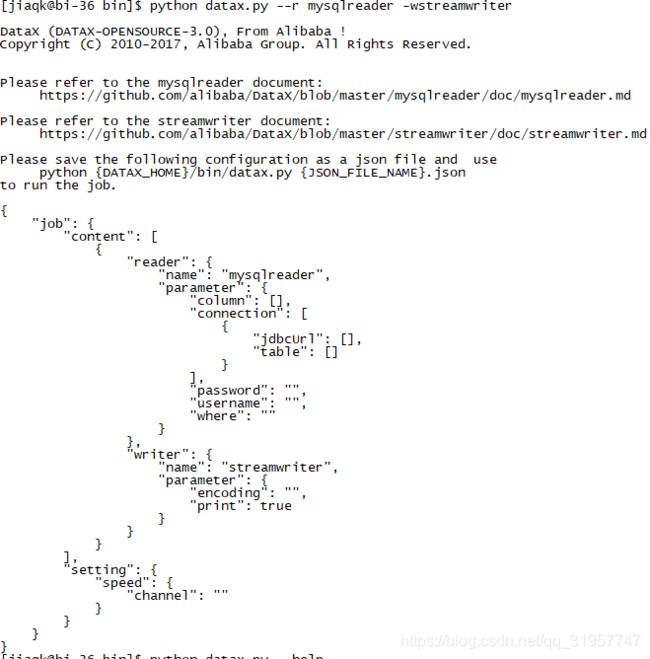
2、开发环境参数
①-d 或者 --debug : 开启远程debug模式
②--loglevel :设置日志级别,默认是INFO级别
关于远程debug,可以参考下面的博客:
① Intellij IDEA远程debug教程实战和要点总结
② datax debug远程调试
三、构建启动命令流程
构建启动命令的核心逻辑主要在buildStartCommand()方法,如下
// 全局变量
DATAX_HOME = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
DATAX_VERSION = 'DATAX-OPENSOURCE-3.0'
if isWindows():
codecs.register(lambda name: name == 'cp65001' and codecs.lookup('utf-8') or None)
CLASS_PATH = ("%s/lib/*") % (DATAX_HOME)
else:
CLASS_PATH = ("%s/lib/*:.") % (DATAX_HOME)
LOGBACK_FILE = ("%s/conf/logback.xml") % (DATAX_HOME)
DEFAULT_JVM = "-Xms1g -Xmx1g -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=%s/log" % (DATAX_HOME)
DEFAULT_PROPERTY_CONF = "-Dfile.encoding=UTF-8 -Dlogback.statusListenerClass=ch.qos.logback.core.status.NopStatusListener -Djava.security.egd=file:///dev/urandom -Ddatax.home=%s -Dlogback.configurationFile=%s" % (
DATAX_HOME, LOGBACK_FILE)
ENGINE_COMMAND = "java -server ${jvm} %s -classpath %s ${params} com.alibaba.datax.core.Engine -mode ${mode} -jobid ${jobid} -job ${job}" % (
DEFAULT_PROPERTY_CONF, CLASS_PATH)
REMOTE_DEBUG_CONFIG = "-Xdebug -Xrunjdwp:transport=dt_socket,server=y,address=9999"
def buildStartCommand(options, args):
commandMap = {}
tempJVMCommand = DEFAULT_JVM // 1. 处理jvm参数
if options.jvmParameters: // 1.1 设置jvm参数
tempJVMCommand = tempJVMCommand + " " + options.jvmParameters
if options.remoteDebug: // 1.2 设置远程debug
tempJVMCommand = tempJVMCommand + " " + REMOTE_DEBUG_CONFIG
print 'local ip: ', getLocalIp()
if options.loglevel: // 1.3 设置日志级别
tempJVMCommand = tempJVMCommand + " " + ("-Dloglevel=%s" % (options.loglevel))
if options.mode:
commandMap["mode"] = options.mode
# jobResource 可能是 URL,也可能是本地文件路径(相对,绝对)
jobResource = args[0] // 2.处理datax的执行json路径参数
if not isUrl(jobResource): // 2.1 执行json路径支持http url
jobResource = os.path.abspath(jobResource) // 2.2 执行json路径本地路径统一为绝对路径
if jobResource.lower().startswith("file://"):
jobResource = jobResource[len("file://"):]
// 3. 处理job的参数
jobParams = ("-Dlog.file.name=%s") % (jobResource[-20:].replace('/', '_').replace('.', '_')) // 3.1 处理打印日志的文件名
if options.params:
jobParams = jobParams + " " + options.params // 3.1 处理datax执行json的动态参数
if options.jobid:
commandMap["jobid"] = options.jobid
commandMap["jvm"] = tempJVMCommand
commandMap["params"] = jobParams
commandMap["job"] = jobResource
return Template(ENGINE_COMMAND).substitute(**commandMap) // 4. 组装java命令主要流程就像注释里写的那样:
1.处理jvm参数(jvm参数、远程debug参数、日志级别参数)
2.处理datax执行json路径参数(支持http url、本地绝对路径和本地相对路径,其中相对路径会转化为绝对路径进行操作)
3.处理job的参数(job执行日志的文件名、job执行json的动态参数)
4.组装java命令
四、总结
根据上面的分析,datax的入口脚本datax.py主要进行了下面的处理流程:
1.打印datax版权信息
2.获取参数解析器解析参数
2.1 定义脚本必填参数——datax执行json文件的路径
2.2 定义脚本选填参数——生产环境参数和开发环境参数
3.构建启动命令
3.1.处理jvm参数(jvm参数、远程debug参数、日志级别参数)
3.2.处理datax执行json路径参数(支持http url、本地绝对路径和本地相对路径,其中相对路径会转化为绝对路径进行操作)
3.3.处理job的参数(job执行日志的文件名、job执行json的动态参数)
3.4.组装java命令
4.启动java子进程。